字节跳动李航提出AMBERT!超越BERT!多粒度token预训练语言模型
来自:专知
字节跳动 Xinsong Zhang、李航两位研究者在细粒度和粗粒度标记化的基础上,提出了一种新的预训练语言模型,他们称之为 AMBERT(一种多粒度 BERT)。在构成上,AMBERT 具有两个编码器。


预训练语言模型如BERT在自然语言理解(NLU)的许多任务中表现出色。模型中的tokens通常是细粒度的,像英语是单词或sub-words或者是像中文字符。在英语中,例如,有多词表达形式的自然词汇单位,因此使用粗粒度标记似乎也是合理的。事实上,细粒度和粗粒度的标记化在学习预训练语言模型方面都有优缺点。在本文中,我们提出了一种新的基于细粒度和粗粒度标记的预训练语言模型,称为AMBERT(一种多粒度的BERT)。对于英语,AMBERT将单词序列(细粒度令牌)和短语序列(粗粒度令牌)作为标记化后的输入,使用一个编码器处理单词序列,另一个编码器处理短语序列,利用两个编码器之间的共享参数,最后创建单词的上下文化表示序列和短语的上下文化表示序列。实验在CLUE, GLUE, SQuAD和RACE基准数据集上进行了中文和英文测试,。结果表明,AMBERT模型在几乎所有情况下都优于现有的性能最好的模型,特别是对中文的性能改善显著。
https://arxiv.org/pdf/2008.11869.pdf
概述
预训练模型,如BERT、RoBERTa和ALBERT(Devlin et al., 2018; Liu et al., 2019; Lan et al., 2019) 在自然语言理解(NLU)方面显示出强大的能力。基于Transformer的语言模型首先在预训练中从大型语料库中学习,然后在微调中从下游任务的标记数据中学习。基于Transformer (Vaswani et al ., 2017),通过预训练技术和大数据, 模型可以有效地捕捉词法,句法,语义关系的标记输入文本,在许多NLU任务,如情绪分析、文本蕴涵和机器阅读理解实现最先进的性能。
例如在BERT中,预训练主要是基于mask language modeling (MLM)进行的,其中输入文本中约15%的token被一个特殊的token[mask]蒙住,目的是根据蒙住的文本重建出原始文本。对个别任务分别进行微调,如文本分类、文本匹配、文本跨度检测等。通常,输入文本中的标记是细粒度的;例如,它们是英语中的词或子词,是汉语中的字。原则上,标记也可以是粗粒度的,即,例如,英语中的短语和汉语中的单词。英语中有很多多词的表达,比如“纽约”和“冰淇淋”,短语的使用也似乎是合理的。在汉语中使用单词(包括单字单词)更为明智,因为它们是基本的词汇单位。实际上,所有现有的预训练语言模型都使用了单粒度(通常是细粒度)的标记。

以前的工作表明,细粒度方法和粗粒度方法各有利弊。细粒度方法中的标记作为词汇单位不太完整,但它们的表示更容易学习(因为在训练数据中有更少的标记类型和更多的标记),虽然粗粒度方法中的标记作为词汇单位更完整,但是它们的表示更难以学习(因为在训练数据中有更多的标记类型和更少的标记)。此外,对于粗粒度方法,不能保证标记(分割)是完全正确的。有时模棱两可的存在,最好保留所有标记化的可能性。相比之下,对于细粒度的方法,标记化是在原始级别执行的,不存在“不正确”标记化的风险。
例如,Li et al(2019)观察到,在汉语语言处理的深度学习中,细粒度模型的表现始终优于粗粒度模型。他们指出,原因是低频率的单词(粗粒度的标记)往往没有足够的训练数据,而且往往没有词汇表,因此学习到的表示是不够可靠的。另一方面,之前的工作也证明了在语言模型的预训练中对粗粒度标记进行掩蔽是有帮助的(Cui et al., 2019;Joshi et al., 2020)。也就是说,尽管模型本身是细粒度的,但是在连续的标记(英语中的短语和汉语中的单词)上进行屏蔽可以导致学习更准确的模型。
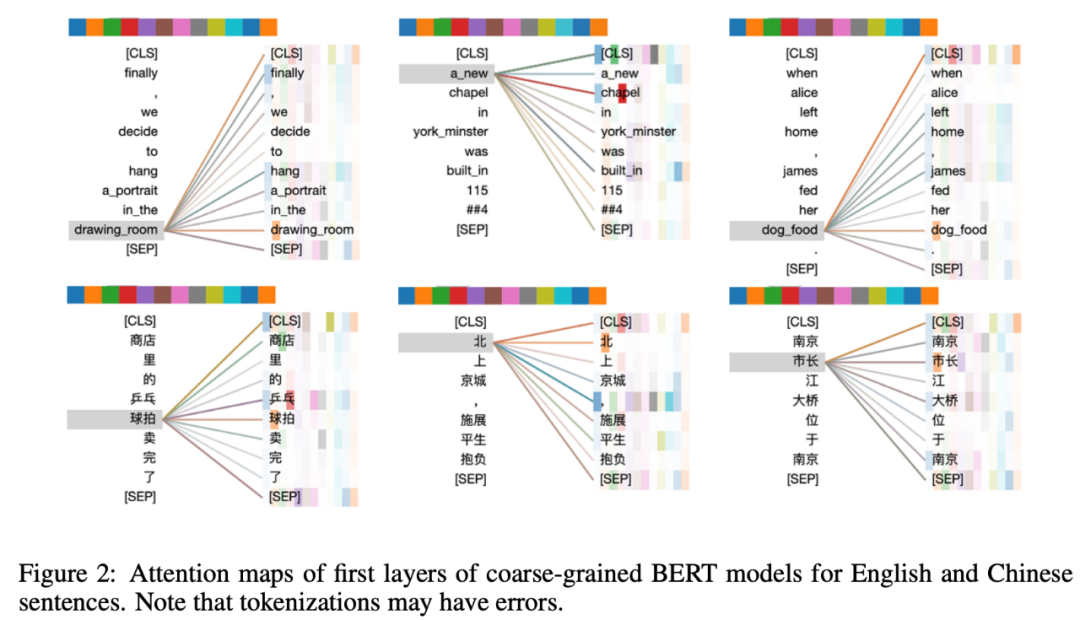
我们为英语和汉语构建了细粒度和粗粒度的BERT模型,并使用BertViz工具检查模型的注意力图(Vig, 2019)。图1显示了英语和汉语中几个句子的第一层细粒度模型的注意力图。可以看到,例如在英文句子中,「drawing」、「new」和「dog」分别对「portrait」、「york」和「food」这几个词有高注意力权重,但这是不合适的。而在中文句子中,汉字「拍」、「北」和「长」分别对「卖」「京」「市」有高注意力权重,这也是不合适的。
在本文中,我们提出了一个多粒度的BERT模型(AMBERT),它同时使用了细粒度和粗粒度标记。对于英语,AMBERT通过使用两个编码器同时构造输入文本中的单词和短语的表示来扩展BERT。确切地说,AMBERT首先在单词和短语级别上进行标记化。然后,它将单词和短语的嵌入作为两个编码器的输入。它在两个编码器中使用相同的参数。最后,它在每个位置上分别获得该词的上下文表示和该短语的上下文表示。注意,由于参数共享,AMBERT中的参数数目与BERT中的参数数目相当。AMBERT可以在单词级和短语级表示输入文本,以利用这两种标记方法的优点,并在多个粒度上为输入文本创建更丰富的表示。
我们使用英文和中文的基准数据集进行了充分实验,以比较AMBERT和基线以及备选方案。结果表明,无论在中文还是英文中,AMBERT模型的性能都显著优于单粒度的BERT模型。在英语方面,与谷歌BERT相比,AMBERT的GLUE分数比谷歌BERT高2.0%,RACE分数比谷歌BERT高2.5%,SQuAD 分数比谷歌BERT高5.1%。在汉语中,AMBERT的CLUE平均分提高了2.7%以上。AMBERT可以在CLUE的leader board击败所有参数小于200M的基础模型。
在这项工作中,我们做出了以下贡献。
多粒度预训练语言模型的研究,
提出一种新的被称为AMBERT的预训练语言模型作为BERT的扩展,它利用了多粒度的token和共享的参数,
AMBERT在英文和中文基准数据集GLUE, SQuAD, RACE,和CLUE上的实证验证
AMBERT 多粒度预训练语言模型
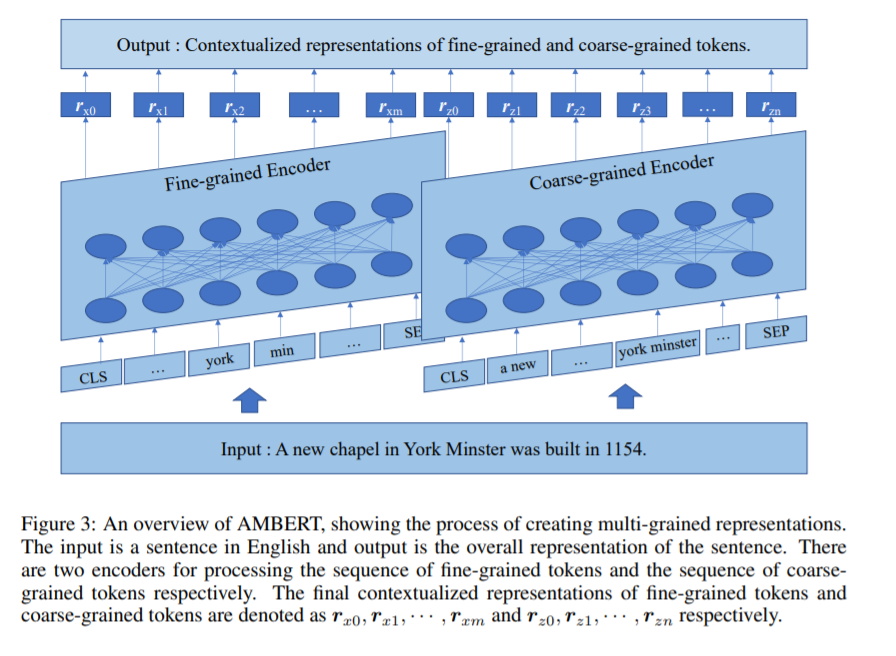
上图给出了 AMBERT 的整体框架。AMBERT 以文本作为输入,其中,文本要么是单个文档中的长序列,要么是两个不同文档中两个短序列的级联。接着在输入文本上进行标记化,以获得细、粗粒度的 token 序列。AMBERT 具有两个编码器,分别用于处理细、粗粒度 token 序列。每个编码器具有与 BERT(Devlin 等人,2018)或 Transformer 编码器(Vaswani 等人,2017)完全相同的架构。此外,两个编码器在每个对应层共享相同的参数,但两者的嵌入参数不同。细粒度编码器在对应层上从细粒度 token 序列中生成上下文表示,而粗粒度编码器在对应层上从粗粒度 token 序列中生成上下文表示。最后,AMBERT 分别输出细、粗粒度 token 的上下文表示序列。
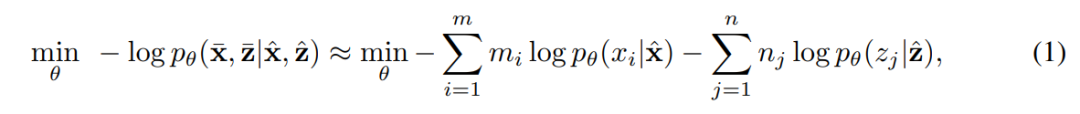
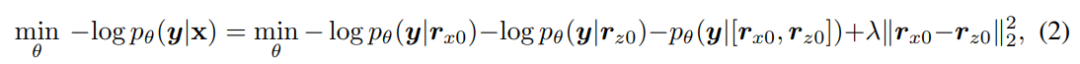



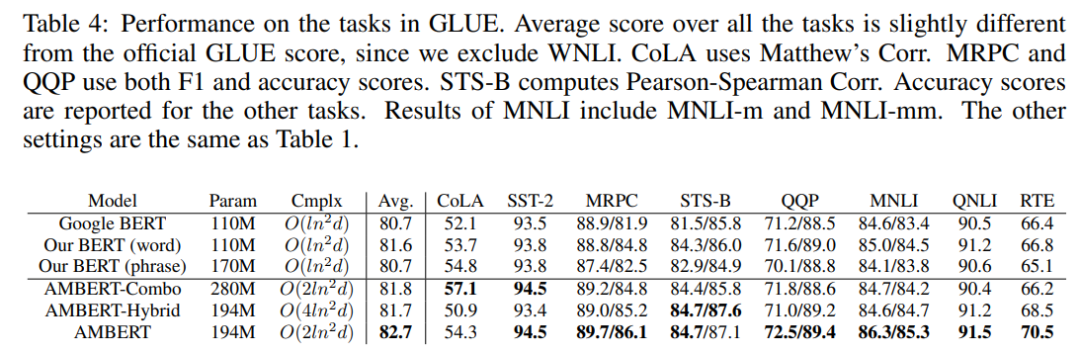
AMBERT是最佳的多粒度模型。
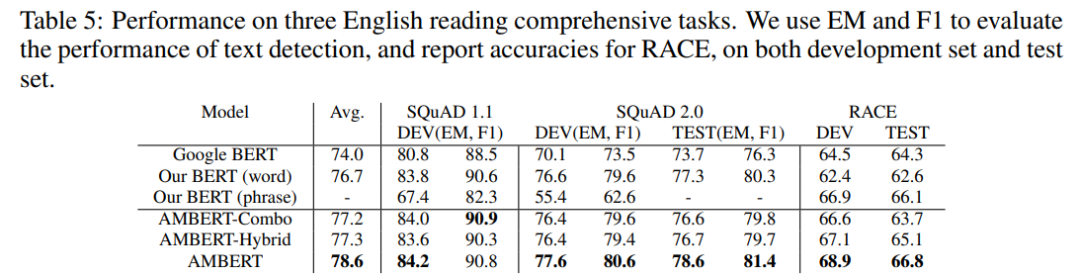

参考链接:
https://mp.weixin.qq.com/s/KfMT5-JfH90d9kNf3NQTqQ
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方“深度学习自然语言处理”,进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心
投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦
整理不易,还望给个在看!



