通用的图像-文本语言表征学习:多模态预训练模型 UNITER

分享嘉宾:李琳婕 微软 研究工程师
编辑整理:付一韬
内容来源:将门线上直播177期
出品平台:将门、DataFun
注:欢迎转载,转载请留言。
-
背景 -
UNITER 训练数据集 -
UNITER 预训练模型 -
UNITER 下游任务组成 -
结论
▌背景
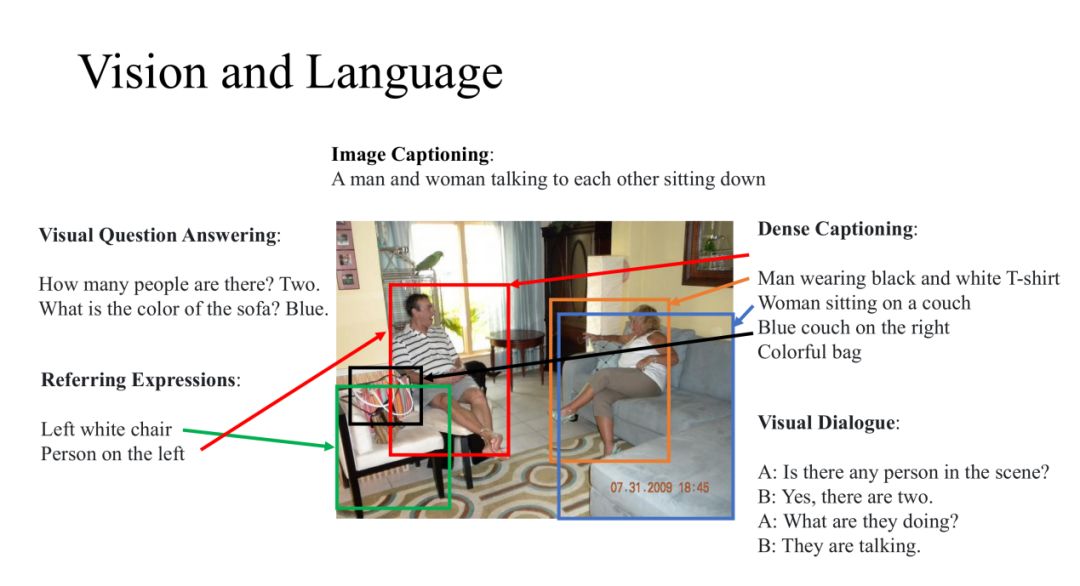
我们的工作都是在研究 Vision 和 Language,这些任务需要的模型不仅要对图像或者其他视觉输入进行识别,而且对自然语言也要有很好的理解。这些研究都是在图像和自然语言处理的交界处,所以近年来涌现了很多有意思的新方向。例如:
Image Captioning:给定一张图片,我们可以概括图片内容;
Visual Question Answering:对这张图片进行提问,让模型回答相关的问题;
Dense Captioning:我们也会对图片的细节感兴趣,针对图片的特定区域进行描述;
Referring Expressions:给定一个描述语句,并定位该语句的指定区域;
Visual Dialogue:针对图片还可以进行多轮问答。
▌UNITER 训练数据集
在过去的五年中,Vision+NLP 的研究者们做出了很多的努力,提出了很多新的任务,同时建立了多个大的数据集,以下列出的是其中非常有名的数据集:

1. 免费数据集上的自监督学习
上面所提到的标注数据需要大量的资金支持,并不是所有研究所都有这个资本收集获得这样的数据集。我们都知道这样的标注数据是很有用的,但是图片和文本本身就带有这样的标注信息,我们通过自监督的方式进行学习。
① Self-SupervisedLearning for Vision

在图像中我们可以训练 CNN 模型对一张灰度图片进行上色,从而用 CNN 来学习对这张图片的表示,这样的图片在网上也是随处可见的。我们还可以使用其他的任务来训练 CNN 对图片的表示,然后使用这些图片表示来应用到其他分类任务上面。
② Self-SupervisedLearning for NLP

在最近一年中,NLP 也有了很大的突破,具有代表性的工作是 Bert 和 GPT2。这两个任务都是使用 Transfomer,Bert 应用的是 Transformer Encoder,GPT2 应用的是 Transformer Decoder。这两个工作有一个共同点就是使用了大量免费的数据进行训练。
③ Vision+NLP

对于 Vision+NLP 的免费数据集也是有很多的,比如 instagram 上随处可见的,这种相对应的图片和文本,虽然这些文本不是确切的描述图片,但也是高度相关的。
2. 我们的数据集
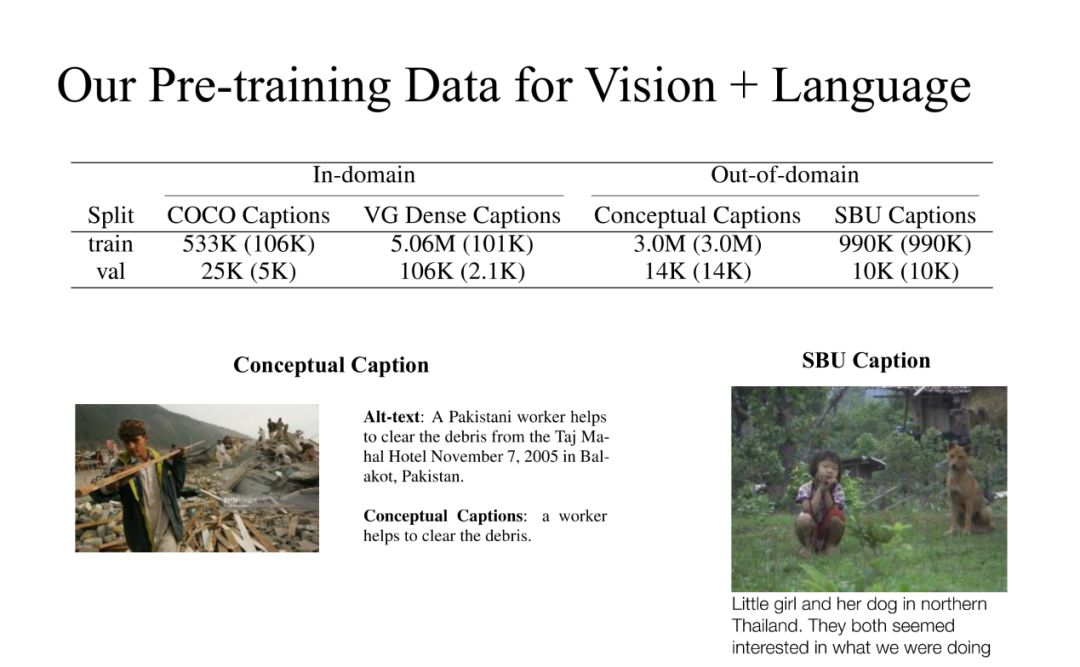
在我们这个实验中,合并了四个公开数据,这四个公开数据分为 In-domain 和 Out-of-domain。
▌UNITER 预训练模型
1. UNITER 两段式训练任务
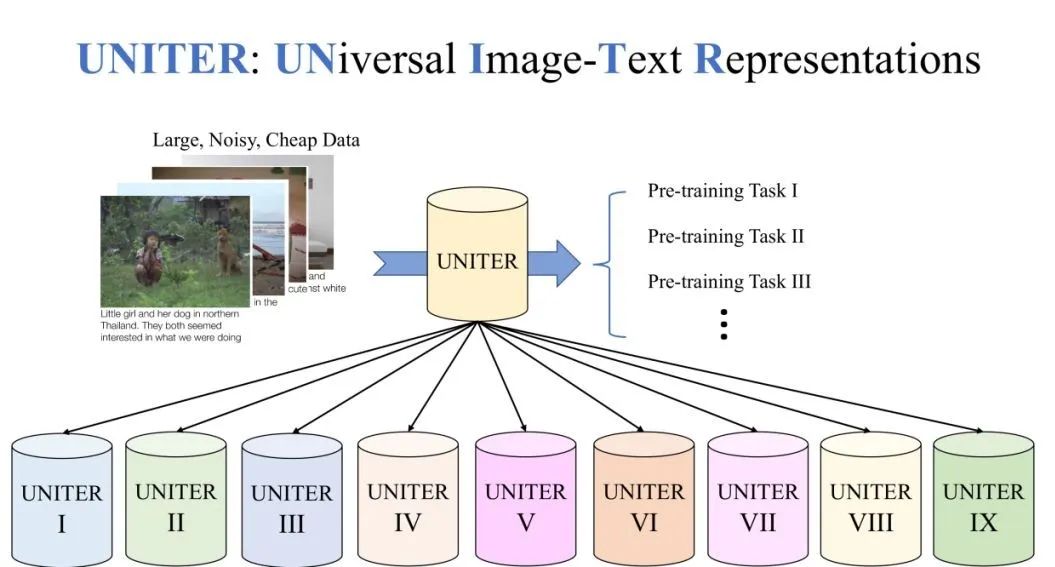
对于 UNITER 模型我们采用了两段式的训练。先在大量的公开数据集上面做一个预训练任务,在这个阶段可以获取一个健壮的模型。在预训练完成之后,我们将模型通过 fine-tuning 适应到下游的任务当中。一般来说,在下游任务中的数据都是比较小的,干净的数据集。
我们发现之前的预训练模型只能适应一到两个的下游任务中,我们的目标是让模型可以适应到更多的下游任务。所以在我们的实验中,考虑了9个数据集并且它们之间都有很大的不同,并且有9个 fine-tune 的模型。
2. 输入方式

我们的数据输入方式是 Image-Text Pair 形式存在的。我们先对 image 通过模型转换成一系列 region,再将 text 转换成 token 的序列,将这两部分输入到 UNITER 模型中。
3. 预训练模型
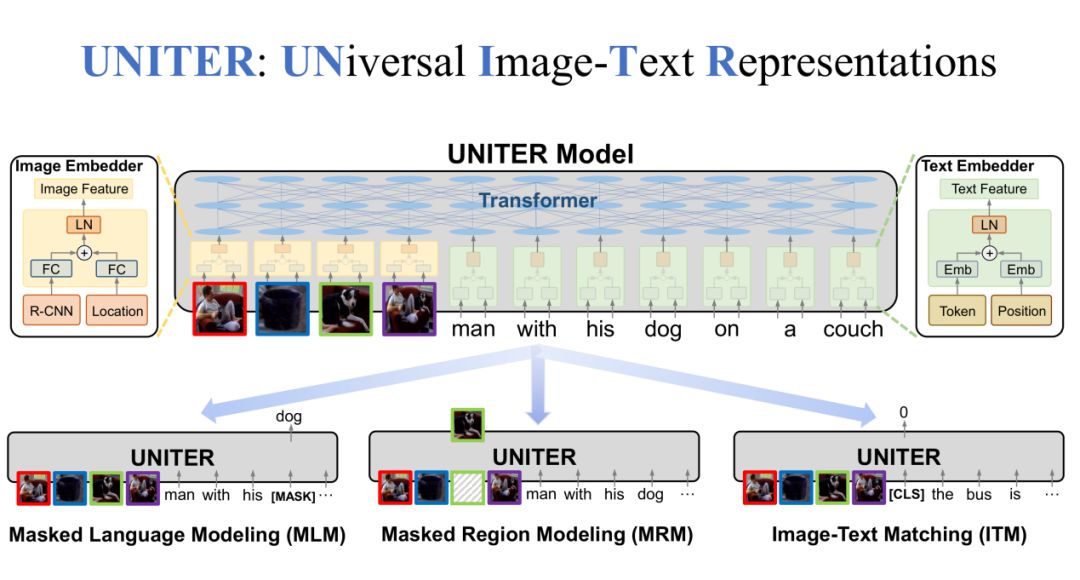
在 UNITER 模型中,一共有三个部分,分别是 Image Embedder、Text Embedder 和整体的 Transformer 模型。在 Image Embedder 中,Region 特征和 Location 特征通过 FC 层相加,再经过 LN 层得到 Image 特征。在 Text Embedder 中,Token 特征和 Position 特征经过 Embedding 之后相加,再经过 LN 层得到 Text 特征。最后,Image 特征和 Text 特征经过 Transformer 得到最终的联合特征。
除此之外,我们还设定了一些预训练任务。比如,随机 MASK 一些文本中的词,然后对这些 MASK 的词进行还原,这是 MLM 任务;同样,我们还可以 MASK 一些图片中的区域,然后进行还原,这是 MRM 任务;第三个任务是我们随机抽取 positive Image-Text Pair 和 negative Image-Text Pair,让模型来预测输入的是 positive 还是 negative,这是 ITM 任务。
MLM 预训练任务
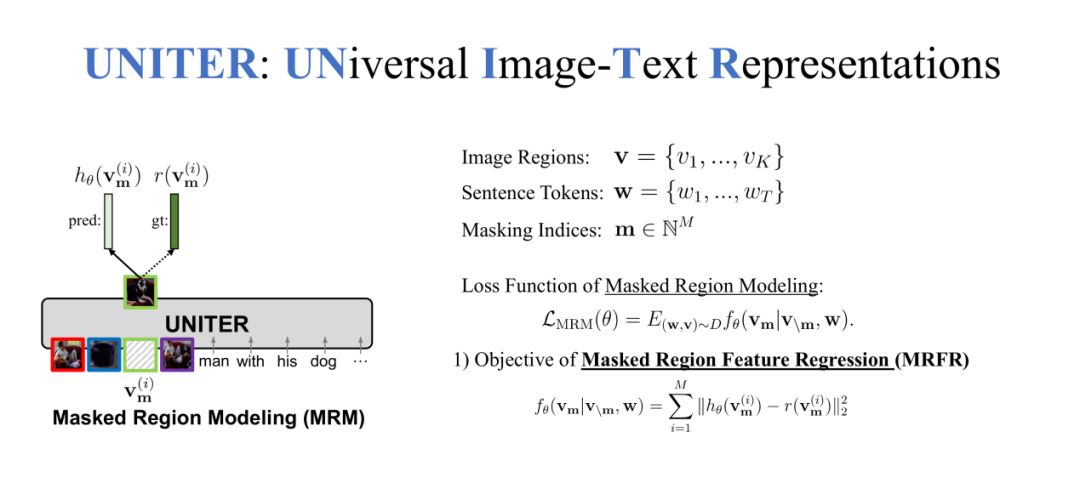
在 Masked LanguageModeling ( MLM ) 预训练任务中,我们输入是 Image-TextPair,获取到 image regions 和 sentence tokens。在 sentence tokens 中随机 MASK 掉一些 token,让 UNITER 来还原这些 token。
MRM 预训练任务 ( MRFR )
在第二个 MaskedRegion Modeling ( MRM ) 预训练任务中,我们 MASK 的不是 token 而是 region,需要还原这些缺失的 region。我们在 MRM 任务中提出了三种不同的方法,第一种方法是 Masked Region Feature Regression ( MRFR )。
对于每个 region 都有一个特征,这是一个高维的向量,可以让 UNITER 来预测这个高维的向量,我们希望 UNITER 输出的向量尽可能的接近被 MASK 掉的 region 特征向量,所以使用 L2 loss 来让两个向量的距离尽可能的小,使两个特征尽可能相似。
MRM 预训练任务 ( MRC )

MRM 的第二种方法是 Masked Region Classification ( MRC ),每一个 region 得到特征向量之后 R-CNN 都会预测一个 label,我们让 UNITER 来对 MASK 的 region 进行预测,使模型学习到每个 MASK region 的分类。
MRM 预训练任务 ( MRC-kl )

MRM 的第三种方法是 Masked Region Classification-KL Divergence ( MRC-kl ),除了对 MASK region 计算分类 label,还可以计算 UNITER 与 R-CNN 对 MASK region 的分布差异,我们希望 UNITER 的 region 分布要尽可能接近 R-CNN 的 region 分布,loss 使用 KL 散度。
ITM 预训练任务

最后的预训练任务是 Image-TextMatching ( ITM ),我们对输入的 Image-TextPair 随机替换 Image 或者 Text,最后预测输入的 Image 和 Text 是否有对应关系,所以这是一个二分类的问题。
4. 优化训练方式
由于计算资源的限制,我们需要一些方法来加速训练速度,这里面使用了三个技巧。分别是 Dynamic Batching、Gradient Accumulation 和 Mixed-precision Training。
Dynamic Batching

在 Dynamic Batching 这种方法是对训练过程中动态的选择 batch 中的 sample。因为 Transformer 的复杂度是跟 region 和 word 的数量 ( L ) 二次方相关的。一般来说 batch 中的长度都是像上图左部分那样,所有输入都 pad 成同样的长度,蓝色是输入的部分,白色是 pad 的部分,可以看出浪费了很多空间。
我们的方法是将长度相近的 sample 放到同一个 batch 中,这样可以减少 pad 的长度,从而减少计算空间。
GradientAccumulation

在实验中,我们使用了4个 GPU,主要时间是浪费在 GPU 之间交换数据上面了,所以我们使用 Gradient Accmulation 的方法来减少 GPU 之间的交互频率上,从而减少训练时间。
Mixed-precisionTraining
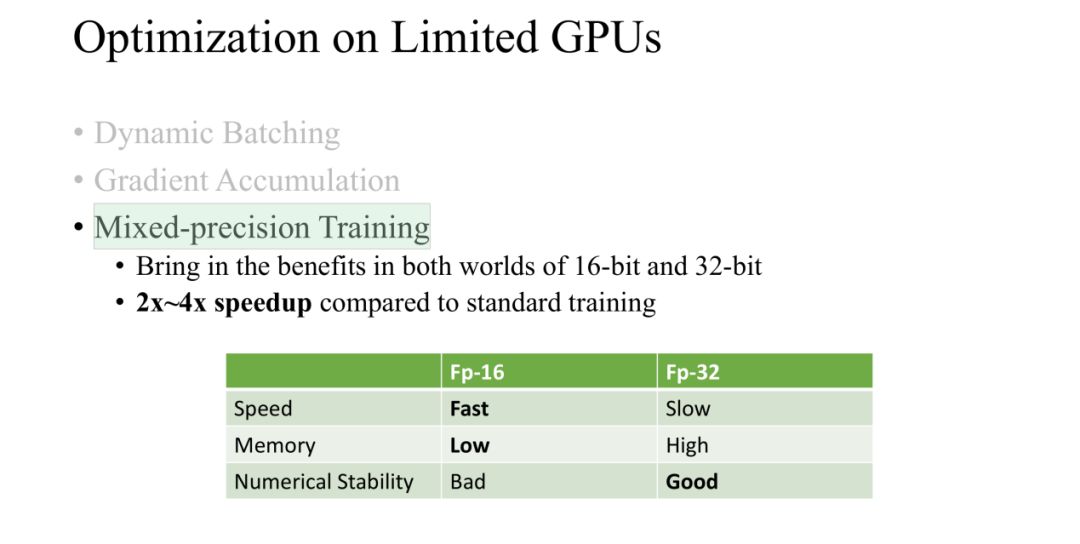
在训练过程中,我们使用了 Mixed-precision 的方法进行训练,分别使用 16-bit 和 32-bit,节省了空间从而 batch size 可以增大,这样就减少了训练时间。
▌下游任务组成
Task 1: Visual Question Answering
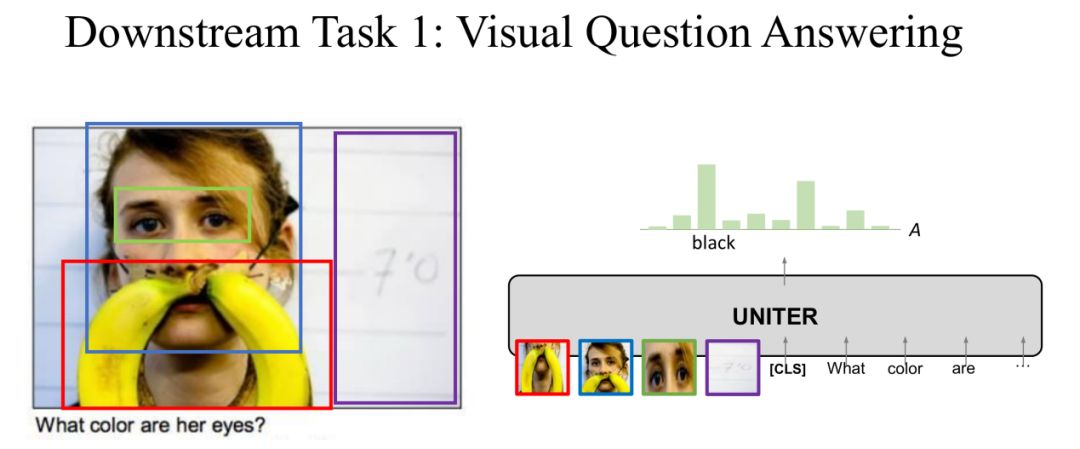
在第一个下游任务 VQA 中,对于一个图片回答图片内容相关的问题。将图片和问题输入到 UNITER 中,输出是答案的分布,取概率最大的答案为预测答案。
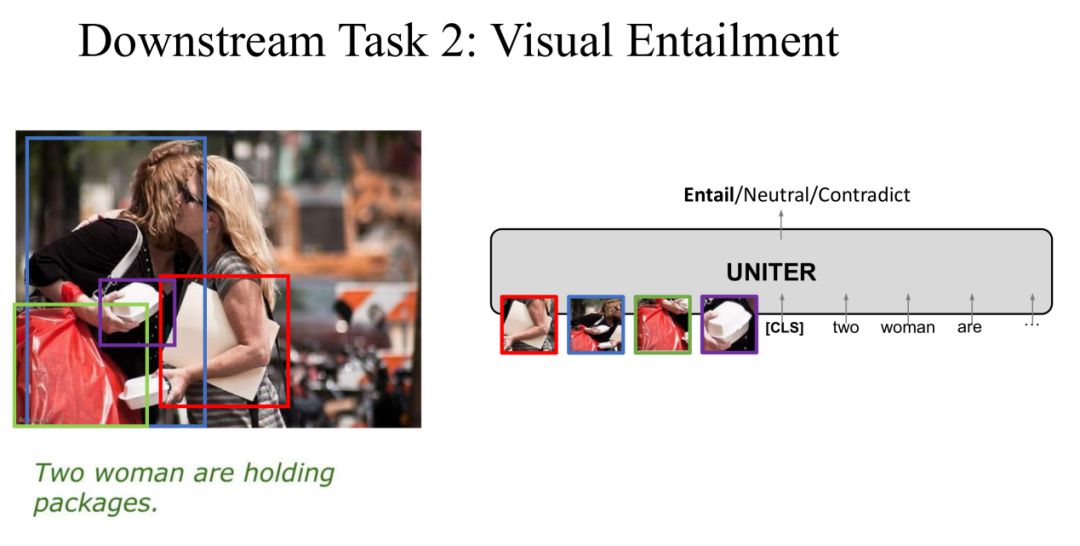
Task 2: Visual Entailment

在第二个任务 Visual Entailment 中,Image 是 Premise,Text 是 Hypothesis,我们的目标是预测 Text 是不是 "Entailment Image",一共有三个 label 分别是 Entailment、Neutral 和 Contradiction。
同样,我们将 Image 和 Text 输入到 UNITER 中,输出是三个 label 中的一个作为预测分类。
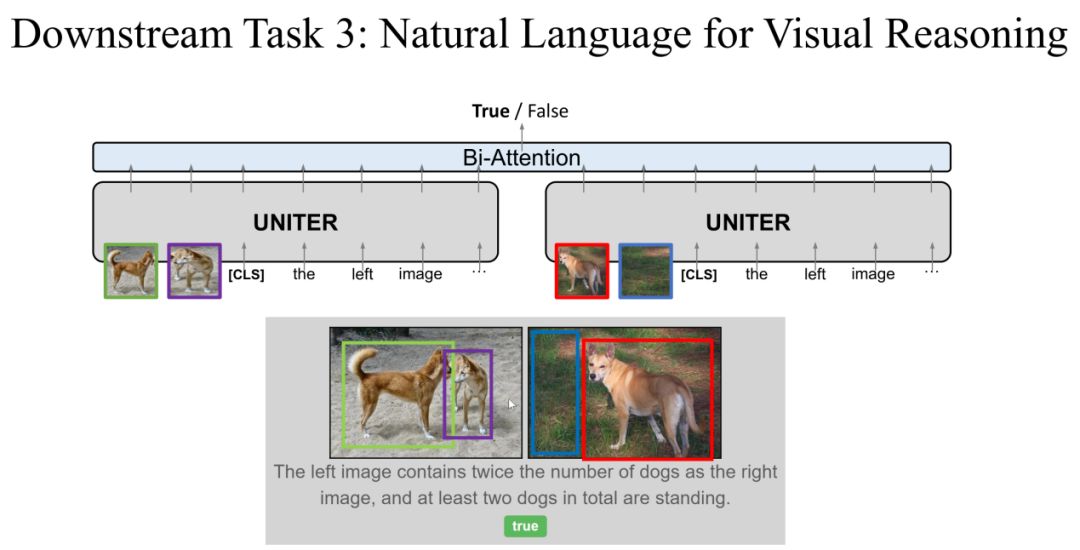
Task 3: Natural Language for Visual Reasoning

第三个任务是 NLVR ( Natural Language for Visual Reasoning ),这个任务不同于前两个任务,同时输入两张 Image 和一个描述,输出是描述与 Image 的对应关系是否一致,label 为两个 ( true/false )。
在这个任务中,我们对 UNITER 的模型进行稍微的改进,一个描述与两个 Image 分别输入到 UNITER 中,两个输出在经过 Bi-Attention 层输出预测的 label。在这个任务上面我们证明了对 UNITER 进行稍微的改动就可以处理不一样的任务。
Task 4: Visual Commonsense Reasoning

第四个任务是 VisualCommonsense Reasoning,它是以选择题形式存在的,对于一个问题有四个备选答案,模型必须从四个答案中选择出一个答案,然后再从四个备选理由中选出选择这个答案的理由。
在训练的过程中,我们将问题和四个备选答案连接到一起再分别与图片输入到 UNITER 中,输出为四个得分,得分最高的为预测答案。同理,在选择理由的时候将问题、答案和四个备选理由分别连接到一起输入到 UNITER 中。

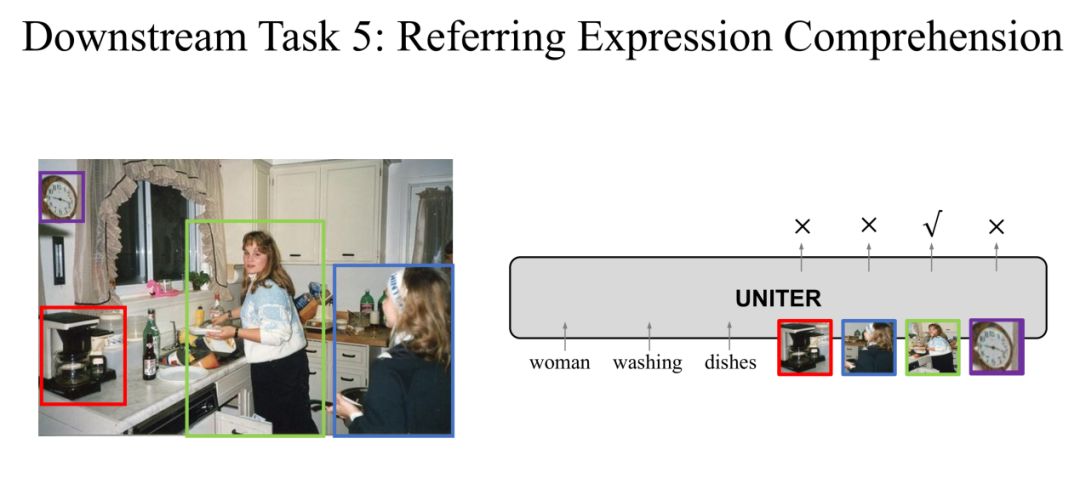
Task 5: Referring Expression Comprehension

在第五个 ReferringExpression Comprehension 任务中,输入是一个句子,模型要在图片中圈出对应的 region。
对于这个任务,我们可以对每一个 region 都输出一个 score,score 最高的 region 作为预测 region。
Task 6: Image-Text Retrieval
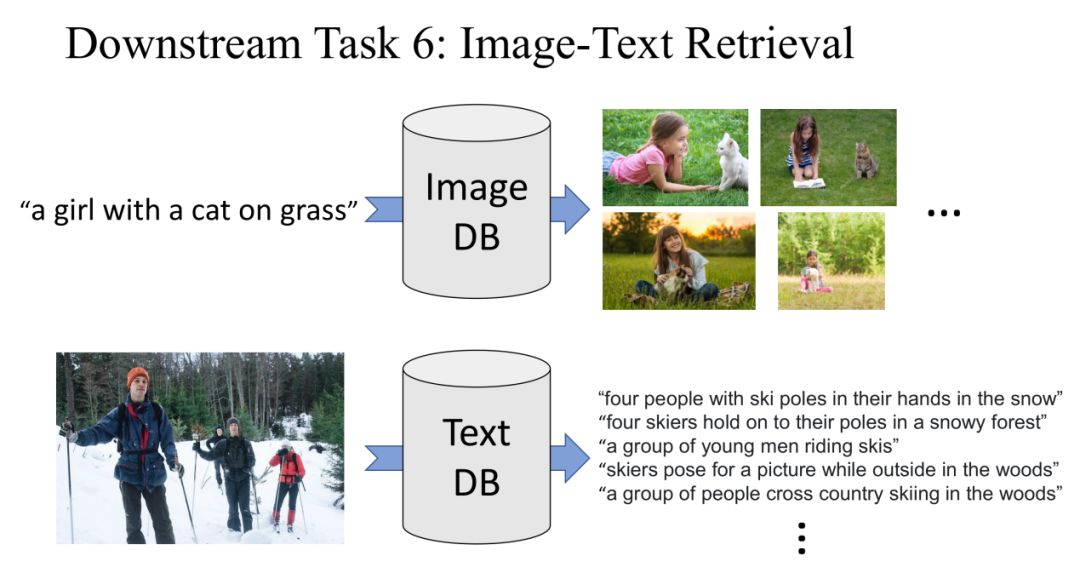
在最后一个 Image-Text Retrieval 任务中,首先我们给定一个句子,在 Image DataBase 中获取与句子相关的 Image。另外,我们还可以给定一个 Image,在 Text DataBase 中获取与图片相关的 Text。
这个任务与我们预训练的 Image-Text Matching 任务非常相似,所以在 fine-tune 的过程中我们选择 positive pair 和 negative pair 的方式来训练我们的模型。UNITER 的目标就是预测 positive 还是 negative。

▌结论
1. Ablation Study
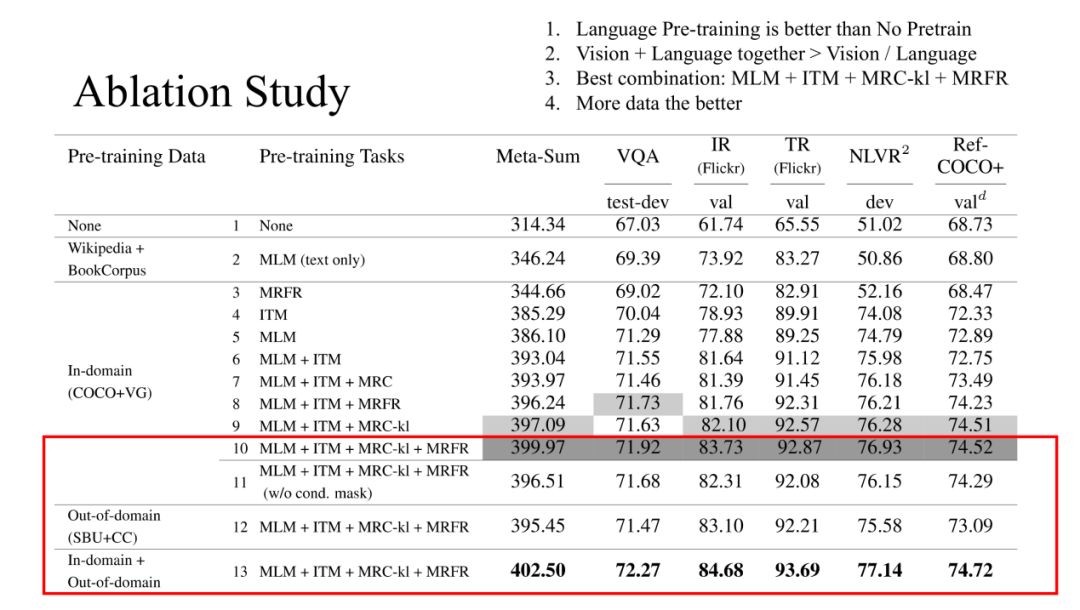
以上是我们针对不同预训练任务的组合在5个下游任务的表现对比。从表中我们可以得出:
-
有文本的预训练任务比没有文本的预训练任务效果更好; -
Vison+Language 组合的预训练效果要好于单独的 Vision/Language; -
最好的预训练组合是:MLM+ITM+MRC-kl+MRFP; -
将上面提到的四个数据一起训练效果最好,这也证明数据越多效果越好。
2. 综合任务成绩比较
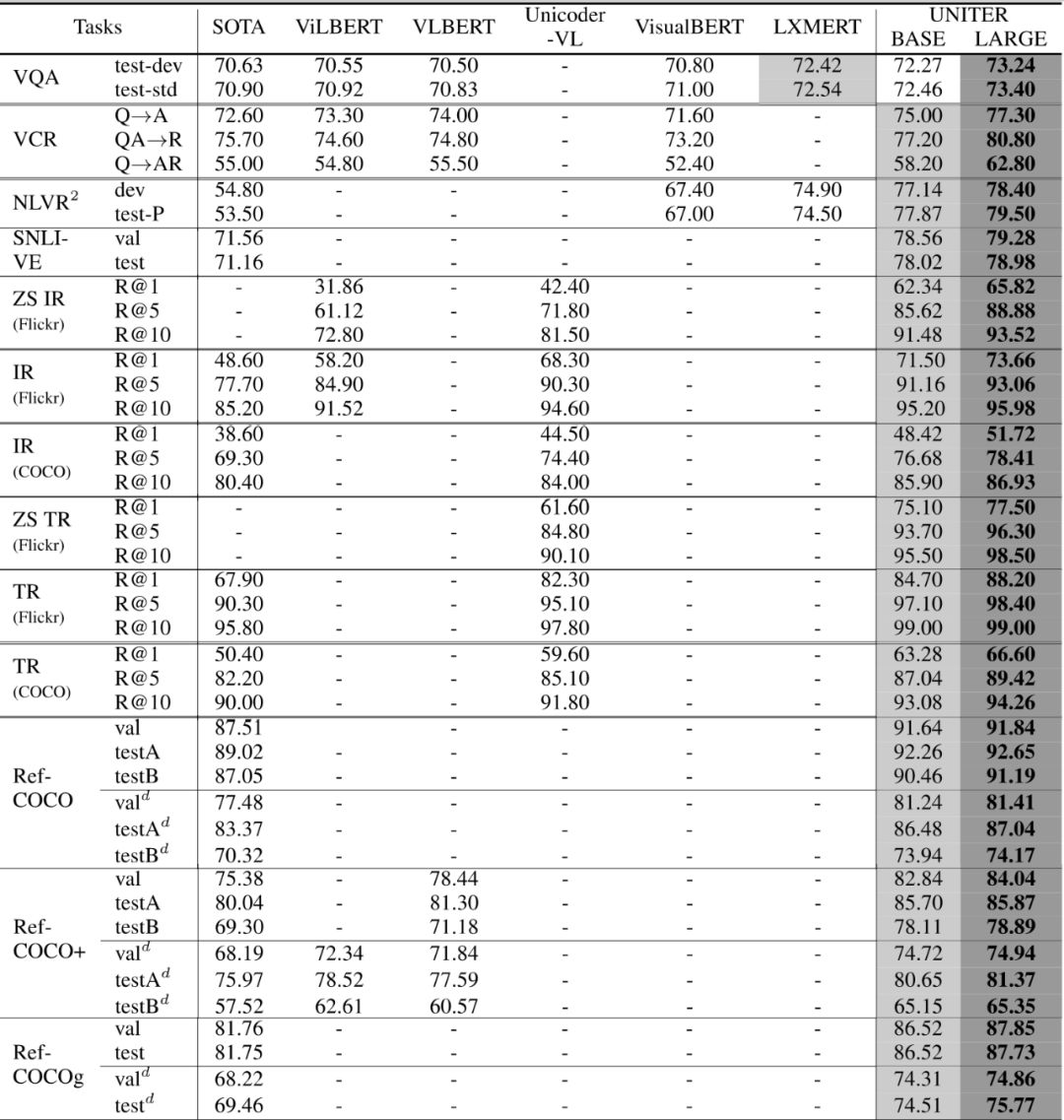
上面表格展现了 UNITER Base 和 Large 在6个下游任务,包含9个数据集的表现效果。UNITER-Base 在9个数据集上面几乎都好于其他的模型,而 UNITER-Large 取得了当前最好的效果。
——END——





