BERT霸榜问答任务,谷歌新基准模型缩小AI与人类差距50%
点击上方“公众号”可以订阅哦!

来源:新智元
来源:新智元
编辑:肖琴
【导读】谷歌为最近发布的自然问题数据集开发了一个新的基于BERT的新模型,刷新了AI在这个任务上的表现。对于长答案和短答案任务,分别将AI系统与人类表现之间的差距缩小了30%和50%。
上周,谷歌AI团队发布了一个新的NLP基准数据集:自然问题数据集(Natural Questions)。
NQ数据集包含30万个来自真实用户的问题及来自Wikipedia页面的人工注释答案,用于训练QA系统。
此外,NQ语料库还包含16000个示例,每个示例都由5位不同的注释人提供答案(针对相同的问题),这对于评估所学习的QA系统的性能非常有用。
谷歌还发起了一项基于此数据集的挑战赛,以帮助提高计算机对自然语言的理解。任务要求QA系统阅读和理解整个Wikipedia文章,其中可能包含问题的答案,也可能不包含,因此NQ比以前的QA数据集更具有现实性和挑战性。

在该数据集的原始论文《Natural Questions: a Benchmark for Question Answering Research》中,谷歌团队的研究人员报告了人类在“长答案”和“短答案”两个QA任务上的最优表现,分别是长答案90% precision, 85% recall;短答案79% precision, 72% recall。
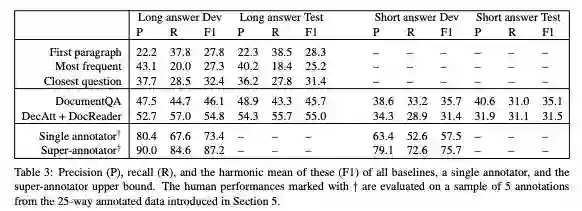
在原始论文中,谷歌测试了DocumentQA和DecAtt + DocReader两个模型,显然后者的表现略好,但与人类表现相比差距仍然很大。
在这篇原始论文发布之后,谷歌AI团队很快发布一篇新论文“A BERT Baseline for the Natural Questions”,描述了Natural Questions数据集的一个新基线模型。

https://arxiv.org/pdf/1901.08634.pdf
该模型基于BERT,并且对于长答案和短答案任务,分别将模型的 F1分数与人类表现之间的差距缩小了30%和50%。该基线模型已经提交给官方NQ挑战赛排行榜。谷歌计划在不久的将来开放源代码。
BERT (Devlin et al. , 2018) 是谷歌在去年10月发布的一个NLP预训练语言表示模型,它的发布极大地提高NLP任务的最新技术水平,尤其是在问题回答方面。
参考阅读:NLP<em>历</em><em>史</em><em>突</em><em>破</em>!谷歌BERT模型狂<em>破</em>11项纪录,全面超越人类!
例如,在撰写本文时,SQuAD 2.0排行榜上的前17个系统、以及CoQA排行榜上的前5个系统都是基于BERT的模型。基于BERT的问答模型获得的结果也正在迅速接近这些数据集所报告的人类水平表现(human performance)。
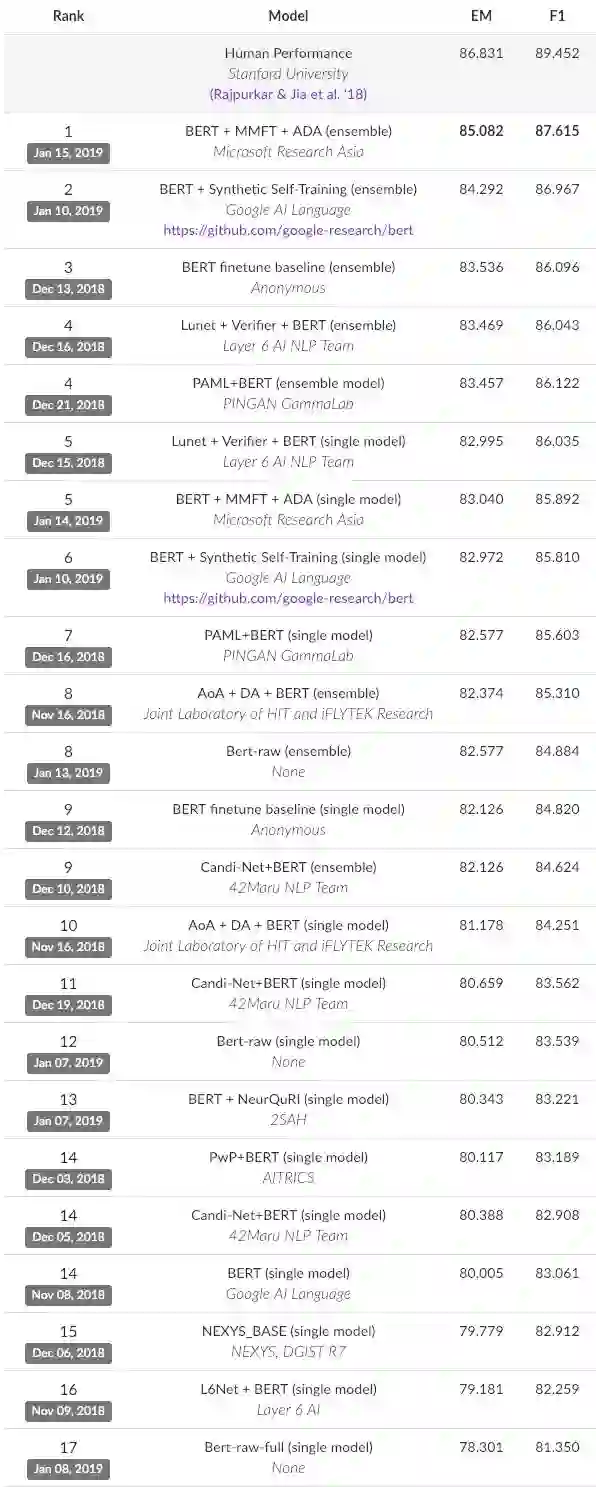
SQuAD 2.0排行榜的前17个模型都是基于BERT的
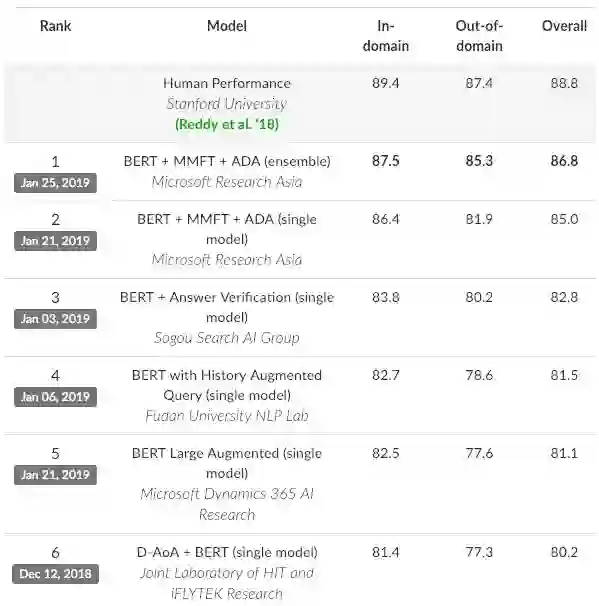
CoQA排行榜上的前5个系统都基于BERT
我们假设自然问题(NQ)可能比问题回答任务(如SQuAD 2.0和CoQA)更具有挑战性,因此NQ可能是当前NLP社区关注的一个很好的benchmark。
我们认为NQ比其他问答数据集更具挑战性的理由如下:
NQ中的问题都是由人类出于真正的好奇心或出于完成某项任务必须的答案而提出的;
提问题的人在提问之前没有看过可能包含答案的文档;
需要在上面找答案的文档比现有问答挑战任务使用的文档更长。
在本文中,我们描述了一个用于Natural Questions数据集的基于BERT的模型。BERT在这个数据集上的表现非常好,对于长回答和短回答,该模型分别将原始数据集论文中报告的模型F1分数与人类上限之间的差距分别缩小了30%和50%。但仍有很大的提升空间:长回答任务是22.5 F1 points,短回答任务是23 F1 points。
我们方法中的关键见解是:
1. 在单个模型中联合预测短答案和长答案,而不是使用 pipeline 方法,
2. 通过使用token重叠窗口将每个文档分割为多个训练实例,就像在SQuAD任务中的原始BERT模型一样,
3.在训练时主动向下采样空实例(即没有答案的实例),以创建一个平衡训练集,
4. 在训练时使用“[CLS]”标记来预测空实例,并通过span分数和“[CLS]”分数之间的差异来预测空实例。
我们将这个模型称为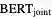
接下来的部分,我们将进一步详细说明如何如何对NQ数据集进行预处理,解释我们在基于BERT的模型中为使其适应NQ任务而做出的建模选择,并最终展示这个模型的结果。
在形式上,我们将训练集实例定义为一个四元组
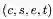
其中c是512个wordpiece id(包括问题,文档标记和标记符号)的上下文,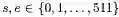
我们为训练实例定义模型的损失函数
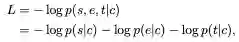
其中,每一个概率p都是由BERT模型计算得到的分数作为softmax,如下所示:
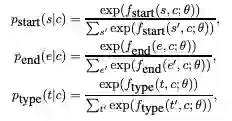
其中θ表示 BERT模型参数,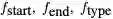
在推理时,我们对每个文档的所有上下文进行评分,然后根据评分对所有文档范围(s, e)进行排序
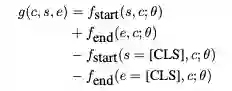
然后,返回文档中得分最高的span,作为预测的短答案范围。
我们选择通过总是输出单个短回答作为预测来限制这个基线模型的复杂性,并根据官方NQ评估脚本设置阈值来决定哪个预测应该改为只有长答案或没有答案。
我们期望通过将 start/end 和回答类型输出结合起来,有时预测 yes/no 的答案,而不是总是预测一个span作为短答案,从而进一步改进模型。我们还期望通过扩展模型,使其能够输出由多个不相交跨度组成的简短答案,从而实现额外的改进。
我们根据在SQuAD 1.1 调优过的BERT模型初始化了我们的模型。然后,在预计算的训练实例上进一步调优了模型。
我们使用Adam optimizer最小化了上一节中的损失函数L,将batch size变为8。
按照BERT模型的惯例,我们只微调了epoch数和初始学习率,发现1 epoch、初始学习率为0.005是最好的设置。
使用单个Tesla P100 GPU,在NQ开发集和测试集上完成评估大约需要5小时。
模型得到的结果如表1所示。我们为NQ数据集开发的BERT模型比原始NQ论文中的模型性能要好得多。我们的模型缩小了原始基线系统的F1分数与人类表现上限之间的差距,长回答NQ任务的表现差距缩小了30%,短回答NQ任务表现差距缩小了50%。
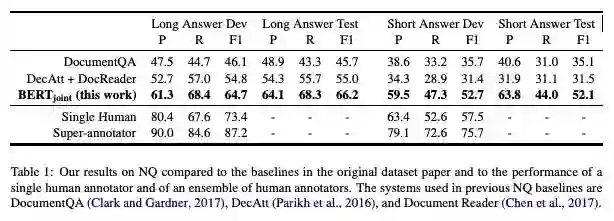
表1:我们的模型在NQ上的结果与原始数据集论文中的基线模型进行了比较,并与单个人工注释者和一组人工注释者的表现进行了比较。原始数据集论文中使用的模型是DocumentQA (Clark and Gardner, 2017), DecAtt (Parikh et al., 2016), 和 Document Reader (Chen et al., 2017).
然而,NQ问题似乎还远远没有解决,对于长回答和短回答任务,都有超过20 F1分数的差距。
我们提出了一个基于BERT的模型,作为新发布的Natural Questions数据集的新基线。
我们希望这个基线模型可以为希望为 Natural Questions和其他具有类似特征的问答数据集创建更好的模型的研究人员提供一个良好的起点。
论文地址:
https://arxiv.org/pdf/1901.08634.pdf
注:投稿请电邮至124239956@qq.com ,合作 或 加入未来产业促进会请加:www13923462501 微信号或者扫描下面二维码:

文章版权归原作者所有。如涉及作品版权问题,请与我们联系,我们将删除内容或协商版权问题!联系QQ:124239956






