【AAAI论文】阿里提出新图像描述框架,解决梯度消失难题

新智元推荐
来源:阿里巴巴AI Labs
编辑:克雷格
【新智元导读】阿里AI Labs在最近的论文中提出了一种粗略到精细的多级图像描述预测框架,该框架由多个解码器构成,其中每一个都基于前一级的输出而工作,从而能得到越来越精细的图像描述。通过提供一个实施中间监督的学习目标函数,其学习方法能在训练过程中解决梯度消失的难题。

现有的图像描述方法通常都是训练一个单级句子解码器,这难以生成丰富的细粒度的描述。另一方面,由于梯度消失问题,多级图像描述模型又难以训练。我们在本论文中提出了一种粗略到精细的多级图像描述预测框架,该框架由多个解码器构成,其中每一个都基于前一级的输出而工作,从而能得到越来越精细的图像描述。通过提供一个实施中间监督的学习目标函数,我们提出的学习方法能在训练过程中解决梯度消失的难题。
尤其需要指出,我们使用了一种强化学习方法对我们的模型进行优化,该方法能够利用每个中间解码器的测试时间推理算法的输出及其前一个解码器的输出来对奖励进行归一化,这能一并解决众所周知的曝光偏差问题(exposure bias problem)和损失-评估不匹配问题(loss-evaluation mismatch problem)。我们在 MSCOCO 上进行了大量实验来评估我们提出的方法,结果表明我们的方法可以实现当前最佳的表现。
图像描述的困难之处是让设计的模型能有效地利用图像信息和生成更接近人类的丰富的图像描述。在自然语言处理近期进展的推动下,当前的图像描述方法一般遵循编码-解码框架。这种框架由一个基于卷积神经网络(CNN)的图像编码器和基于循环神经网络(RNN)的句子解码器构成,有多种用于图像描述的变体。这些已有的图像描述方法的训练方式大都是根据之前的基本真值词(ground-truth words)和图像,使用反向传播,最大化每个基本真值词的可能性。
这些已有的图像描述方法存在三个主要问题。第一,它们很难生成丰富的细粒度的描述。第二,在训练和测试之间存在曝光偏差。第三,存在损失与评估的不匹配问题。
考虑到使用单级模型生成丰富的图像描述的巨大挑战性,我们在本论文中提出了一种粗略到精细的多级预测框架。我们的模型由一个图像编码器和一系列句子解码器构成,可以重复地生成细节越来越精细的图像描述。但是,直接在图像描述模型中构建这样的多级解码器面临着梯度消失问题的风险。Zhang, Lee, and Lee 2016; Fu, Zheng, and Mei 2017 等在图像识别上的研究工作表明监督非常深度的网络的中间层有助于学习,受这些研究的启发,我们也为每级解码器实施了中间监督。
此外,Rennie et al. 2017 这项近期的图像描述研究使用了强化学习(RL)来解决损失-评估不匹配问题,并且还在训练中包含推理过程作为基准来解决曝光偏差问题;我们也设计了一种类似的基于强化学习的训练方法,但是将其从单级扩展成了我们的多级框架,其中每级都引入了作为中间监督的奖励。尤其需要指出,我们使用了一种强化学习方法对我们的模型进行优化,该方法能够利用每个中间解码器的测试时间推理算法的输出及其前一个解码器的输出来对奖励进行归一化。
此外,为了应对我们的粗略到精细学习框架,我们采用了一种层叠式注意模型来为每个阶段的词预测提取更细粒度的视觉注意信息。图 1 给出了我们提出的粗略到精细框架的示意图,它由三个层叠的长短期记忆(LSTM)网络构成。第一个 LSTM 生成粗尺度的图像描述,后面的 LSTM 网络用作精细尺度的解码器。我们模型中每一级的输入都是前一级所得到的注意权重和隐藏向量,这些被用作后一级的消岐线索。由此,每一级解码器就会生成注意权重和词越来越精细的句子。
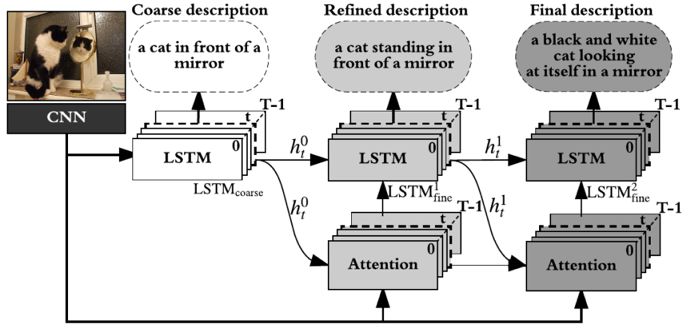
图 1:我们提出的粗略到精细框架示意图。我们的模型由一个图像编码器(CNN)和一系列句子解码器(基于注意的 LSTM 网络)构成。该模型以图像为输入,能够从粗略到精细不断细化图像描述。这里我们展示了两级式的图像描述渐进提升(灰色和深灰色)。
本工作的主要贡献包括:(a)一种用于图像描述的粗略到精细框架,可以使用越来越细化的注意权重逐渐增大模型复杂度;(b)一种使用归一化后的中间奖励直接优化模型的强化学习方法。实验表明我们的方法在 MSCOCO 上表现出色。
在本论文中,我们考虑了学习生成图像描述的问题。我们的算法构建了一个粗略到精细模型,它具有与单级模型一样的目标,但在输出层和输入层之间具有额外的中间层。我们首先根据输入图像和目标词的黄金历史,通过最大化每个连续目标词的对数似然而对该模型进行训练,然后再使用句子层面的评估指标对模型进行优化。结果,每个中间句子解码器会预测得到越来越细化的图像描述,最后一个解码器的预测结果用作最终的图像描述。
图像编码
我们首先将给定图像编码成空间图像特征。具体来说,我们从 CNN 的最后卷积层提取图像特征,然后使用空间自适应平均池化将这些特征的尺寸调整成固定尺寸的空间表示。
粗略到精细解码
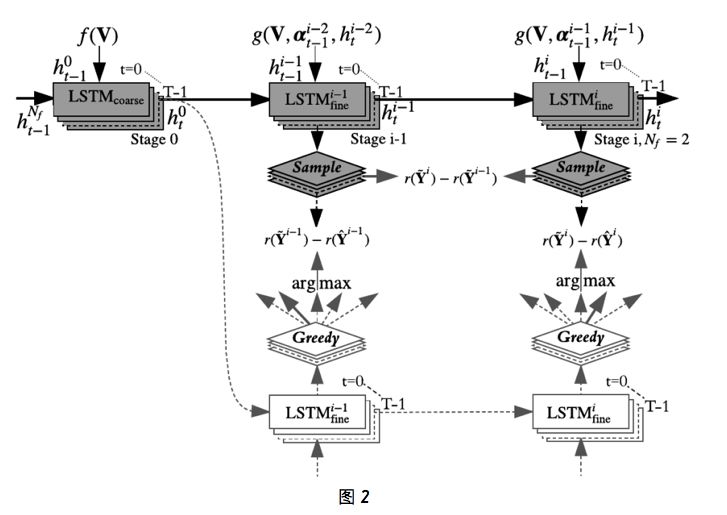
整体的粗略到精细句子解码器由一个粗略解码器和一系列基于注意的精细解码器构成,这些解码器可以根据来自前一个解码器的线索来得到每个词预测的细化后的注意图(attention map)。我们模型的第一级是一个粗略解码器,能根据全局图像特征预测得到粗略的描述。在后续阶段,每一级都是一个精细解码器,可以基于图像特征和前一级的输出而预测得到更好的图像描述。尤其需要指出,我们使用了前一级的注意权重来提供后一级词预测的区域信念。也就是说,我们以多级方式解码图像特征,其中每级的预测结果都是对前一级预测结果的精细化。
图 2 给出了我们提出的粗略到精细解码架构,其中每一级之后都使用了中间监督(奖励)。上面一行(灰色)包含一个粗略解码器(左)和两个层叠的基于注意的精细解码器(处于训练模式下);下面一行给出了处于推理模式(贪婪解码)下的精细解码器,用于计算奖励以将中间监督整合进来。
粗略解码器。我们首先在第一级的粗略搜索空间中解码,我们在这里使用一个 LSTM 网络学习一个粗略解码器,称为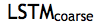
精细解码器。在后续的多级中,每个精细解码器都会再次基于图像特征以及来自前一个 LSTM 的注意权重和隐藏状态来预测词。每个精细解码器都由一个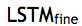
层叠式注意模型。如前所述,我们的粗略解码器基于全局图像特征生成词。但是在很多情况下,每个词都只与图像中的很小一部分有关。由于每次预测时图像中的无关区域会引入噪声,所以为词预测使用全局图像特征会得到次优的结果。因此,我们引入了注意机制,这能显著提升图像描述的表现。注意机制通常会得到一个空间图(spatial map),其中突出显示了与每个预测词相关的图像区域。为了为词预测提取更细粒度的视觉信息,我们在本研究中采用了一种层叠式注意模型来逐渐滤除噪声和定位与词预测高度相关的区域。在每个精细处理级中,我们的注意模型都会对图像特征和来自前一级的注意权重进行操作。
学习
上面描述的粗略到精细方法能得到一种深度架构。训练这样一种深度网络可能很容易出现梯度消失问题,即梯度的幅度会在反向传播通过多个中间层时强度减小。解决这种问题的一种自然方法是将监督训练目标整合到中间层中。每一级粗略到精细句子解码器的训练目标都是重复地预测词。我们首先通过为每一级定义一个最小化交叉熵损失的损失函数来训练网络。
但是,只使用这里的损失函数进行训练是不够的。
为了优化每一级的评估指标,我们将图像描述生成过程看作是一个强化学习问题,即给定一个环境(之前的状态),我们想要智能体(比如 RNN、LSTM 或 GRU)查看环境(图像特征、隐藏状态和之前的词)并做出动作(预测下一个词)。在生成了一个完整句子之后,该智能体将观察句子层面的奖励并更新自己的内部状态。
实验
数据集和设置
我们在 MSCOCO 数据集上评估了我们提出的方法。
用于比较的基准方法
为了了解我们提出的方法的有效性,我们对以下模型进行了相互比较:
LSTM 和
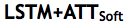

Stack-Cap 和 Stack-Cap*。Stack-Cap 是我们提出的方法,Stack-Cap* 是一种简化版本。Stack-Cap 和 Stack-Cap* 的架构相似,只是 Stack-Cap 应用了我们提出的层叠式注意模型而不是独立的注意模型。
定量分析
在实验中,我们首先使用标准的交叉熵损失对模型进行了优化。我们报告了我们的模型和基准模型在 Karpathy test split 上的表现,如表 1 所示。注意这里报告的所有结果都没有使用 ResNet-101 的微调。
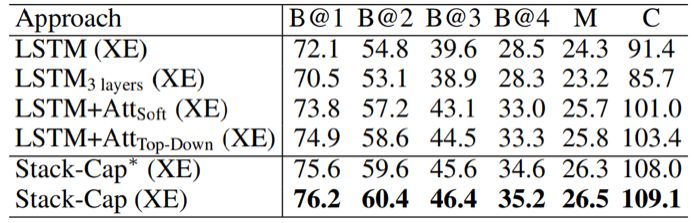
表 1:在 MSCOCO 上的表现比较,其中 B@n 是指 BLEU-n,M 指 METEOR,C 指 CIDEr。这里所有的值都是百分数(加粗数字是最佳结果)。
在使用交叉熵损失优化了模型之后,我们又使用基于强化学习的算法针对 CIDEr 指标对它们进行了优化。表 2 给出了使用 SCST(Rennie et al. 2017)为 CIDEr 指标优化的 4 种模型的表现以及使用我们提出的粗略到精细(C2F)学习方法优化的 2 种模型的表现。可以看到我们的 Stack-Cap 模型在所有指标上都有显著的优势。
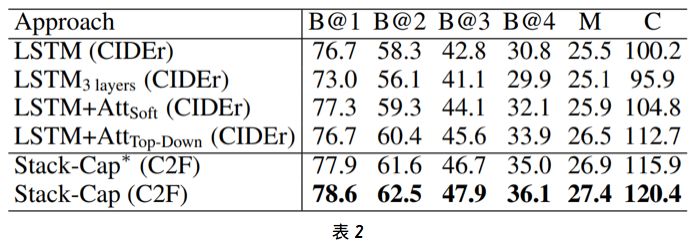
表 3 比较了我们的 Stack-Cap(C2F)模型与其它已有方法在 MSCOCO Karpathy test split 上的结果。Stack-Cap 在所有指标上都表现最佳。
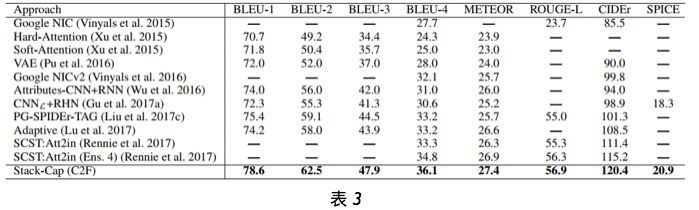
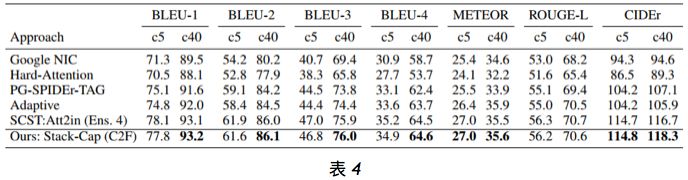
在线评估。表 4 报告了我们提出的使用粗略到精细学习训练的 Stack-Cap 模型在官方 MSCOCO 评估服务器上的表现。可以看到,与当前最佳的方法相比,我们的方法非常有竞争力。注意,SCST:Att2in (Ens. 4) 的结果是使用 4 个模型联合实现的,而我们的结果是使用单个模型生成的。
定性分析
为了表明我们提出的粗略到精细方法可以逐级生成越来越好的图像描述,并且这些图像描述与自适应关注的区域有良好的关联,我们对生成的描述中词的空间注意权重进行了可视化。我们以 16 的采样系数对注意权重进行了上采样,并使用了一个高斯过滤器使之与输入图像一样大小,并将所有上采样后的空间注意图叠加到了原始输入图像上。
图 3 给出了一些生成的描述。通过多个注意层逐步进行推理,Stack-Cap 模型可以逐渐滤除噪声和定位与当前词预测高度相关的区域。可以发现,我们的 Stack-Cap 模型可以学习到与人类直觉高度对应的对齐方式。以第一张图像为例,对比粗略级生成的描述,由第一个精细解码器生成的首次细化后的描述中包含“dog”,第二个精细解码器不仅得到了“dog”,还识别出了“umbrella”。
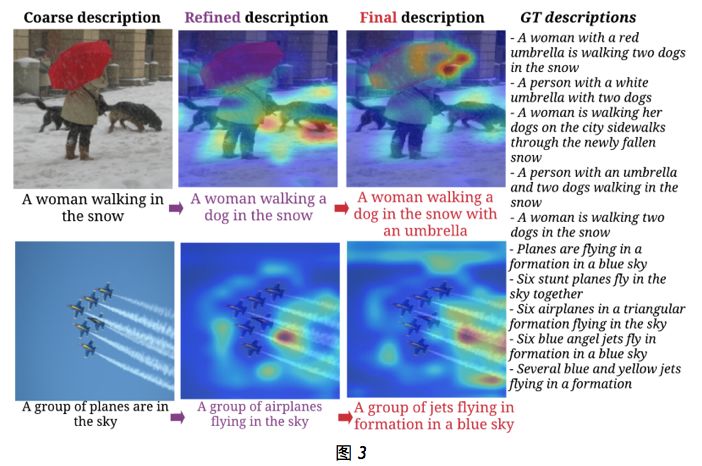
此外,我们的方法还能生成更为描述性的句子。比如,喷气机图像的注意可视化表明 Stack-Cap 模型可以查询这些喷气机的关系以及它们身后长长的烟雾尾迹,因为这些突出区域有很高的关注权重。这个例子以及其它案例说明层叠式注意可以为序列预测更有效地探索视觉信息。也就是说,我们使用层叠式注意的方法可以从粗略到精细地考虑图像中的视觉信息,这与通常通过粗略到精细流程理解图像的人类视觉系统很相似。
原文下载地址:
https://102.alibaba.com/downloadFile.do?file=1518074198430/AAAI2018Stack-Captioning_Coarse-to-Fine%20Learning%20for%20Image%20Captioning_12213(1).pdf
【2018 新智元 AI 技术峰会倒计时 27 天】大会早鸟票已经售罄,现正式进入全额票阶段。
2017 年,作为人工智能领域最具影响力的产业服务平台——新智元成功举办了「新智元开源 · 生态技术峰会」和「2017AIWORLD 世界人工智能大会」。凭借超高活动人气及行业影响力,获得 2017 年度活动行 “年度最具影响力主办方” 奖项。
其中「2017AIWORLD 世界人工智能大会」创人工智能领域活动先河,参会人次超 5000;开场视频在腾讯视频点播量超 100 万;新华网图文直播超 1200 万;
2018 年的 3 月 29 日,新智元再汇 AI 之力,共筑产业跃迁之路,将在北京举办2018 年中国 AI 开年盛典——2018 新智元 AI 技术峰会。本次峰会以 “产业 · 跃迁” 为主题,邀请谷歌、微软、亚马逊、BAT、科大讯飞、京东和华为等企业重量级嘉宾,共同研讨技术变革,助力领域融合发展。
新智元诚挚邀请关心人工智能行业发展的各界人士3月29日亲临峰会现场,共同参与这一跨领域的思维碰撞。
关于大会,请关注新智元微信公众号或访问活动行页面:http://www.huodongxing.com/event/8426451122400
【扫一扫或点击阅读原文抢购大会门票】
2018 新智元 AI 技术峰会购票二维码:

加入社群
新智元 AI 技术 + 产业社群招募中,欢迎对 AI 技术 + 产业落地感兴趣的同学,加小助手微信号: aiera2015_1 入群;通过审核后我们将邀请进群,加入社群后务必修改群备注(姓名 - 公司 - 职位;专业群审核较严,敬请谅解)。
此外,新智元 AI 技术 + 产业领域社群 (智能汽车、机器学习、深度学习、神经网络等) 正在面向正在从事相关领域的工程师及研究人员进行招募。
加入新智元技术社群 共享 AI + 开放平台



