谷歌更强 NLP 模型 XLNet 开源:20 项任务全面碾压 BERT!
▲点击上方 雷锋网 关注


XLNet 在 20 个任务上超过了 BERT 的表现,并在 18 个任务上取得了当前最佳效果
文 | 杨鲤萍
雷锋网 AI 科技评论按:去年 11 月份,谷歌研究团队在 GitHub 上发布了万众期待的 BERT,它不仅在 11 项 NLP 测试中刷新了最高成绩,甚至还表现出全面超越人类的惊人结果。
但 BERT 带来的震撼还未平息,今日又一个令众多 NLPer 兴奋的消息发布: CMU 与谷歌大脑提出的全新 XLNet 在 20 个任务上超过了 BERT 的表现,并在 18 个任务上取得了当前最佳效果!而更令人激动的是,目前 XLNet 已经开放了训练代码和大型预训练模型。雷锋网 AI 科技评论将其具体内容整理如下。

XLNet 信息发布
与基于自回归语言建模的预训练处理方法相比,基于自编码的预训练处理方法(比如 BERT)具有良好的双向上下文建模能力。然而,由于依赖于使用掩码破坏输入,BERT 忽略了掩码位置之间的依赖关系,并出现了预训练-微调( pretrain-finetune) 差异。
XLNet 则是基于 BERT 的优缺点,提出的一种泛化自回归预训练方法。它通过最大化因子分解顺序所有排列的期望似然来实现双向上下文的学习;通过自回归公式克服了 BERT 的局限性,并将来自 Transformer-XL(最先进的自回归模型) 的思想集成到预训练中,在长文本表示的语言任务中表现出了优异的性能。
首先,我们要理解两个概念:自回归 (AR) 语言建模和自编码 (AE)。
无监督表示学习在自然语言处理领域非常成功。通常,这些方法首先在大规模无标记文本语料库上对神经网络进行预训练,然后对下游任务的模型或表示进行微调。在这一共同的高层次思想下,不同的无监督预训练目标在相关文献中得到了探索。其中,自回归语言建模和自编码是两个最成功的预训练目标。
AR 语言建模是利用自回归模型估计文本语料库的概率分布。具体来说,给定一个文本序列 x = (x1, … ,xT),AR 语言模型将这种可能性分解为前向乘积或后向乘积。一个参数模型 (如神经网络) 被训练来对每个条件分布建模。由于 AR 语言模型仅被训练为编码单向上下文 (向前或向后),因此它在建模深层双向上下文时并没有产生效果。相反的是下游语言理解任务,通常需要双向上下文信息。这导致了 AR 语言建模和有效的预训练之间的差距。
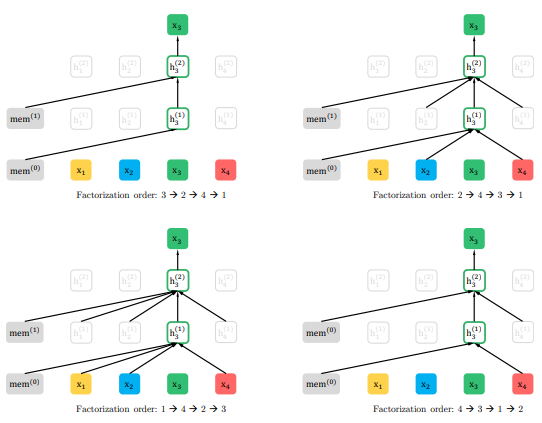
给定相同输入序列 x 但因子分解顺序不同的情况下,预测 x3 的置换语言建模目标的说明
相比之下,基于 AE 的预训练不执行显式密度估计,而是旨在从输入重构原始数据。而一个著名的例子就是 BERT,它采用了最先进的预训练方法。给定输入 token 序列,用一个特殊符号 [MASK] 替换其中的特定部分,并且训练模型从损坏的版本中恢复原 token。
由于密度估计不是目标的一部分,BERT 可以利用双向上下文进行重建。直接的好处就是这消除了 AR 语言建模中的双向信息差距,从而提高了性能。然而,BERT 在预训练使用的 [MASK] 等人工符号实际数据中并不存在,导致了预训练的网络差距。此外,由于预测的 token 在输入中被重新掩盖,BERT 无法像 AR 语言建模一样使用乘积规则对联合概率进行建模。
因此,针对现有语言预训练目标的优缺点,CMU 与谷歌大脑提出了将 AR 和 AE 的优点充分结合的泛化自回归预训练模型 XLNet。
首先,XLNet 不使用传统 AR 模型中固定的前向或后向因式分解顺序,而是最大化所有可能因式分解顺序的期望对数似然。因为是对因式分解顺序的排列操作,每个位置的上下文都可以由来自左右两边的 token 组成。在期望中,每个位置都要学会利用来自所有位置的上下文信息,即捕获双向上下文。
其次,作为一种泛化的 AR 语言模型,XLNet 不依赖于残余数据。因此,XLNet 不受 BERT 的预训练-微调差异的影响。同时,自回归目标也提供了一种自然的方法来使用乘积规则对预测 token 的联合概率执行因式分解,消除了 BERT 中做出的独立性假设。
除了一个新的预训练目标,XLNet 还改进了预训练的架构设计。
受 AR 语言建模最新进展的启发,XLNet 将 Transformer-XL 的分段重复机制和相对编码方案集成到预训练中,在较长文本序列的任务中提高了性能。需要注意的是,将 Transformer(-XL) 架构简单应用于基于排列的语言建模是不起作用的,因为分解顺序是任意的且目标是模糊的。作为一种解决方案,研究者们提出重新参数化 Transformer(-XL) 网络,以消除歧义。
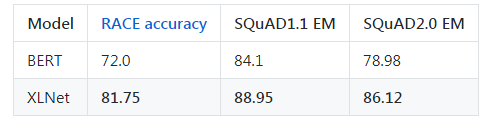
截至 2019 年 6 月 19 日,XLNet 在 20 个任务上超过了 BERT 的表现,并在 18 个任务上取得了当前最佳效果(state-of-the-art),包括机器问答、自然语言推断、情感分析和文档排序。
以下是 XLNet-Large 和 Bert-Large 的一些比较:
阅读理解任务
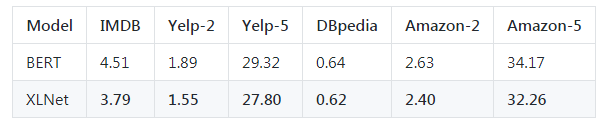
文本分类任务

ClueWeb09-B 文档排名任务
在最终的 20 项任务中,XLNet 的表现优于 BERT,并且在 18 项任务中取得了最先进的结果。
截至目前,已提供以下模式:
XLNet-Large, Cased:24-layer, 1024-hidden, 16-heads,
每个.zip 文件包含三个项:
TensorFlow checkpoint(xlnet_model.ckpt),包含预先训练的权重。
SentencePiece 模型 (spiece.model),用于 (de) 标记化。
一个配置文件 (xlnet_config.json),指定模型的超参数。
后续开发者还计划在不同的环境下继续发布更多的训练模型,包括:
基本模型——将在 2019 年 6 月底发布一个 XLNet-Base。
Uncased 模型——目前,Cased XLNet-Large 比 Uncased XLNet-Large 性能更好。开发者仍在观察与研究,当得出结论时,他们将马上发布 Uncased 模型。(预计时间不会太久)
在维基百科上进行微调的预训练模型,这可用于维基百科文本的任务,如 SQuAD 和 HotpotQA。
其他超参数配置的预训练模型,可以用于特定的下游任务。
与新技术关联的预训练模型。
相关链接
论文地址
https://arxiv.org/pdf/1906.08237.pdf
预训练模型及代码地址
https://github.com/zihangdai/xlnet

推荐阅读
▎为什么英特尔量产10nm不久后,台积电就能量产全球首个5nm?
▎马化腾评Facebook加密货币:技术成熟;ofo回应2.5亿元诉讼;苹果开始内测Apple Card