带你读论文 | 数据到文本生成的近期优质论文,我们为你挑选了这六篇
编者按:在《如何让人工智能学会用数据说话》一文中,我们曾经为大家介绍过结构化数据到文本生成的技术方法、商业应用以及相关数据集等方面内容。今天,我们邀请微软亚洲研究院知识计算组的研究员解读该领域中有关数据到文本生成的近期论文。
数据到文本生成任务以结构化数据(例如一个商品的属性列表或一场比赛的统计数据)作为输入,旨在自动生成流畅的、贴近事实的文本以描述输入数据。数据到文本生成的主流方法包括基于规则和模板的方法以及基于神经网络的方法。
现阶段,基于规则和模板的方法仍然是相关应用中最主流的做法,因为这类方法具备明显的可解释性与可控制性,更容易确保所输出文本内容的正确性。然而,这种方法也存在局限性——优质模板的抽取离不开人工特征工程或者规则干预;生成的内容在多样性、流畅度以及连贯性方面往往会存在问题。
与之相反,基于神经网络的模型主要依靠数据驱动,不需要太多人工干预,也很容易产生丰富又流畅的文字描述,但使用者往往无法直接操控内容生成,难以确保所输出的文本内容同输入数据中的信息吻合,所以目前在真实场景下目前并不具备足够的实用价值。由于神经网络表示学习近年来的火热,以及神经网络文本生成模型存在明显的不足和改进空间,近期学术研究中探索神经网络生成模型的工作相对更多。
数据到文本生成任务在不同场景设定下的进展和挑战不尽相同,近两年也有很多工作试图从不同角度开展研究。在本文中,我们将带大家一起选读若干近期相关研究工作。这些工作的研究动机相对明确,直接尝试应对当前方法所面临的重要挑战,为后续进一步研究提供了一些可行的方向或角度。
Challenges in Data-to-document Generation
由Sasha Rush领衔的哈佛大学自然语言处理研究组是近年来研究神经网络文本生成模型最活跃的团队之一。该团队在EMNLP 2017上发表了题为Challenges in Data-to-document Generation的工作(Wiseman et al., 2017),包含了作者对神经网络数据到文本生成模型的阶段性总结与反思。作者采集了大量NBA篮球比赛统计数据以及对应的文字战报,以此发布了新的数据集RotoWire。与《如何让人工智能学会用数据说话》一文中介绍过的维基百科传记数据集WikiBio以及下文会提及的E2E NLG Challenge评测数据集相比,RotoWire中的输入数据更丰富,文本长度更长,通常每篇描述包含5-7句话;并且文字中直接提及或通过不同措辞蕴含的部分信息,需要从具体的数值、时间等信息推断得出,无法从输入的表格数据中直接获取。例如,输入数据中并没有直接标示比赛的获胜球队,只列出了交战双方比分,而文字内诸如“亚特兰大老鹰队以103-95击败迈阿密热队”中的“击败”一词,需要生成模型能够准确捕捉“比分更高的球队胜出”这样的对应关系,对当前高度依赖连续向量表示的神经网络方法而言颇具挑战。
作者在该数据集上进行的实验表明,常见神经网络文本生成模型所输出的文本虽然看似流畅,但往往存在多种逻辑错误,比如混淆了不同信息的输出位置、无中生有(hallucination,即模型在所生成的文本中“自行脑补”了输入数据中并没有蕴含的信息)等等,详见图1。这些问题在进行长文本生成时显得更为严重,导致模型输出的准确度远不如基于模板的文本生成系统。

图1 神经网络生成模型输出示例,蓝色/红色部分分别表示同输入数据吻合/不吻合的内容(图片来自Wiseman et al., 2017 )
论文中也指出,常用的自动化评测指标(如BLEU)并不足以评测文本生成的质量。这些指标侧重于评测文本的流畅性,但忽视了文本的语义和逻辑信息。自动指标的局限性其实近年也在自然语言生成领域被反复提及,有大量工作指出它们同人工评价的统计相关性其实很低(如Novikova et al., 2017、Chaganty et al., 2018、Reiter, 2018等)。在这种情况下,一方面有针对性地设计人工评测不可或缺,另一方面也需要其它更合理的自动指标来作辅助。因此,作者也给出了一种抽取式评价(extractive evaluation)方法,从生成的文本中抽取事实并与输入数据进行比对,在一定程度上可以弥补传统自动化评测指标(如BLEU)的不足。
A Deep Ensemble Model with Slot Alignment for Sequence-to-Sequence Natural Language Generation
自然语言生成领域近年最著名的公开评测当属E2E NLG Challenge。该评测于2017年启动,在2018年上半年公布了评测结果,并在自然语言生成专业会议INLG 2018上进行了总结 (Dušek et al., 2018; 2019)。该评测收集了上万条配对的餐馆描述及语义表示数据(如图2所示)。参赛系统需要将给定的语义表示(meaning representation, MR),即不同的属性与值,用自然语言(natural language, NL)描述出来。评测数据集侧重于反映诸如开放词表、语义控制、表达多样性等几种数据到文本生成任务的挑战。
E2E NLG Challenge 链接:http://www.macs.hw.ac.uk/InteractionLab/E2E/

图2 E2E评测任务数据示例(本例来自评测官网)
E2E NLG Challenge评测最终的获胜系统为加州大学圣克鲁斯分校研究团队的Slug2Slug系统,该系统在自动评测和人工评测中均取得较好的成绩。该团队将系统描述以论文A Deep Ensemble Model with Slot Alignment for Sequence-to-Sequence Natural Language Generation发表在NAACL 2018 (Juraska et al., 2018)。在这篇论文中,作者提出一个集成(ensemble)的神经文本生成框架,其中参与集成的个体模型均为常用的序列到序列(sequence-to-sequence)模型。其编码器部分采用了最为常用的LSTM-RNN或CNN。而在每个模型解码输出多条候选文本后,系统还对这些候选文本进行重排序,排序时考虑了文本中所提及事实与输入数据的匹配情况。本文在方法上的核心贡献是作者自行构建的一套启发式的属性槽对齐器(slot aligner),用来剔除训练数据中一些没有被对应文本所提及的属性值,在一定程度上实现了数据去噪;作者还根据候选文本同数据属性槽的对齐结果设计了重排序准则。实验表明,系统虽然无法在所有自动评测指标中均取得领先,但可以使得模型在各个指标上都更加稳定、输出错误更少的文本。
由于面向E2E评测,作者也在文中总结了不少实用技巧,对准备上手相关任务的读者而言值得参考。比如,在预处理时的去词汇化(delexicalization)操作中,作者不仅简单地进行匹配和替换,还在替换时保留了更多的上下文信息(如单复数、时态等和衔接等信息)。另外,论文还讨论了文本生成中数据增广(data augmentation)的实用做法,以及为了获得更自然的生成文本对训练数据进行选择的尝试。
本文的核心操作是建立结构化数据同文本信息的对齐。除了直接根据领域知识设计启发式对齐方法以外,也有同期的其它工作试图在规模更大、干扰更多的Wikibio维基百科数据集上实现自动对齐(Perez-Beltrachini and Lapata, 2018)。类似多示例学习(multiple-instance learning)的思想,原理上可以将与文本共现的属性集视作弱监督标记来导出对齐信息。
End-to-End Content and Plan Selection for Data-to-Text Generation
这篇论文是哈佛大学自然语言处理组发表在INLG 2018的工作(Gehrmann et al., 2018)。文中提出的方法在经典序列到序列模型的基础上,引入多个解码器,并通过隐变量因子来指定最终文本是由哪个解码器所生成。这样做的原因是,在文本生成中,同一个意图往往有多种表达方法,只使用单个解码器很难对多种不同的表达方式进行拟合。而通过设置多个子模型,可以让每个子模型只负责拟合特定表达风格的数据,从而改进学习效果。
值得一提的是,该论文所采用的基础模型整合了常用的注意力(attention)机制、拷贝(copy)机制、覆盖(coverage)机制和文本长度控制等,是一个较为先进和完备的基础模型。另外,该论文也在 E2E NLG Challenge 数据集上对这些主要组件的影响进行了实验评测。
Learning Neural Templates for Text Generation
虽然端到端(end-to-end)的方法在数据到文本生成上取得了一定的成果,但其不可解释性和不可控性一直广为诟病。因此,近期也出现了一些将端到端方法和传统基于规则和模板的方法进行融合的模型。哈佛大学自然语言处理组的EMNLP 2018论文Learning Neural Templates for Text Generation就是其中较有代表性的工作之一 (Wiseman et al., 2018)。为了学习抽取和使用模板,作者采用适合片段建模的隐半马尔可夫模型(hidden semi-markov model, HSMM)对文本进行建模,并用神经网络实现其中所有概率项的参数化。在完成模型训练后,可以利用Viterbi算法推断出隐状态序列,并将其获取为模板,因此可以很方便地对模板进行控制并利用模板引导下一步的文本生成。在E2E NLG Challenge数据和WikiBio数据上的实验结果表明,该方法可以取得和端到端神经模型可比的性能,但是更具可解释性和可控性。
同期也有其它工作尝试先产生模板、再填写属性值的过程(Li and Wan, 2018)。借助边际损失函数拉大正确填充结果与错误填充结果的模型打分差距,可以在一定程度上缓解输出文本语义不正确的问题。
Operation-guided Neural Networks for High Fidelity Data-To-Text Generation
这篇论文(Nie et al., 2018)是微软亚洲研究院知识计算组对改进神经模型生成文本正确性的一个尝试。在前文中我们也提过,很多时候训练数据中,文本和结构化数据无法一一对齐,这对结构化数据到文本生成提出很大的挑战。例如句子 “Hawks edges the Heat with 95-94”,其中队名Hawks、Heat和比分95、94均可以直接从输入数据中获取,而描述比赛结果的edges (“险胜”)是基于两队比分极其接近的事实而得出,现实中的结构化数据往往不会直接包含此类细粒度事实。进一步调研发现,在本论文收集的ESPN dataset数据集、前文所述RotoWire数据集以及维基百科人物数据集WikiBio的文本中,分别有29.1%、11.7%和7.4%的事实虽然不能从输入数据中直接获取,但可以通过对输入数据进行运算而获得。基于这些观察,论文提出了基于运算指引的神经文本生成模型。具体来说,该模型预先执行好若干种预定义的运算操作,在进行文本生成时,解码器从输入数据和运行结果中利用门限(gating)机制动态采用所使用的信息来源。另外,为了缓解数值数据的稀疏性问题,文中还将运算结果中的数值进行自动分段处理,使得模型更容易建立运算结果同词汇选择的联系。
论文还发布了ESPN数据集,该数据集包含2006-2017年1.5万场NBA比赛的结果和对应的新闻标题。与RotoWire相比,该数据集文本长度更短,且文本中仅有约8.2%的内容没有蕴含在输入数据信息内 (既无法从输入数据直接获取,也无法通过其他操作推断得到的部分)。
Learning Latent Semantic Annotations for Grounding Natural Language to Structured Data
这篇论文 (Qin et al., 2018)是微软亚洲研究院知识计算组在EMNLP 2018会议发表的另一篇相关工作,出发点与前一篇论文类似,但侧重于细粒度显式建立起文本与输入数据之间的关系,从而得到可解释、可控制的模型。不同词汇或者短语的使用同输入数据里不同部分的信息有关,词汇有时会直接取自数据中的字符串,有时则会因为属性变量或者数值变量的不同取值而产生变化。由于对数值的表达在一定程度上涉及常识获取与推理,关于这一部分的研究其实相当贫乏。
文中将建立对应关系的过程用序列标注的方式来实现,如图3所示。整个方法框架将表征词汇语义的标注视为隐变量,建立隐半马尔可夫模型(HSMM)进行学习与推断。模型中对于字符串变量、属性变量、数值变量等不同类型之间的对应关系分别采用了不同的概率模型来建模,而无法对应到输入数据的文字则统一标注为特定的空标记(NULL)。同经典机器翻译方法中的统计对齐模型类似,最终的对齐结果中很容易出现“垃圾收集”(garbage collection)效应,在文中的任务设定下表现为:有部分本应打上空标记(NULL)的文字会被对应到几乎不被提及的数据单元上。为缓解这一问题,可以利用后验正则化(posterior regularization)技术,从统计上约束空标记的比例使之不低于特定值,最后能够使得对齐结果得到大幅改善。
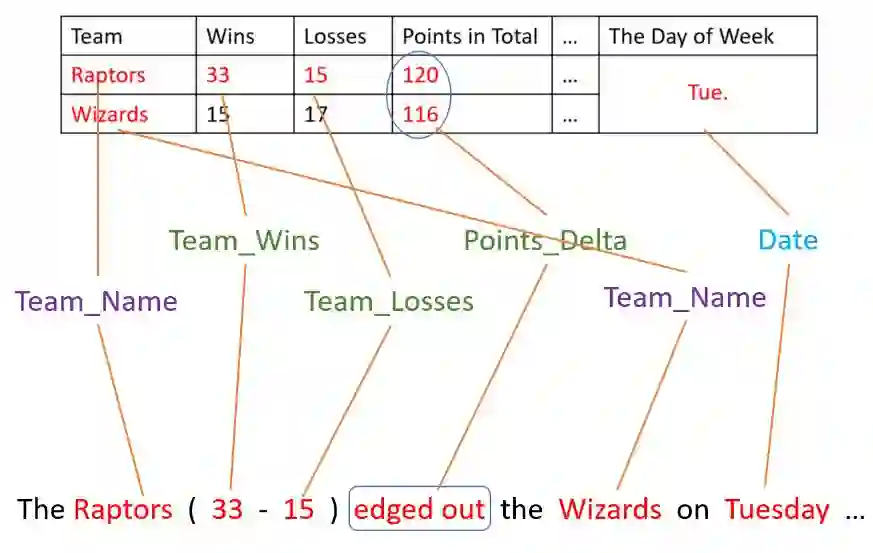
图3 自动推断文本中各部分词汇同输入数据项的对应关系
模型推断得到的概率可以用来为特定的数据信息获取多样的词汇表达,而对齐结果本身也可以据此为自然语言生成提供丰富的规则和模板。这样,在保证了可解释性以及可控性的基础上,整个框架可以自动从平行数据中获取丰富的文字表达模式。
数据到文本生成任务在近几年得到了广泛关注,整个领域也在可控性、正确性、多样性等问题上取得了一些进展。不过,这些问题目前还没有得到完全彻底的解决,在基于神经网络的文本生成模型中尤其如此,这一现状也为后续的相关研究工作留出了巨大的前进空间。在目前的工程实践中,尤其是对于正确性和可控性要求比较高的场景,我们仍然建议采用基于模板或规则的方法,而模板与规则也可以由系统性的从平行数据中获取得到。文本生成是让计算机从能听会看到能言善道的必要技术之一。在生成模型的设计、训练语料的构建、评价方法的创新、应用场景的适配等等议题都有很大的研究发展空间。作者也希望借由此文启发更多的研究人员关注和投入这个领域,一起为数据到文本生成后续的技术发展贡献力量。
参考文献
• Chaganty, et al. "The price of debiasing automatic metrics in natural language evalaution"
• Dušek, et al. "Findings of the E2E NLG challenge"
• Dušek, et al. "Evaluating the State-of-the-Art of End-to-End Natural Language Generation: The E2E NLG Challenge"
• Gehrmann, et al. "End-to-End Content and Plan Selection for Data-to-Text Generation"
• Juraska, et al. "A Deep Ensemble Model with Slot Alignment for Sequence-to-Sequence Natural Language Generation"
• Li, Liunian, et al. "Point Precisely: Towards Ensuring the Precision of Data in Generated Texts Using Delayed Copy Mechanism"
• Nie, Feng, et al. "Operation-guided Neural Networks for High Fidelity Data-To-Text Generation"
• Novikova, et al. "Why We Need New Evaluation Metrics for NLG"
• Perez-Beltrachini, Laura, and Mirella Lapata. "Bootstrapping Generators from Noisy Data"
• Qin, Guanghui, et al. "Learning Latent Semantic Annotations for Grounding Natural Language to Structured Data"
• Reiter, et al. "A Structured Review of the Validity of BLEU"
• Wiseman, et al. "Challenges in Data-to-Document Generation"
• Wiseman, et al. "Learning Neural Templates for Text Generation"
扫描下方二维码或点击阅读原文,即可下载文中提到的所有论文。

作者简介
王锦鹏,微软亚洲研究院知识计算组研究员,主要从事多模态知识挖掘、自然语言处理等领域的研究工作。至今为止,他在相关领域的顶级会议上已发表10余篇论文,并担任ACL、AAAI等国际会议的评审委员。
姚金戈,微软亚洲研究院知识计算组副研究员,目前主要致力于探索自然语言理解与生成中的若干重要问题以及在工程实践中的应用与适配。
知识计算组简介
知识计算组致力于通过知识发现、数据挖掘与计算来理解和服务这个世界。研究组聚集了包括数据挖掘与计算、机器学习、自然语言处理、信息检索和社会计算等领域的多学科研究员,主要从事如下研究方向:实体链接、搜索和知识挖掘与计算,基于结构化数据的文本生成,服务于真实世界的语义计算框架应用,基于大规模行为数据的用户理解。十年来,该组成员的研究成果对微软的重要产品产生了影响,包括必应搜索、微软学术搜索、微软认知服务、微软Office等。
知识计算组现招聘实习生,工作内容涉及机器学习、自然语言处理和计算机视觉等领域,工程和研究均可,根据个人兴趣和能力确定工作内容。要求编程能力较强;有一定的沟通能力,有责任心;对机器学习、自然语言处理、人工智能有热情和兴趣;高质量的完成工作;半年以上实习期。
感兴趣的同学可下载并填写申请表(申请表链接:http://www.msra.cn/zh-cn/jobs/interns/internship_application_form.xlsx),并将其与完整的中英文简历(PDF/Word/Txt/Html形式)一同发送至:MSRAih@microsoft.com
你也许还想看:
● “可解释性”OR“准确性”?压缩深度神经网络模型让你两者兼得
● 干货 | NIPS 2017线上分享:利用价值网络改进神经机器翻译

感谢你关注“微软研究院AI头条”,我们期待你的留言和投稿,共建交流平台。来稿请寄:msraai@microsoft.com。




