中科院自动化所提出 BIFT 模型:面向自然语言生成,同步双向推断

AI 科技评论按,本文作者中国科学院自动化研究所张家俊,他为 AI 科技评论撰写了基于 BIFT 的独家解读。正文内容如下:
前言
概括地讲,自然语言处理包括两大任务:自然语言文本理解和自然语言文本生成。自然语言文本理解就是让机器洞悉人们所言之意,自然语言文本生成旨在让机器像人一样表达和说话。文本理解的关键在于对已知文本的上下文表征和建模,而文本生成的本质是在文本理解的基础上准确流畅地产生自然语言文本。
自然语言理解既可以利用上文信息也可以利用下文信息,高效的双向编码能力正是 BERT 成功的关键因素之一。但是,自然语言生成由于都默认自左往右地逐词产生文本输出,预测某个时刻的输出只能利用上文的历史信息而无法访问还未生成的未来信息。例如将汉语句子“有五个人”自动翻译为英语时,从左到右的理想预测结果是“There”、“are”、“five” 和“persons”。虽然“persons”能够判别第二个词语应该是“are”而不是“is”,但是由于在预测第二个单词时,只能依赖已经产生的单词“There”,而无法参考还未生成的“five”和“persons”。这个简单的例子就能反映出传统自左往右自然语言生成的弊端。我们提出的 BIFT 希望打破这种文本生成模式,采用同步双向推断模型为每个时刻的预测同时提供历史信息和未来知识。通过大量实验,我们发现 BIFT 相比于当前最好的模型,在几乎不牺牲效率的前提下能够获得十分显著的性能提升, 并且已经成功应用于在线机器翻译系统,相关代码和使用说明请参考 Github 链接:https://github.com/ZNLP/sb-nmt
使用 BIFT 一词就是希望让大家联想到 2018 年风靡全球的自然语言处理神器 BERT(Bidirectional Encoder Representation from Transformer)。将 BIFT 和 BERT 放在一起,我们期望更好地探讨两者的联系和区别。如果不想详细了解,记住一句话那就可以了:BERT 着眼于编码器 Encoder,目标是提升自然语言理解的能力;BIFT 改变解码范式,旨在改善自然语言生成的效果。
BIFT 是我们近一年来的研究工作成果,在 2018 年 10 月份 BERT 诞生时,我们其中的一项工作(Synchronous Bidirectional Neural Machine Translation)已经被 Transactions on ACL 条件接收。BERT 非常伟大,在十多个自然语言理解任务中刷到最高分。相比而言,我们当时的工作只是在机器翻译任务上做出了卓有成效的尝试,所以肯定无法与 BERT 相提并论,只是联系在一起更容易描述和让大家理解。BIFT 目前在机器翻译和自动摘要两个自然语言生成任务(尤其是机器翻译任务)中取得了显著效果,我们希望 BIFT 在其他自然语言生成任务中也能大放异彩。
BIFT 和 BERT 有一个共同点:都是基于 2017 年 Google 提出的完全注意机制驱动的 Transformer 框架(如图 1 所示)。编码器 Encoder 对输入文本进行深层语义表示,解码器 Decoder 依据输入文本的语义表示产生输出文本。编码器和解码器都是由多层网络堆积而成,编码器中的每一层主要包括自我注意机制(Self-Attention)和前馈网络(Feed-Forward Network)两个子层,每个子层后面会紧接一个正则化操作,并且层与层之间会有残差连接。相比编码器,解码器中的每一层有两点不同,一方面,自我注意机制只能利用已经生成的部分历史前缀信息,而需要屏蔽还未产生的未来信息;另一方面,自我注意机制和前馈网络之间还包括一个建模输出和输入关系的 Encoder-Decoder 注意机制。
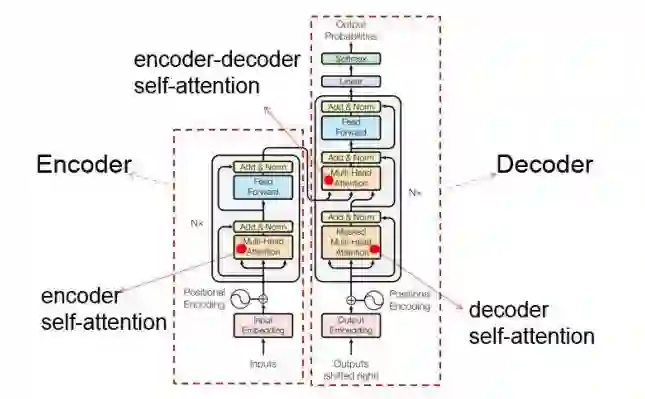
图 1:Transformer 框架
从 Transformer 的框架可以看出,自我注意是其有别于循环神经网络和卷积神经网络的本质。以汉语到英语的机器翻译任务为例,图 2 和图 3 展示了编码器和解码器中自我注意机制的工作流程。图 2 显示的编码模块中,对于输入的单词序列,每个单词首先映射为低维实数向量,① 表示第一个单词与包括自身的所有单词计算相关度,并对所有单词的向量表示依据相关度进行加权获得序列第一个单词更深一层的语义表示;② 采用相同的方式,平行计算输入序列中每个位置更深一层的语义表示;③ 利用相同的自我注意机制可以生成多层语义表示。
图 3 显示的解码模块中,第一个输出单词为开始符,与编码器中每个位置的语义表示进行注意机制计算并加权得到第二层语义信息,① 采用相同的方式可以获得更多层的语义信息,最后利用 softmax 函数预测下一个时刻的输出“there”;② 预测下一个输出单词时,首先需要进行输出端的注意机制计算过程,然后再与编码器的语义表示进行注意机制计算;③ 进行相同的操作获得多层语音信息,再由 softmax 函数给出下一个时刻应该输出的单词“are”;④ 重复 ② 和 ③ 最终生成整个文本序列(一般直到产生结束符“</s>”,停止解码过程)。
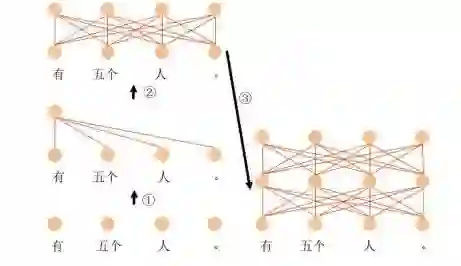
图 2:Transformer 的编码器示意图
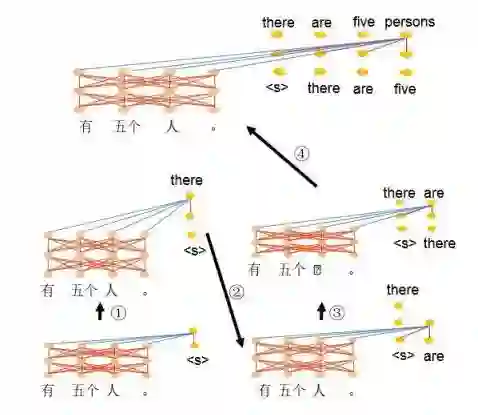
图 3:Transformer 的解码器示意图
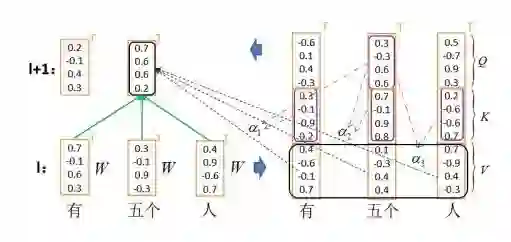
图 4: Transformer 编码器的 Self-attention 工作机理
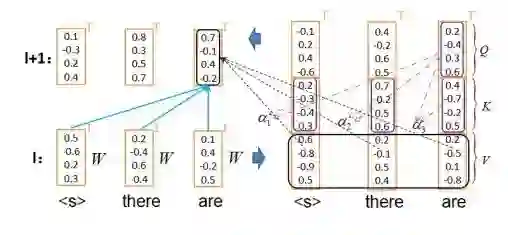
图 5: Transformer 解码器的 Self-attention 工作机理
图 4 与图 5 分别展示了 Transformer 编码器和解码器中自我注意机制的计算方法:首先将词向量转化为具有相同维度的查询 Q、键 K 和值 V,然后用 Q 与 K 计算相关性,最后用相关性对 V 加权获得某个位置更深一层的语义表示。两张图的核心区别体现在图 4 编码器中每个位置的上层语义表示学习都可以利用上文和下文信息,而图 5 解码器中每个位置的上层语义表示学习只能利用已经产生的历史信息。
BERT
BERT 无疑是 2018 年自然语言处理领域最令人兴奋的模型。BERT 以 Transformer 的编码器 Encoder 为模型框架的核心,为了处理自然语言理解中的分类和序列标注两大任务,BERT 在 Transformer 编码器的最上层添加一个特殊分类器(图 6 所示)或为每个位置添加一个分类器(图 7 所示)。
BERT 的成功主要可以归结到四点因素:(1)预训练(pre-training)和精细调优(fine-tuning)的模型架构;(2)以 Transformer 深层双向编码器为模型核心;(3)以 Masked LM 和下个句子预测任务构建优化目标函数;(4)超大规模训练数据的利用。对比 ELMo(Embeddings from Language Model)和 GPT(Generative Pre-trained Transformer)发现,BERT 最大的优势之一在于使用了 Transformer 中基于自我注意机制的双向编码模型。
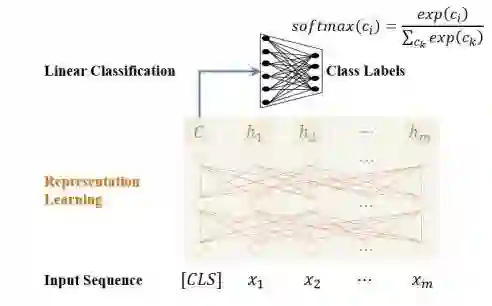
图 6:BERT 中的分类模型
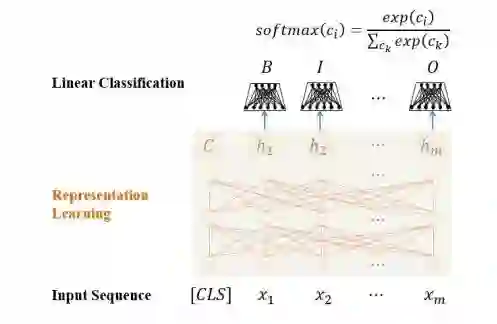
图 7: BERT 中的序列标注模型
BIFT
图 8 简单展示了自然语言文本理解与自然语言文本生成之间的架构差别。自然语言文本理解中,输入文本是给定的,从而双向编码是很自然的选择。对于自然语言文本生成而言,由于输出文本不可预知,传统自左往右的解码方式仅仅能充分利用已经产生的历史信息,而无法利用还未生成的未来信息。于是,我们便提出一个如图 9 所示的大胆想法:能否像双向编码一样,设计一种双向解码机制,从而有效建模历史和未来信息?

图 8:自然语言文本理解与自然语言文本生成的对比示意图
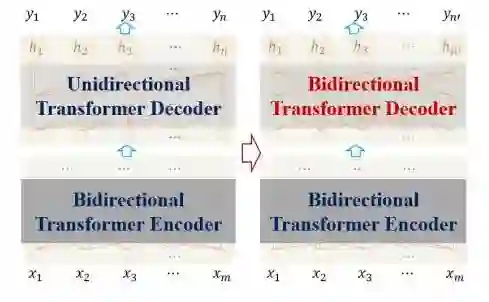
图 9:单向解码和双向解码的对比示意图
1. 双向推断的概率模型
自然语言文本生成任务中,我们一般采用下面的式子建模输出文本 y=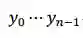
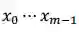
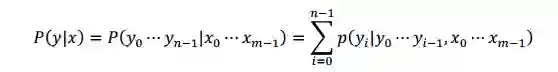
这就是典型的从左往右的文本生成范式。当然,也可以采用从右往左的文本生成范式:
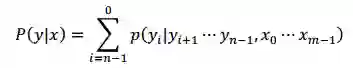
但是上述两种方式都无法同时利用历史和未来信息。那么能否在预测 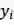
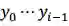
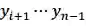
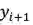
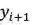
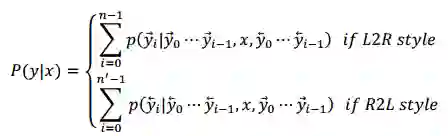
我们的想法可以由图 10 简要说明:自然语言文本生成模型保持从左往右和从右往左的同步解码,但是在每个时刻两个方向的解码都进行充分的交互。预测 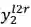
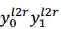
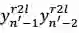
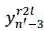
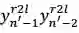
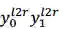
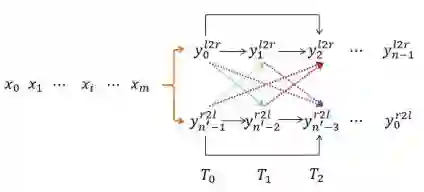
图 10:同步双向推断的解码机制示意图
以预测 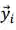
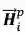
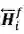
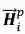
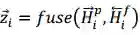
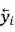
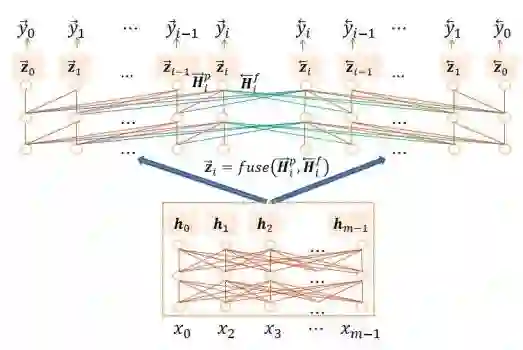
图 11:同步双向推断模型
2. 双向推断模型的柱搜索解码算法
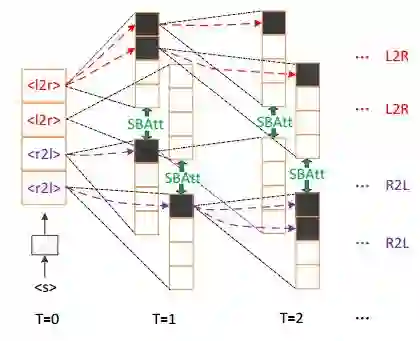
图 12:同步双向推断模型的柱搜索算法示意图
图 12 给出了同步双向推断模型的柱搜索解码算法示意图。以柱大小 b=4 为例,每一时刻 L2R 和 R2L 方向利用同步双向注意机制 SBAtt 进行同步解码,并分别保留 b/2 个最优候选。如果当前时刻预测结果为结束符〈/s〉,则将该候选放入完整候选列表。当完整候选列表达到 b 的规模,则停止解码,输出列表中概率最大的候选作为最终输出。如果最终结果来自于 R2L 方向,则需要在输出前对结果进行逆序操作。详细算法流程见算法 1。
算法 1:同步双向推断模型的柱搜索解码算法

3. 参数训练
由于同步双向推断模型在解码过程中,L2R 和 R2L 方向同步并行解码,那么训练过程中针对平行句对(x,y),L2R 方向希望生成标准答案 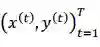
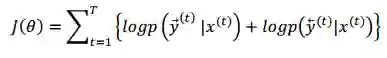
当训练过程中计算 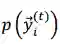
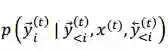
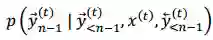
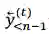
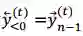
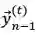
在两阶段法中,我们首先在训练数据上独立学习 L2R 和 R2L 推断模型。然后 L2R 和 R2L 模型分别用来对训练数据的输入端进行解码,分别得到 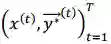
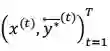
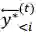
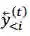

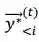
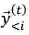
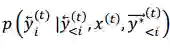
在微调法中,我们首先训练一个如下述公式所示的没有交互的 L2R 和 R2L 平行推断模型,其中每个训练实例是一个三元组 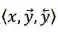
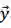
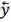
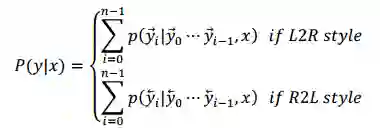
上述训练过程收敛时,我们从训练数据中随机选取少量的平行句对(譬如 10% 的数据),并且利用该初始模型解码这些数据的输入序列,得到新的三元组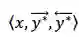
4. 实验结果
实际上,我们将同步双向推断模型不仅用于 Transformer,还用于基于循环神经网络 RNN 的序列生成模型。在应用场景方面,我们不仅测试了机器翻译的效果,同时也在句子摘要任务上进行了验证。这里只要介绍机器翻译任务上的结果。
我们分别在汉语-英语和英语-德语两个机器翻译任务上进行了测试。汉语-英语采用约 200 万的双语训练数据,英语-德语采用与 Transformer 一样的设置。表 1 和表 2 分别展示了不同模型在汉英和英德机器翻译任务上的结果。
从表 1 可以看出,无论采用循环神经网络还是 Transformer,同步双向推断模型都能够显著提升译文质量。特别是在 Transformer 框架下,BIFT 模型展示了令人惊喜的提升空间。
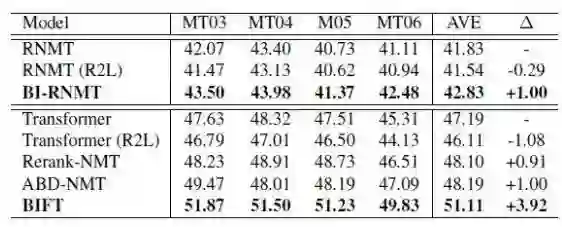
表 1:不同机器翻译模型在汉英任务上的结果。
RNMT 表示基于 LSTM 的序列生成模型;RNMT (R2L)表示采用从右往左解码模式;BI-RNMT 是我们提出的基于同步双向推断的序列生成模型;Rerank-NMT 是一种译文重排序系统,即对 L2R 和 R2L 的候选结果利用全局特征进行重排序,选择最优结果;ABD-NMT 是一种异步双向解码模型,即首先进行 R2L 解码,然后利用 R2L 解码结果优化 L2R 解码过程。
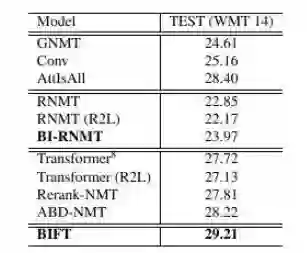
表 2:不同机器翻译模型在英德任务上的结果
表 2 展示的英德机器翻译结果可以对比当前最好的模型。GNMT 是 2016 年 Google 发布的基于深层 LSTM 的序列生成模型;Conv 是 2017 年 Facebook 提出的基于卷积神经网络的序列生成模型;AttIsAll 是 2017 年 Google 提出的 Transformer 模型。表中的 Transformer 是我们重现的模型。可以发现,BIFT 模型在相同的实验设置下,可以显著超越当前最优的模型,取得了最好的结果。
表 3 给出了不同机器翻译模型的参数规模、训练和解码效率的对比结果。可以发现,BIFT 模型没有增加参数规模,而且几乎没有牺牲解码速度。
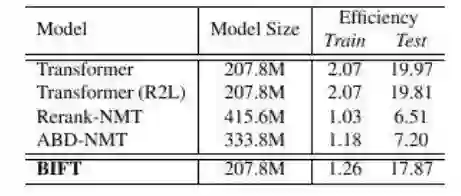
表 3:不同机器翻译模型的参数规模、 训练和解码效率对比。Train 栏表示每秒钟完成的 Batch 训练数目,Test 栏表示每秒钟翻译的句子数目。
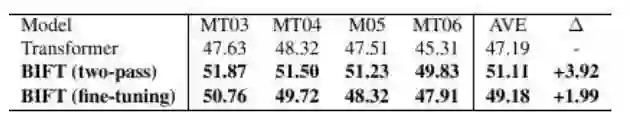
表 4:参数训练策略的实验对比结果
表 4 给出了两种参数训练策略的实验对比结果。可以看到,无论是哪种训练策略,翻译质量都能得到大幅提升。虽然微调法没有两阶段法有效,但是也能获得 2 个 BLEU 值的性能提升。考虑到微调法简单、方便易部署,我们相信这种参数训练策略在现实场景中会更受欢迎。更详细的模型描述和更多更丰富的实验分
析可以参考下面的两篇文章:
Jiajun Zhang, Long Zhou, Yang Zhao and Chengqing Zong. 2019. Synchronous Bidirectional Inference for Neural Sequence Generation. arXiv preprint arXiv: 1902.08955
-
Long Zhou, Jiajun Zhang and Chengqing Zong. 2019. Synchronous Bidirectional Neural Machine Translation. Transactions on ACL, Vol. 7, pp. 91-105, 2019.

点击阅读原文,加入「斯坦福深度自然语言处理学习小组」,与更多同行学习、交流



