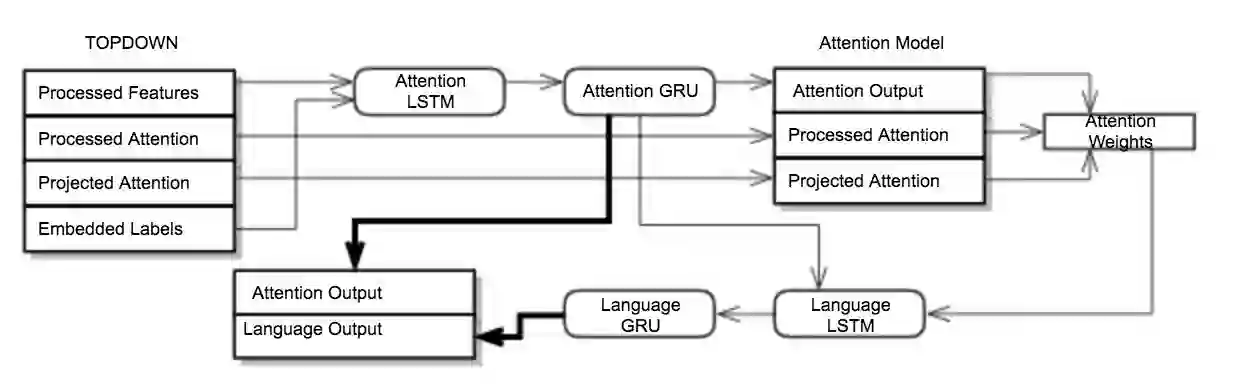
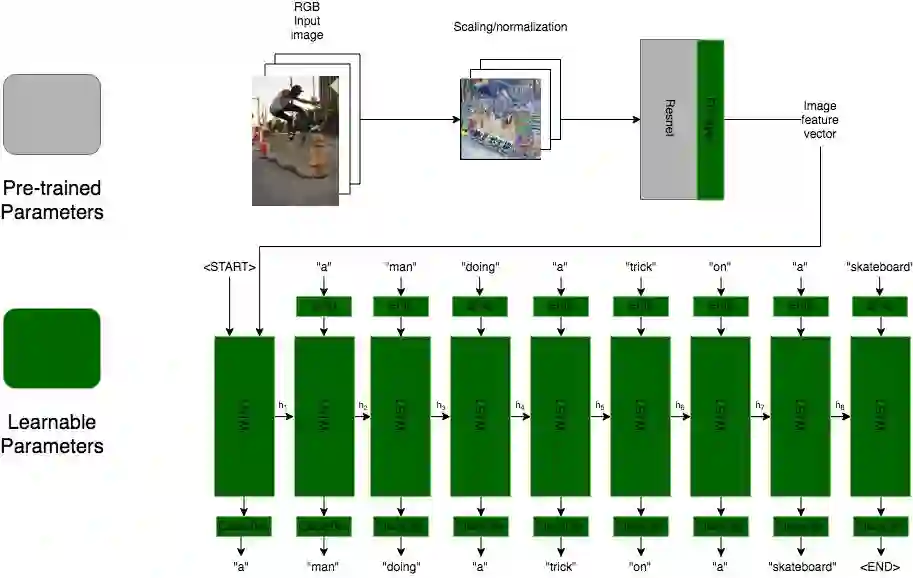
In recent years, the biggest advances in major Computer Vision tasks, such as object recognition, handwritten-digit identification, facial recognition, and many others., have all come through the use of Convolutional Neural Networks (CNNs). Similarly, in the domain of Natural Language Processing, Recurrent Neural Networks (RNNs), and Long Short Term Memory networks (LSTMs) in particular, have been crucial to some of the biggest breakthroughs in performance for tasks such as machine translation, part-of-speech tagging, sentiment analysis, and many others. These individual advances have greatly benefited tasks even at the intersection of NLP and Computer Vision, and inspired by this success, we studied some existing neural image captioning models that have proven to work well. In this work, we study some existing captioning models that provide near state-of-the-art performances, and try to enhance one such model. We also present a simple image captioning model that makes use of a CNN, an LSTM, and the beam search1 algorithm, and study its performance based on various qualitative and quantitative metrics.
翻译:近年来,主要计算机视野任务(如物体识别、手写数字识别、面部识别等)取得的最大进展,都来自使用进化神经网络(CNNs),同样,在自然语言处理、常规神经网络(RNNS)和长期短期记忆网络(LSTMs)等领域,对于在机器翻译、部分语音标签、情绪分析等任务执行中取得的一些最大突破至关重要。这些个人进步,甚至在NLP和计算机视野的交叉点上,也因这一成功而大大受益,我们研究了一些已证明行之有效的现有神经图像说明模型。在这项工作中,我们研究了一些提供近于最新表现的现有说明模型,并试图加强其中的一种模型。我们还提出了一个简单的图像说明模型,利用CNN、LSTM和Baam搜索1算法,并研究其基于各种定性和定量计量的绩效。