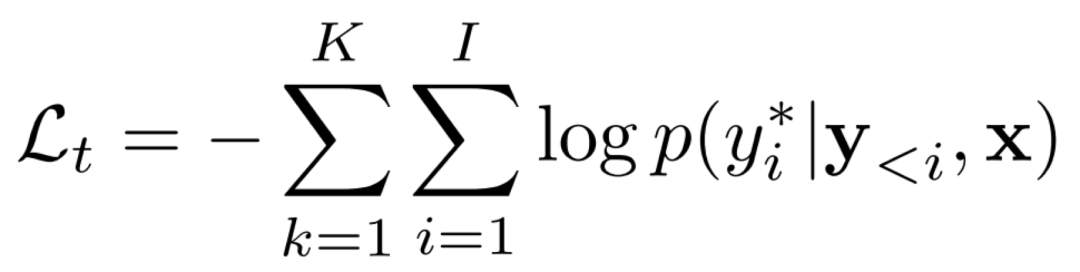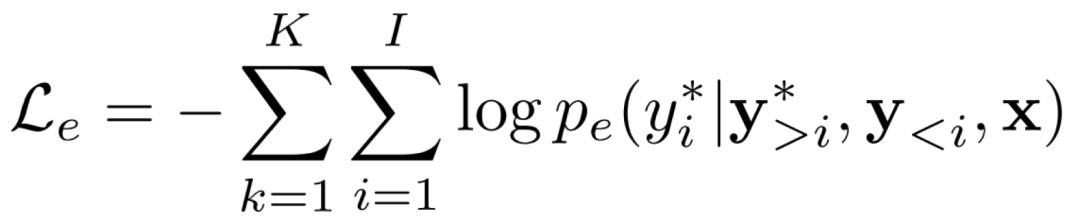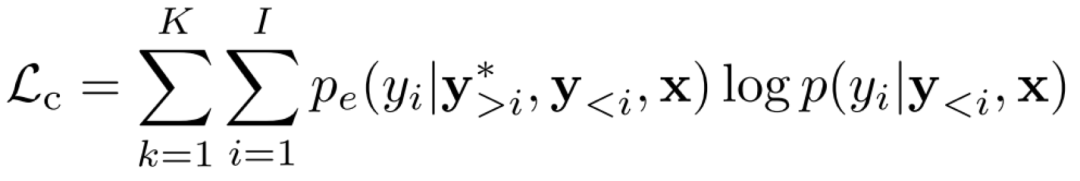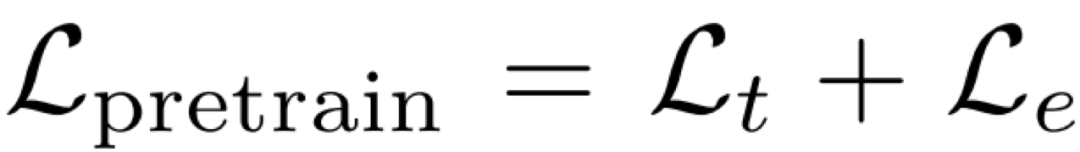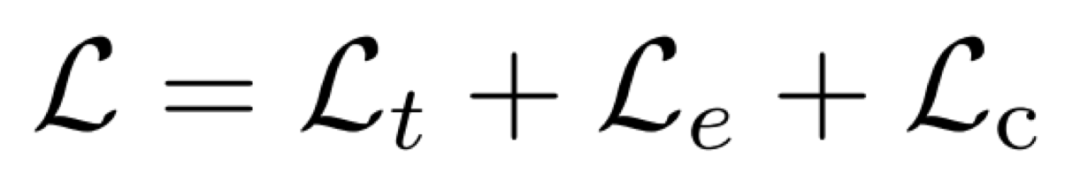本文是对计算所冯洋组完成,被 AAAI2020 录用的论文《Modeling Fluency and Faithfulness for Diverse Neural Machine Translation》进行解读,相关工作已开源。
![]()
论文链接:https://arxiv.org/pdf/1912.00178.pdf
代码链接:https://github.com/ictnlp/DiverseNMT
论文对当前神经机器翻译的现状进行了简要的概述,并分析了当前机器翻译模型训练策略的不足之处,提出在神经机器翻译模型中引入一个评估模块,对生成的译文从流利度和忠实度两个方面进行评估,并用得到的评估分数用来指导训练阶段译文的概率分布,而在测试的时候,可以完全抛弃该评估模块,采用传统的 Transformer 模型进行解码。最终实验证明取得了性能的提升。
神经机器翻译模型通常采用 Teacher Forcing 策略来进行训练,在该策略下,每个源句子都给定一个 GroundTruth,在每个时间步翻译模型都被强制生成一个 0-1 分布,即只有 Ground Truth 的词语的概率为 1,其他词语的概率为 0。通过这种方式,强制每个时间步生成对应的 GroundTruth 词语。而实际情况是即使是在训练集上,翻译模型也不能每次都输出 GroundTruth 词语作为翻译,甚至有时候 Ground Truth 词语的概率很小,但是,0-1 分布将所有的概率分布仅通过 Ground Truth 词语进行梯度回传,词表中其他的词语均被忽略,从而影响了参数训练。
上述问题导致了模型训练过程中不能很好的优化,甚至可能会强制模型优化到不符合预期的方向,而我们的方法针对这个问题,提出了一个新的方法来进行改进。
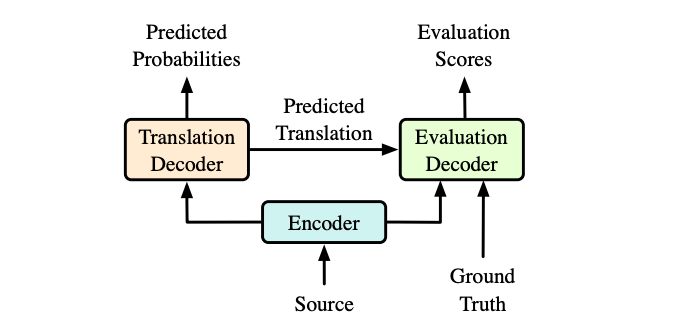
论文在 Transformer 的编码器-解码器结构的基础上添加了一个评估解码器,该解码器和 Transformer 的翻译解码器共享一个编码器。算法框架整体概括图如下所示:
![]()
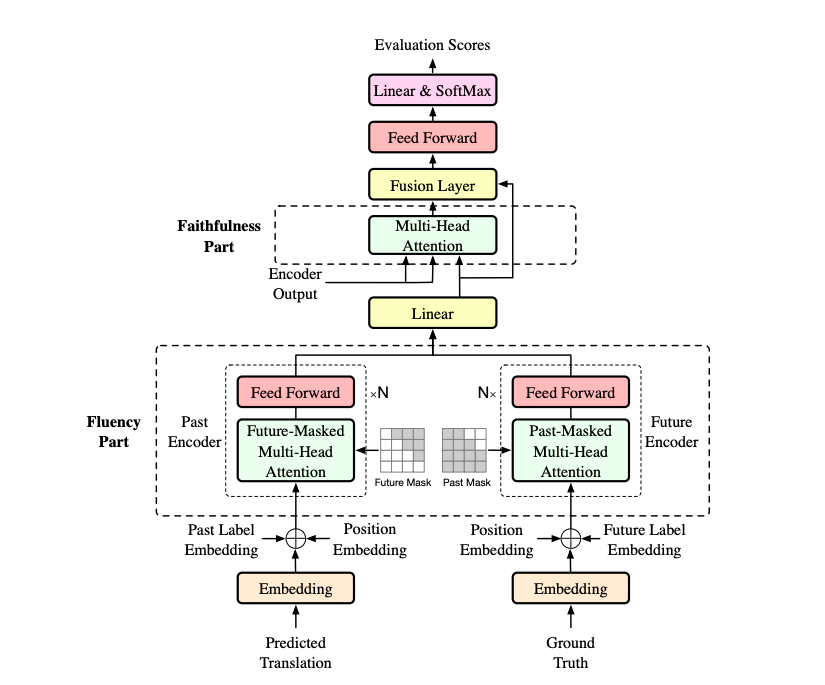
图中 Evaluation Decoder 即论文所提出的评估解码器,该解码器将 Transformer 的翻译解码器的输出、编码器的输出和 Ground Truth 三部分作为输入,而该评估解码器的输出则是评估分数和解码出的翻译。
![]()
在该评估解码器中,首先是 Fluency Part,即对于流利度的评估,论文分别采用了一个历史编码器和一个未来编码器,来对过去时间步生成的译文以及未来时间步的 Ground Truth 词语进行编码,将这两部分编码进行融合作为当前词语的上下文表示,将在上下文的情况下生成当前词语的概率作为流利度。
然后是 Faithfulness Part,即对于忠实度的评估,论文将其建模成一个翻译任务,即用当前词语的上下文表示检索出相关的源端表示,并将该源端表示翻译成当前词语的概率作为忠实度。
为了更好的融合流利度和忠实度并能对其权重进行自动调整,论文又引入了一个融合层,来将流利度部分生成的上下文表示和忠实度部分检索的源端表示进行融合,来计算其生成当前词语的概率。
最后,论文将评估模块生成的概率加入到损失函数中用于指导 Transformer 生成的翻译概率分布。
在训练过程中,我们的方法不仅联合训练翻译模块和评估模块,还增加一个额外的 loss 作为对翻译模块的指导。作为翻译模块,它的交叉熵损失为:
![]()
对于评估模块,它生成的翻译和 Ground Truth 之间的损失为:
![]()
作为增加的额外 loss,它代表着评估模块对翻译模块的指导。一般来说用 Kullback-Leibler(KL)散度作为损失以确保两个模型所绘制的分布彼此接近是一个常见的方法,但是在目标端绑定两个分布并不能达到最优,这有可能会阻碍模型找到最优点。所以论文关注翻译模块生成的单词,并使用评估模块来指导翻译模块给出的概率。这个损失也就是:
![]()
有了这个损失,如果生成的词恰好是 Ground Truth,那么翻译模块在 Ground Truth 的概率分布会更清晰,如果不是,那翻译模块会倾向于用评估模块给出的更高的置信度来加强翻译。
在训练过程中,论文首先预训练翻译模块和评估模块,训练损失为:
![]()
当接近收敛时,引入额外的 loss 做微调,损失函数为:
![]()
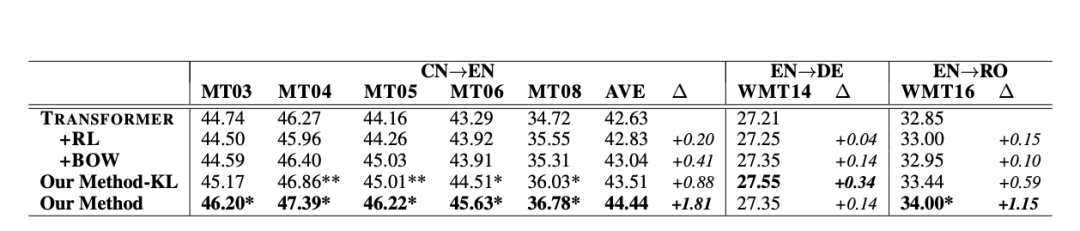
论文在 NIST 中-英、WMT2014 英-德和 WMT2016 英-罗马尼亚上进行了实验,论文与 Transformer 模型、强化学习模型以及词袋模型进行了比较,并实现了将 Kullback-Leibler(KL)散度作为模型额外 loss 的对比系统。主实验结果如下:
![]()
论文的方法在中-英、英-罗马尼亚语言对上相比于所有的基线系统翻译效果均取得了显著提升。
综合来看论文方法相比 KL 方法能够帮助模型达到更好的效果,所以论文最终采用的方法更加的合理。
而在英-德上,两种方法都提升不明显,这有可能是因为英德的数据已经足够大,所以论文方法带来的收益就难以体现。
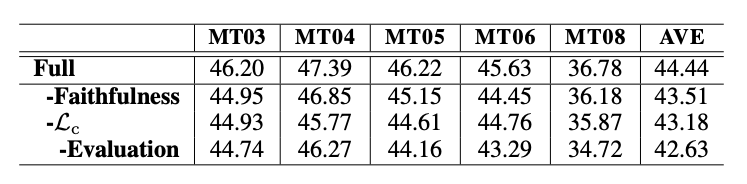
首先是消融实验
,分别消去论文提出的几个模块后,模型表现依次下降,这证实了论文提出的模块都对帮助模型生成更好的翻译起着重要的作用,结果如下:
![]()
为了证明评估模块有能力指导翻译模块生成更好的翻译,论文将 Ground Truth 作为已知分别输入到两个模块来生成翻译。在 NIST 中-英和 WMT 英-德的两个实验结果表明评估模块比翻译模块的结果有很大优势,这也证实了评估模块有能力指导翻译模块进行翻译。结果如下:
![]()
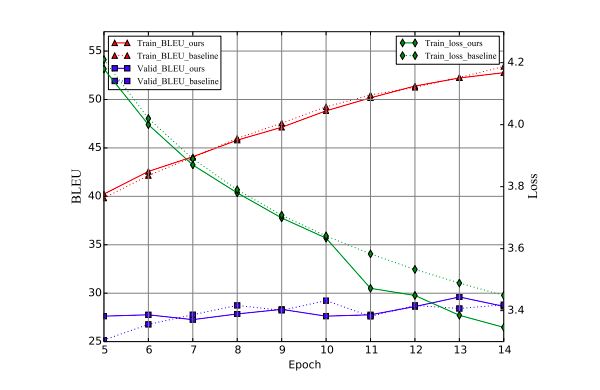
为了证明添加的损失的合理性,论文观察了训练过程中的 Loss 和 BLEU 值,结果表明当模型收敛时,论文方法比基线模型有更高的验证机 BLEU 值和更低的训练 Loss。数据如下:
![]()
为了证明论文方法是在流利度和忠实度两个方面进行的提升,论文计算了提出的方法和基线模型生成的译文的 n-gram 值,以及译文的 Embedding 和 Ground Truth 的 Embedding 之间的余弦相似度。
结果表明,论文提出的方法拥有更高的 n-gram 值,并且随着 n 值的增大,对比基线模型的 n-gram 值的提升越大,这证明了论文方法在流利度上有大幅提升;
而对比基线模型,论文方法同样拥有更高的余弦相似度,这证明论文方法在语义上更贴近 Ground Truth,即提升了忠实度。
论文提出了一个评估模块来从流利度和忠实度两个方面来评估翻译模块,并指导其生成更优的翻译。实验证明该方法在多个数据集上达到了更好的效果,并且生成了在目标端更流利、对源端更忠实的翻译。
更多AAAI 2020信息,将在「AAAI 2020 交流群」中进行,加群方式:添加AI研习社顶会小助手(AIyanxishe2),备注「AAAI」,邀请入群。
![]()
AAAI 2020 论文解读系列:
13. [中科院自动化所] 通过解纠缠模型探测语义和语法的大脑表征机制
14. [中科院自动化所] 多模态基准指导的生成式多模态自动文摘
15. [南京大学] 利用多头注意力机制生成多样性翻译
16. [UCSB 王威廉组] 零样本学习,来扩充知识图谱(视频解读)
17. [上海交大] 基于图像查询的视频检索,代码已开源!
18. [奥卢大学] 基于 NAS 的 GCN 网络设计(视频解读)
19. [中科大] 智能教育系统中的神经认知诊断,从数据中学习交互函数
20. [北京大学] 图卷积中的多阶段自监督学习算法
21. [清华大学] 全新模型,对话生成更流畅、更具个性化(视频解读,附PPT)
22. [华南理工] 面向文本识别的去耦注意力网络
23. [自动化所] 基于对抗视觉特征残差的零样本学习方法
![]()
![]()
![]()
![]() 点击“阅读原文” 前往 AAAI 2020 专题页
点击“阅读原文” 前往 AAAI 2020 专题页