
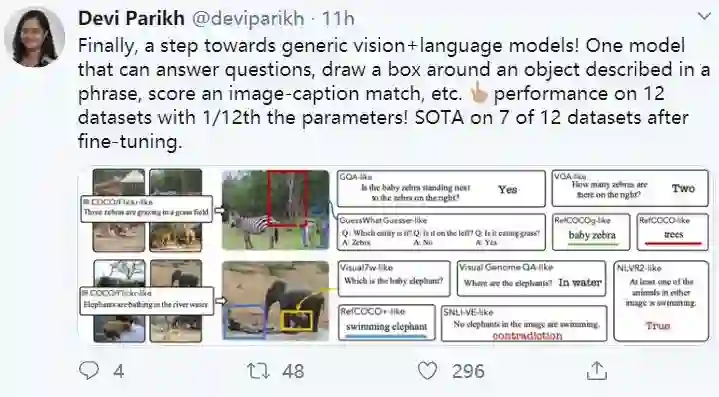
许多视觉和语言的研究集中在一组小而多样的独立任务和支持的数据集上,这些数据集通常是单独研究的;然而,成功完成这些任务所需的视觉语言理解技能有很大的重叠。在这项工作中,我们通过开发一个大规模的、多任务的训练机制来研究视觉和语言任务之间的关系。我们的方法最终在12个数据集上建立了一个模型,这些数据集来自4大类任务,包括可视化问题回答、基于标题的图像检索、基础引用表达式和多模态验证。与独立训练的单任务模型相比,这意味着从大约30亿个参数减少到2.7亿个参数,同时在各个任务中平均提高性能2.05个百分点。我们使用我们的多任务框架来深入分析联合训练不同任务的效果。此外,我们还展示了从单一的多任务模型中细化特定任务模型可以带来进一步的改进,达到或超过最先进的性能。
成为VIP会员查看完整内容
相关内容



相关VIP内容
相关资讯