【AAAI 2018】多种注意力机制互补完成VQA(视觉问答),清华大学、香港中文大学等团队最新工作
【导读】近日,针对VQA领域中不同注意力机制(如基于自由区域的注意力和基于检测的注意力)各有利弊的现状,来自清华大学、香港中文大学和华东师范大学的学者发表论文提出一个新的VQA深度神经网络,它集成了两种注意力机制。本文提出的框架通过多模态特征相乘嵌入方案有效地融合了自由图像区域、检测框和问题表示,来共同参与问题相关的自由图像区域和检测框上的注意力计算,以实现更精确的问答。所提出的方法在两个公开的数据集COCO-QA和VQA上进行了大量的评估,并且胜过了最先进的方法。这篇文章被AAAI2018接收,代码已开源。
论文:Co-attending Free-form Regions and Detections with Multi-modal Multiplicative
Feature Embedding for Visual Question Answering

▌摘要
最近,视觉问答(VQA)任务在人工智能中越来越受到重视。现有的VQA方法主要采用视觉注意力机制将输入问题与相应的图像区域联系起来进行有效的问答。基于自由区域和基于检测的视觉注意力机制的方法被广泛调研,其中前者主要关注自由形式图像区域,后者则引入预定的检测框区域。这篇文章认为,两种注意力机制能够提供互补信息,应该对其进行有效整合以更好地解决VQA问题。
在本文中,本文提出了一个新的VQA深度神经网络,它集成了两种注意力机制。提出的框架通过多模态特征相乘嵌入方案有效地融合了自由图像区域、检测框和问题表示,来共同参与问题相关的自由图像区域和检测框上的注意力计算,以实现更精确的问答。所提出的方法在两个公开的数据集COCO-QA和VQA上进行了大量的评估,并且胜过了最先进的方法。
本文提供源码:
https://github.com/lupantech/dual-mfa-vqa
▌详细内容
近年来,基于语言和视觉的多模态学习在人工智能中引起了越来越多的关注。如在图像描述、视觉问题生成、视频问答和文字图像检索等不同的任务上取得了很大的进展。视觉问答(VQA)任务最近成为一项更具挑战性的任务。这些算法需要给出有关给定图像内容的自然语言问题的答案。与传统的视觉语言任务(如图像描述和文本-图像检索)相比,VQA任务要求算法对输入图像和问题有更好的理解,以便推断答案。
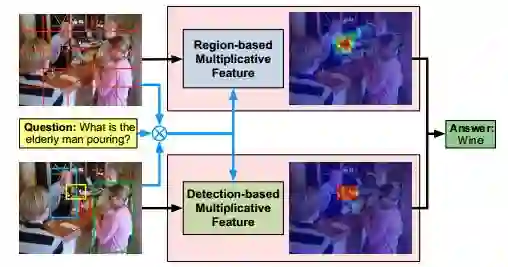
图1:基于问题、整个图像和检测框的自由区域和检测框上的协同注意力机制,能更好地利用互补信息解决VQA任务。
最先进的VQA方法利用视觉注意机制将问题与有意义的图像区域联系起来,以便进行准确的问答。VQA中的大多数视觉注意机制可以分为基于自由形式区域(free-form region)的方法和基于检测的方法。对于基于自由形式区域的方法,通过利用长短期记忆(LSTM)网络学习的问题特征和由卷积神经网络(CNN)学习的图像特征并将两种特征在图像上的每个空间位置融合,融合方法有基于图像空间位置的相加操作、乘法操作或连接操作。自由形式的注意力图是通过在融合特征上应用softmax非线性操作获得的。
由于对所获得的注意力图没有限制,所以自由注意力区域能够关注出现全局视觉上下文的信息和用于推断答案的特定前景物体。然而,由于没有限制,自由的注意力区域有时可能会集中在物体的局部或不相关的上下文中。例如,对于一个问题,如“你看到什么动物?”,一个自由的区域注意力图可能错误地只关注前景中“猫”的一部分,并产生一个“狗”的答案。另一方面,对于基于检测的注意力方法,利用注意力机制将该问题与预先指定的众多检测框(例如边界框)相关联。
与在所有图像空间位置上应用softmax操作不同,这类方法在所有检测框上进行操作。因此,起作用的区域被限制在预先指定的检测框区域,并且这样的问题相关区域可以更有效地回答关于前景物体的问题。但是,这些限制也会对其他类型的问题带来挑战。例如,对于“今天天气怎么样?”这个问题,天空中可能不存在检测框,导致不能回答这个问题。
为了更好地理解问题和图像内容及其关系,一个好的VQA算法需要识别全局的场景属性,定位物体,识别物体的属性、数量和类别,以便做出准确的推断。作者认为,上述两类注意力机制提供了互补信息,可以有效地融入到一个统一的框架中,以协同利用自由区域和检测区域的信息。以上面提到的两个问题为例,利用基于检测的注意力图可以更有效地回答关于动物的问题,而利用基于自由区域的注意力图可以更好地回答关于天气的问题。
这篇文章提出了一种新颖的双支深度神经网络,用于解决基于自由区域和基于检测注意力机制(图1)的VQA问题。总体框架由两个注意力分支组成,每个分支将问题与输入图像中最相关的自由区域或与最相关的检测区域相关联。为了获得更多的与问题有关的两类区域的注意力权重,本文提出用特征相乘嵌入方案来学习输入问题的联合特征表示、整个图像以及检测框。这样的乘法方案不共享两个分支之间的参数,并且显示出比现有方法更鲁棒的应答性能。
这篇文章的贡献可以总结为以下两点:
提出了一个新的双支深度神经网络,有效地将基于自由区域和基于检测的注意力机制集成在一个统一的框架中;
为了更好地融合不同模态的特征,提出了一种新的特征相乘嵌入方案,从问题、整个图像和检测框中学习联合特征表示。
▌模型简介
本文提出的方法以问题、整幅图像和检测框作为输入,进而协同的学习出与问题相关的自由图像区域的注意力和检测框注意力来推断答案。
整个模型框架如图2所示。在计算每种注意力权重之前,通过相乘的方式获得问题、整体图像视觉特征和检测框视觉特征的联合特征表示。计算注意力之后,两个分支网络上产生的视觉特征与问题表示进行融合、相加,进而得到最终的问题-图像嵌入。一个多类线性分类器被用于预测最终答案。
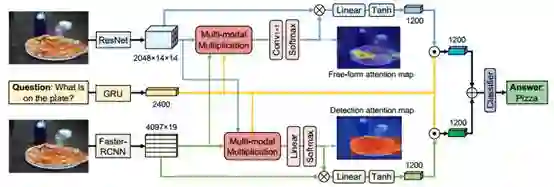
图2:展示了解决VQA任务的总体网络结构。该网络使用提出的特征相乘嵌入方案,具有两个注意力分支,其中一个分支用于自由图像区域,另一个分支用于编码问题相关视觉特征的检测框
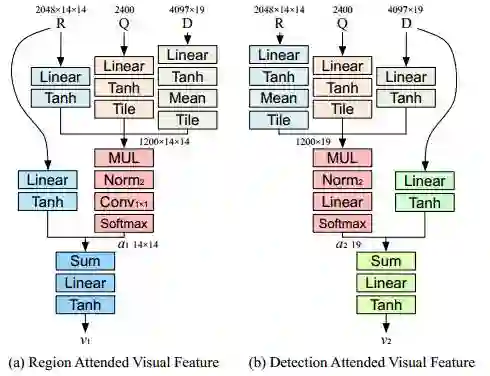
图3:学习使用多模态特征相乘嵌入来学习视觉特征,分别学习(a)自由图像区域和(b)检测框。
(1)学习自由区域的视觉特征
给定问题特征表示
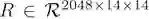
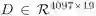

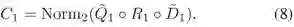

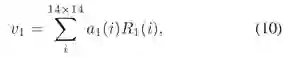
其中a代表注意力图,v代表学习到的视觉特征,W,b是网络参数。
(2)学习检测框的视觉特征
通过如下方式进行检测框视觉特征的计算:
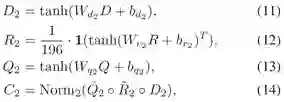
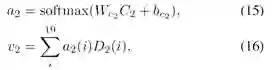
同样,这里a代表注意力图,v代表学习到的视觉特征,W,b是网络参数。
(3)预测答案
本文首先进行特征融合,再通过一个常见的softmax函数预测问题答案:
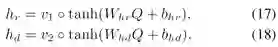
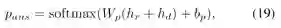
▌实验结果
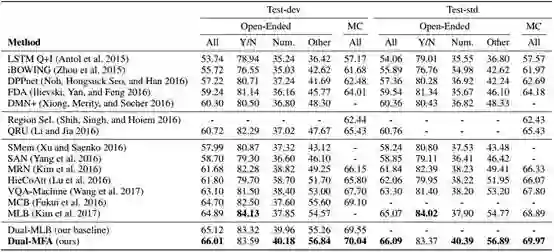
表1:在VQA数据集上评估提出的方法和比较方法的结果。
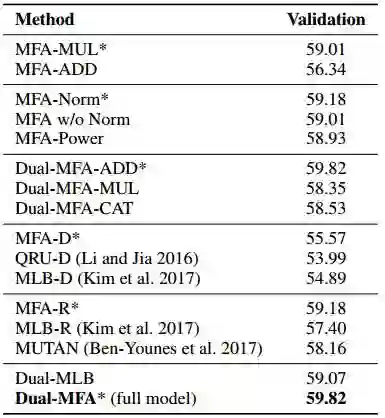
表2:VQA数据集的Ablation研究,其中“*”表示本文提出的模型。

表3:在COCO QA数据集上评估提出的方法和比较方法的结果。
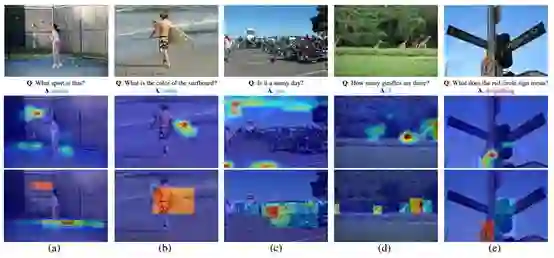
图4:VQA测试集的可视化示例。(第一行)输入图像。(第二行)基于自由区域的注意力图。(第三行)基于检测的注意力图。
▌结论
在本文中,作者提出了一种新的基于协同注意力机制的视觉问答的深度神经网络。该深度模型包含两个视觉注意力分支,旨在选择与输入问题最相关的自由图像区域和检测框。通过一种新颖的相乘嵌入方案产生视觉注意力权重,有效地对问题、整体图像和检测框进行特征融合。
研究证明了提出的模型的各个组成部分的有效性。在两个大的VQA数据集上的实验结果表明,提出的模型超过了最先进的方法。
参考链接:
https://arxiv.org/abs/1711.06794
https://github.com/lupantech/dual-mfa-vqa
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
同时欢迎各位用户进行专知投稿,详情请点击:
【诚邀】专知诚挚邀请各位专业者加入AI创作者计划!了解使用专知!
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!
点击“阅读原文”,使用专知!




