编者按:
自然语言处理的发展进化带来了新的热潮与研究问题。基于一系列领先的科研成果,微软亚洲研究院自然语言计算组将陆续推出一组文章,介绍机器推理 (Machine Reasoning) 在常识问答、事实检测、自然语言推理、视觉常识推理、视觉问答、文档级问答等任务上的最新方法和进展。此前我们介绍了机器推理的系列概览和常识问答中的应用,本文是该系列的第二篇文章。
推理是自然语言处理领域非常重要且具有挑战性的任务,其目的是使用已有的知识和推断技术对未见过的输入信息作出判断 (generate outputs to unseen inputs by manipulating existing knowledge with inference techniques) [1]。在本文中,我们以事实检测为应用,介绍机器推理在事实检测任务上的最新方法和进展。
互联网为个人和机构提供了将信息迅速扩散、分享的途径,但同时也给了居心不良的人散播不实信息的机会。虚假的信息对社会有很多负面影响,包括股价波动、总统大选等[2]。有学者指出,虚假的消息传播甚至要比真实的消息传播面更广[3]。因此,检测网络上的不实新闻具有重要的社会意义。在本文中,我们研究如何使用自动化的方法检测互联网上的虚假信息。该方法可以辅助新闻编辑在发布新闻之前自动地检测新闻中包含的不实信息。
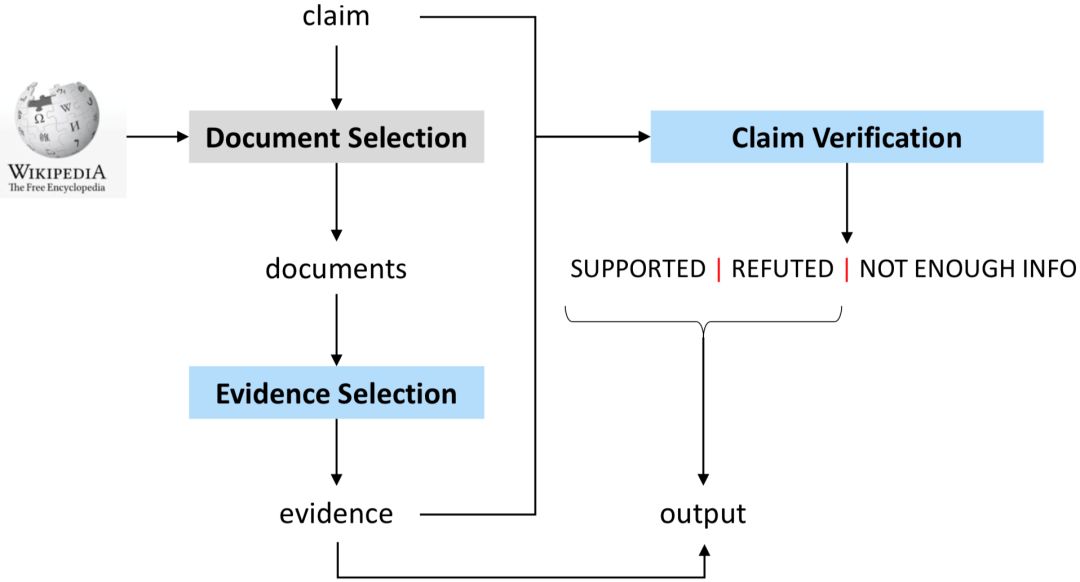
我们以 FEVER (Fact Extraction and VERification) [4] 评测为例开展事实检测的研究,该数据是目前规模最大的事实检测公开数据集。该任务定义如下:给定一个自然语言陈述(claim,通常为一句话),要求从 Wikipedia 的文档中寻找多句话作为证据(evidence),利用该 evidence 去判断该陈述的真伪(SUPPORTED/REFUTED)。如果 evidence 的信息不足以支撑判断陈述的真伪,则输出(NOT ENOUGH INFO)。
FEVER 数据包含了 185,445 个样例,每个陈述都具有人工标注的标签,同时对于标签类别是 SUPPORTED 或 REFUTED 的样例还标注了正确的 evidence。数据样例如图1。我们在图中高亮了关键的信息,从该样例可以看出,每个单独的 evidence 都无法支撑最终的结果,判断陈述的真伪需要深入地理解各 evidence 句子之间的逻辑结构,并有效地利用该信息进行推断。
![]()
图1:
FEVER 数据样例
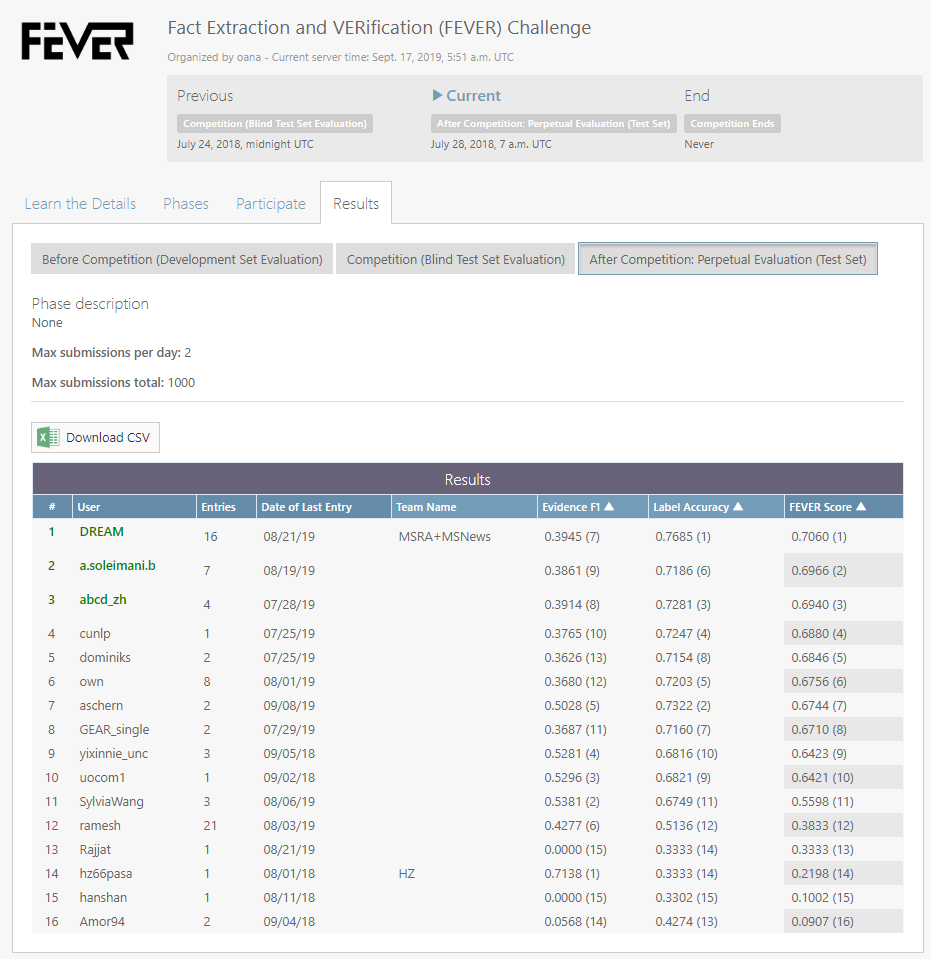
该任务的评测指标有两项:第一个评测指标是陈述分类的精确率(accuracy),第二个评测是 FEVER score,只有陈述分类和 evidence 选择均正确才算正确。
该评测任务在 Codalab 有一个官方的排行榜,测试集的标注信息不对外开放,所以各参评者需要提交各自的系统到官方平台进行比较。目前,我们的系统 DREAM 在两项评测指标中均取得了目前 state-of-the-art 的结果。
Codalab 官方排行榜:
https://competitions.codalab.org/competitions/18814#results
图2:FEVER 排行榜 (2019.09.18)
DREAM 系统的框架图如图3所示,主要包括三个模块:篇章选择模块、知识选择模块和陈述分类模块。其中,篇章选择模块的目的是从 Wikipedia 中选择与当前陈述相关的文章,知识选择模块则从已选中的篇章内,选择与当前陈述相关的多个句子,这些句子集合作为 evidence,与陈述一起作为最后陈述分类模块的输入。在本文中,我们将重点介绍陈述分类模块,即基于图的推理模型。篇章选择模块和知识选择模块的细节,请参照我们的论文“Reasoning Over Semantic-Level Graph for Fact Checking”[5]。
图3:DREAM 系统框架图
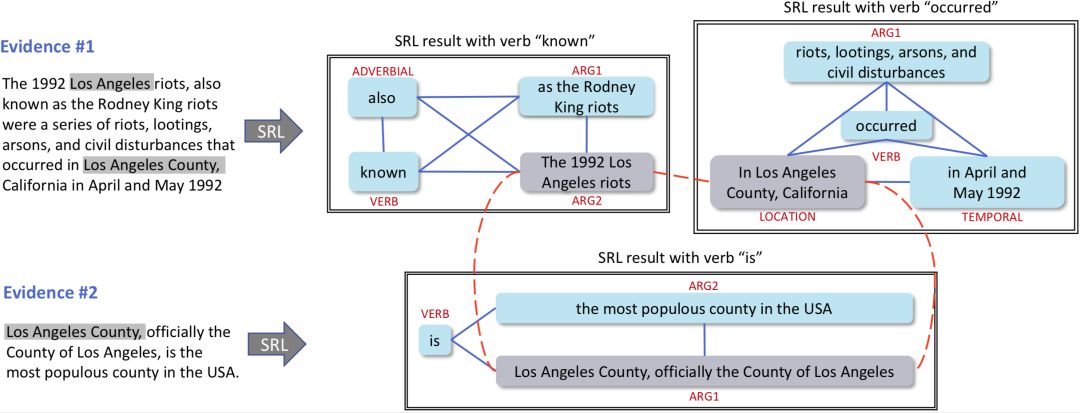
陈述分类(claim classification)模块的输入是陈述(claim)和多个 evidence 句子,输出是 SUPPORTED/REFUTED/NOT ENOUGH INFO 三个类别中的一个。通过图1我们分析得到:陈述分类的两大挑战是:(1)如何理解多个 evidence 句子之间的逻辑结构;(2)如何在理解的基础上对信息推理和整合做出预测。已有的工作通常把多个 evidence 连接成一个字符串、或分别计算每个 evidence 句子的特征再进行融合,缺乏对多个 evidence 句子的语义理解。在本文中,我们利用基于语义角色标注(semantic role labeling)的浅层语义分析器把多个 evidence 句子解析成一个语义图,并在图上推断陈述的类别。我们的建图有以下两个标注:(1)把每个 SRL 抽取的 triple 中的各个元素全连接;(2)把多个 triple 中的固定类型节点(包括argument、location和temporal)根据字符相似度建立连接。图1中 evidence 句子构建的图如图4所示。我们使用同样的方式把每个陈述也表示为一个图。
图4:基于 SRL 的图样例
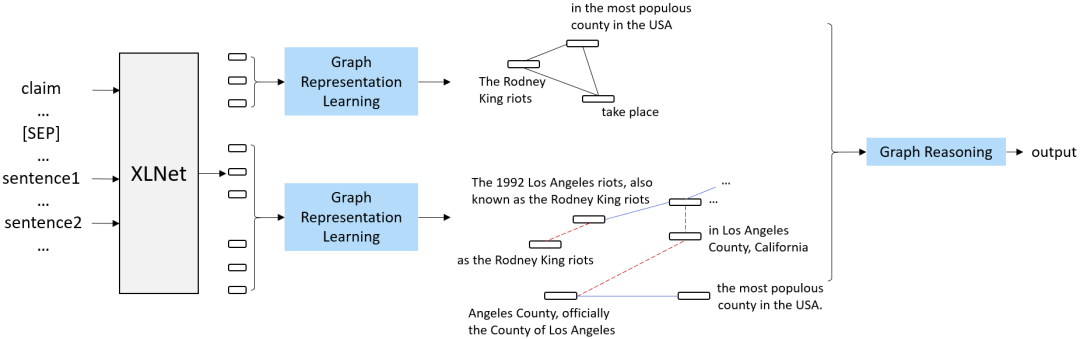
在构建好了陈述的图和 evidence 的图之后,我们提出了基于图的推理模型,该模型在图结构上对陈述和 evidence 匹配。具体地,我们提出了两个基于图的语义运算模块,即基于图的上下文词向量模块和基于图的语义推理模块。其中,第一个模块计算每个词语的上下文相关的表示(contextual word representation),第二个模块在第一个模块的结果基础上计算图中每个节点的表示以及把两个图进行匹配。
我们的方法建立在 XLNet 的基础上,因此第一个模块的一种最简单的实现方式就是把所有 evidence 句子连接,但这样会使出现在不同句子中、语义逻辑上很近的词语距离较远。于是,我们利用生成的图结构重新定义了词语之间的相关距离,在计算词语的上下文相关的表示时融入更多的语义结构信息。
第二个模块,即基于图的语义推理模块会首先计算图中每个节点的表示,我们使用节点内部词语表示的平均来进行初始化;随后在图上使用图卷积网络(GCN)使得图中每个节点都可以获得邻居节点的信息;最后,在获得了两个图中每个节点的表示之后,我们使用注意力(attention)机制基于两个图进行推理,做出最后的判断。
图5:基于图的推理模型
本文介绍了机器推理在事实检测任务中的应用,提出了融合语义结构信息的上下文词向量学习模块和基于图的语义推理模块,我们提出的推理方法在 FEVER 上取得了 state-of-the-art 的结果。
[1] Ming Zhou, Nan Duan, Shujie Liu, Heung-Yeung Shum. Progress in Neural NLP: Modeling, Learning and Reasoning. Accepted by Engineering, 2019.
[2] Faris, R.; Roberts, H.; Etling, B.; Bourassa, N.; Zuckerman, E.; and Benkler, Y. 2017. Partisanship, Propaganda, and Disinformation: Online Media and the 2016 U.S. Presidential Election.
[3] Vosoughi, S.; Roy, D.; and Aral, S. 2018. The spread of trueand false news online. Science 359(6380):1146–1151.
[4] Vlachos, A., and Riedel, S. 2014. Fact checking: Task def-inition and dataset construction. InProceedings of the ACL 2014 Workshop on Language Technologies and Computational Social Science, 18–22.
[5] Wanjun Zhong, Jingjing Xu, Duyu Tang, Zenan Xu, Nan Duan, Ming Zhou, Jiahai Wang, Jian Yin. Reasoning Over Semantic-Level Graph for Fact Checking. arXiv:1909.03745, 2019
本文转自“微软研究院AI头条”,作者:钟宛君、唐都钰、段楠、周明