中文最佳,哈工大讯飞联合发布全词覆盖中文BERT预训练模型
机器之心报道
参与:一鸣
昨日,机器之心报道了 CMU 全新模型 XLNet 在 20 项任务上碾压 BERT 的研究,引起了极大的关注。而在中文领域,哈工大讯飞联合实验室也于昨日发布了基于全词覆盖的中文 BERT 预训练模型,在多个中文数据集上取得了当前中文预训练模型的最佳水平,效果甚至超过了原版 BERT、ERINE 等中文预训练模型。
基于 Transformers 的双向编码表示(BERT)在多个自然语言处理任务中取得了广泛的性能提升。在预训练语言模型时,需要对语料进行 mask 操作,使模型在看不见 token 的情况下对 mask 的词语进行预测。
然而,基于单个 token 的 mask 方法训练中文语料,可能忽略了中文分词的作用。因此,如果能够 mask 词语中每一个组成的 token,可以更好的捕捉词与词的边界关系。
为了利用这种思想提升预训练模型在中文的表现,百度发布了知识增强的表示模型 ERNIE,在中文数据集的表现中超过了 BERT。近期,谷歌发布了基于全词覆盖(Whold Word Masking)的 BERT 预训练模型,则进一步提升了 BERT 模型的性能水平。
然而,由于全词覆盖的 BERT 模型的研究测试集中于国外公开数据集,缺乏一种中文语言的相关模型。昨天,哈工大讯飞联合实验室发布了全词覆盖的中文 BERT 预训练模型。模型在多个中文数据集上取得了当前中文预训练模型的最佳水平,效果甚至超过了原版 BERT、ERINE 等中文预训练模型。
论文地址:https://arxiv.org/abs/1906.08101
开源模型地址:https://github.com/ymcui/Chinese-BERT-wwm
哈工大讯飞联合实验室的项目介绍:https://mp.weixin.qq.com/s/EE6dEhvpKxqnVW_bBAKrnA

引言
基于 Transformer 的双向编码表示(Bidirectional Encoder Representations from Transformers)已经在多个自然语言处理数据集,如 SQuAD、CoQA、QuAC 等上取得了当前的最佳水平。而在这之后,谷歌发布了全词覆盖的预训练 BERT 模型。在全词 Mask 中,如果一个完整的词的部分 WordPiece 被 [MASK] 替换,则同属该词的其他部分也会被 [MASK] 替换。和原有的 BERT 模型相比,全词模型主要更改了原预训练阶段的训练样本生成策略。
由于谷歌官方发布的 BERT-base(Chinese)中,中文是以字为粒度进行切分,没有考虑中文需要分词的特点。应用全词 mask,而非字粒度的中文 BERT 模型可能有更好的表现,因此研究人员将全词 mask 方法应用在了中文中——对组成同一个词的汉字全部进行 [MASK]。模型使用了中文维基百科(包括简体和繁体)进行训练,并且使用了哈工大语言技术平台 LTP(http://ltp.ai)作为分词工具。和原版 BERT 中文模型,以及百度开源中文预训练模型 ERNIE 相比,全词覆盖的中文 BERT 预训练模型 BERT-wwm 在多个中文任务中取得了较好的表现。
全词 Mask 方法
Whole Word Masking (wwm) 是谷歌在 2019 年 5 月 31 日发布的一项 BERT 的升级版本,主要更改了原预训练阶段的训练样本生成策略。在过去的 BERT 预训练中,mask 方式为按照字粒度进行 mask,而全词模型则有所不同。

图 1:全词 mask 的方式。
如图 1 所示,全词 mask 需要首先对中文语料进行分词,然后对同属于一个词的每个 token 进行 mask 操作。这样一来,预训练模型并非预测被 mask 的单个 token,而是预测同一个词中的每一个被 mask 的 token。
数据集
论文采用了维基百科作为语料进行预训练,并同时使用了简体和繁体中文。清洗数据后,采用了 1360 万条数据作为输入。研究人员分别设置了两组预训练样本,一组设置的最长样本长度为 128,另一组为 512。除了使用全词 mask 方式以外,其他的数据清洗方式和原版 BERT 相同。
训练
研究人员认为,全词覆盖的 BERT 模型是原有 BERT 模型的改进版本,可以使 BERT 模型学习词的边界。因此,他们没有从零开始训练,而是在官方 BERT 中文模型(BERT-base Chinese)上训练。模型首先在最长样本长度为 128,批大小为 2560,使用 1e-4 的学习率,初始预热为 10% 的条件下训练了 100k 轮,然后在序列长度为 512,批大小为 384 的样本上进行了同样轮次的训练。训练使用了 LAMB 目标函数,而非 AdamWeightDecayOptimizer。训练使用的是 Google Cloud TPU v3,有 128G HBM。
实验结果对比
论文对比了原版的 BERT 模型,百度的 ERNIE 模型,以及本次论文的模型 BERT-wwm 在不同任务和数据集上的表现。论文在以下几个任务中使用中文数据集进行了测试。对于同一模型,研究人员运行模型 10 遍(不同随机种子),汇报模型性能的最大值和平均值。
篇章抽取型机器阅读理解
命名实体识别
文本分类
篇章抽取型机器阅读理解
1. CMRC 2018
CMRC 2018 数据集是哈工大讯飞联合实验室发布的中文机器阅读理解数据。根据给定问题,系统需要从篇章中抽取出片段作为答案,形式与 SQuAD 相同。
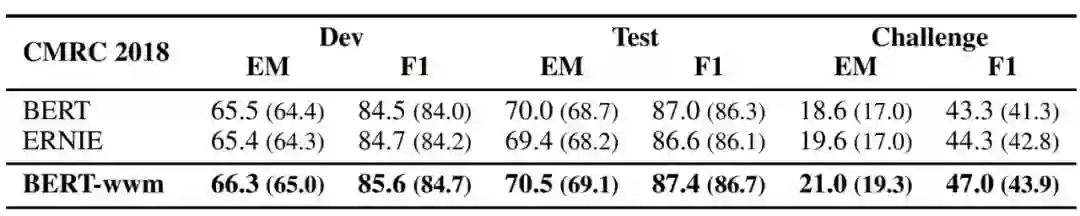
表 3:三个模型在 CMRC 2018 数据集上的表现。最好的学习率分别为:BERT (3e-5)、 BERT-wwm (3e-5)、ERNIE (8e-5)。
2. DRCD
DRCD 数据集由中国台湾台达研究院发布,其形式与 SQuAD 相同,是基于繁体中文的抽取式阅读理解数据集。
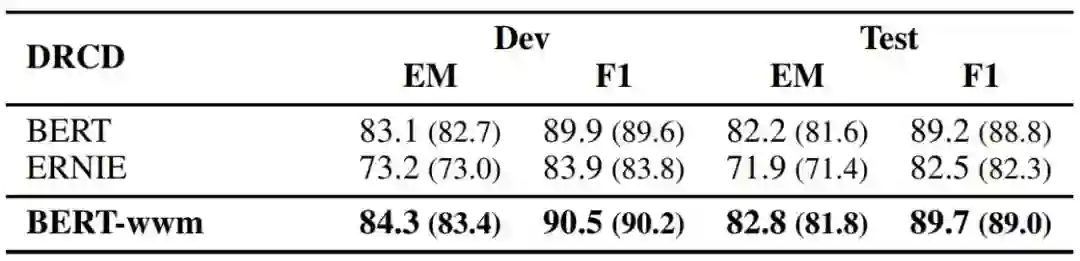
表 4:各个模型的表现。最好的模型学习率分别为:BERT (3e-5)、 BERT-wwm (3e-5)、ERNIE (8e-5)。
命名实体识别
中文命名实体识别(NER)任务中,论文采用了经典的人民日报数据以及微软亚洲研究院发布的 NER 数据。

表 6:在人民日报数据集(People Daily)和微软研究院 NER 数据集(NSRA-NER)上的表现。人民日报数据集上最好的模型学习率是:BERT (3e-5)、 BERT-wwm (3e-5)、 ERNIE (5e-5)。在微软亚洲研究院数据集上最好的模型学习率是:BERT (3e-5)、 BERT-wwm (4e-5)、 ERNIE (5e-5)。
文本分类
由清华大学自然语言处理实验室发布的新闻数据集,需要将新闻分成 10 个类别中的一个。

表 10:模型在清华新闻数据集的表现。最好的模型学习率分别是:BERT (2e-5)、BERT-wwm (2e-5)、 ERNIE (5e-5)。
更多模型在不同自然语言处理任务上的表现对比,可以参考原文论文。
模型使用
为了方便使用,论文作者们已经将 BERT-wwm 开源。论文说,模型的使用非常简单,只需要把官方提供的模型替换成新的模型即可,不需要改动其他代码。
下载
项目现已有 TensorFlow 和 PyTorch 两个版本。
1. TensorFlow 版本(1.12、1.13、1.14 测试通过)
Google:https://storage.googleapis.com/hfl-rc/chinese-bert/chinese_wwm_L-12_H-768_A-12.zip
讯飞云:https://pan.iflytek.com/link/4B172939D5748FB1A3881772BC97A898,密码:mva8
2. PyTorch 版本(请使用 PyTorch-BERT > 0.6,其他版本请自行转换)
Google:https://storage.googleapis.com/hfl-rc/chinese-bert/chinese_wwm_pytorch.zip
讯飞云:https://pan.iflytek.com/link/F23B12B39A3077CF1ED7A08DDAD081E3 密码:m1CE
3. 原版中文 BERT 模型
BERT-base, Chinese (Whole Word Masking) : 12-layer, 768-hidden, 12-heads, 110M parameters,地址:https://storage.googleapis.com/hfl-rc/chinese-bert/chinese_wwm_L-12_H-768_A-12.zip
4. 原版英文 BERT 模型
BERT-Large, Uncased (Whole Word Masking): 24-layer, 1024-hidden, 16-heads, 340M parameters,地址:https://storage.googleapis.com/bert_models/2019_05_30/wwm_uncased_L-24_H-1024_A-16.zip
BERT-Large, Cased (Whole Word Masking): 24-layer, 1024-hidden, 16-heads, 340M parameters,地址:https://storage.googleapis.com/bert_models/2019_05_30/wwm_cased_L-24_H-1024_A-16.zip
以 TensorFlow 版本为例,下载完毕后对 zip 文件进行解压得到:

其中 bert_config.json 和 vocab.txt 与谷歌原版**BERT-base, Chinese**完全一致。
使用建议
论文作者提供了一系列建议,在此供读者参考。
初始学习率是非常重要的一个参数(不论是 BERT 还是其他模型),需要根据目标任务进行调整。
ERNIE 的最佳学习率和 BERT/BERT-wwm 相差较大,所以使用 ERNIE 时请务必调整学习率(基于以上实验结果,ERNIE 需要的初始学习率较高)。
由于 BERT/BERT-wwm 使用了维基百科数据进行训练,故它们对正式文本建模较好;而 ERNIE 使用了额外的百度百科、贴吧、知道等网络数据,它对非正式文本(例如微博等)建模有优势。
在长文本建模任务上,例如阅读理解、文档分类,BERT 和 BERT-wwm 的效果较好。
如果目标任务的数据和预训练模型的领域相差较大,请在自己的数据集上进一步做预训练。
如果要处理繁体中文数据,请使用 BERT 或者 BERT-wwm。因为 ERNIE 的词表中几乎没有繁体中文。

深度Pro
理论详解 | 工程实践 | 产业分析 | 行研报告
机器之心最新上线深度内容栏目,汇总AI深度好文,详解理论、工程、产业与应用。这里的每一篇文章,都需要深度阅读15分钟。
今日深度推荐

点击图片,进入小程序深度Pro栏目
PC点击阅读原文,访问官网
更适合深度阅读
www.jiqizhixin.com/insight
每日重要论文、教程、资讯、报告也不想错过?



