谷歌夺回AI画语权,机器的想象力达到全新高度,网友:DALL·E 2诞生一个月就过时了?

来源:量子位
本文为约2784字,建议阅读5分钟
本文
介绍了谷歌
新推出的Imagen与OpenAI的对比。
在让AI搞创作这件事上,谷歌和OpenAI正面刚起来了。
这不,震惊全网的DALL·E 2才新鲜出炉一个月,谷歌就派出名为Imagen的选手来打擂台。

直接上图对比,左边是谷歌Imagen选手眼中的“猫猫绊倒人类雕像”,右边则是DALL·E 2选手的同题创作。

你觉得哪一位选手的作品更符合题意?
而让网友们直呼“DALL·E 2这就过时了?”的,还不只是这种正面PK的刺激。
看到这么一张照片,如果不说是AI生成的,是不是要先感叹一句两脚兽的摆拍技术越来越高超了?

输入“折纸作品:一只狐狸和一只独角兽在飘雪的森林里”,Imagen创作出的画面则是酱婶的:

还可以试试把文字写得长一点。
比如《一只非常快乐的毛茸熊猫打扮成了在厨房里做面团的厨师的高对比度画像,他身后的墙上还有一幅画了鲜花的画》…(啊先让我喘口气)
Imagen也轻松拿下,要素齐全:

看到这,机器学习圈的网友反应是这样的:
不是吧,这才一个月就又更新换代了?

求求别再震惊我了。

这事儿热度一起,很快就破了圈。
吃瓜群众们立刻就想到一块去了。
以后可能没图库网站什么事儿了。

那么这个来自谷歌的新AI,又掌握了什么独家秘技?具体详情,我们一起接着往下看。
增强「理解」比优化「生成」更重要
文本到图像生成我们之前介绍过不少,基本都是一个套路:CLIP负责从文本特征映射到图像特征,然后指导一个GAN或扩散模型生成图像。
但谷歌Imagen这次有个颠覆性的改变——使用纯语言模型只负责编码文本特征,把文本到图像转换的工作丢给了图像生成模型。
语言模型部分使用的是谷歌自家的T5-XXL,训练好后冻结住文本编码器。
图像生成部分则是一系列扩散模型,先生成低分辨率图像,再逐级超采样。
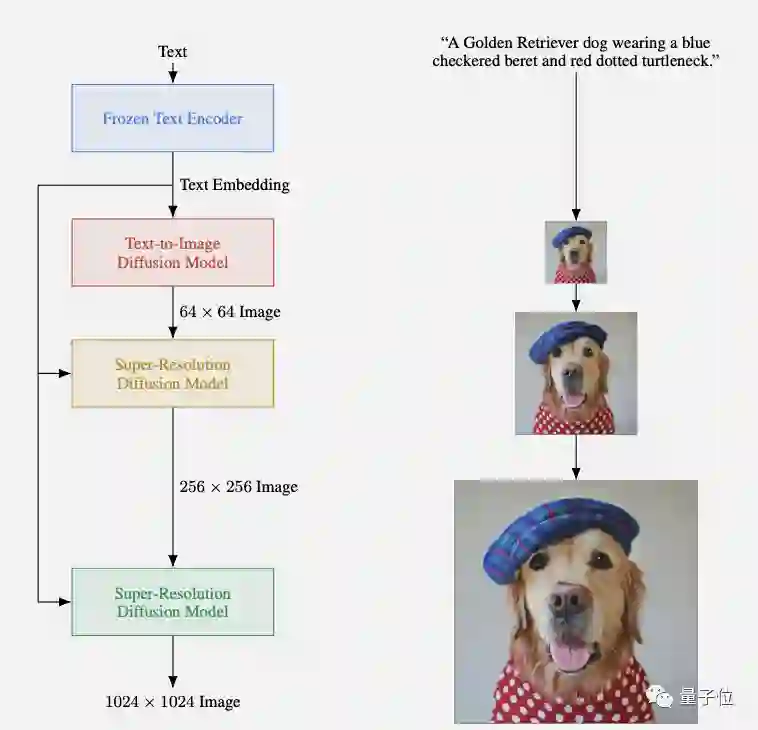
这样做最大的好处,是纯文本训练数据要比高质量图文对数据容易获取的多。
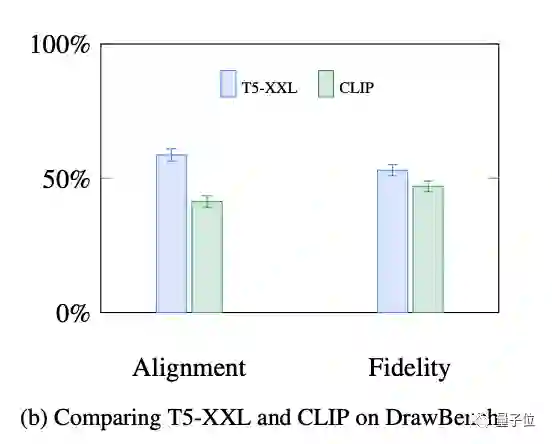
T5-XXL的C4训练集包含800GB的纯文本语料,在文本理解能力上会比用有限图文对训练的CLIP要强。
这一点也有着实验数据做支撑,人类评估上,T5-XXL在保真度和语义对齐方面表现都比CLIP要好。
在实验中谷歌还发现,扩大语言模型的规模对最后效果影响更大,超过扩大图像生成模型的影响。
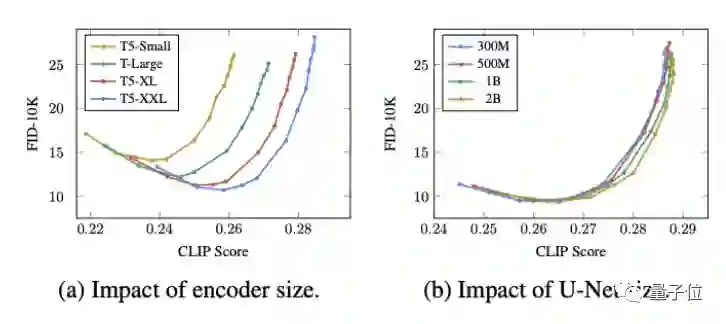
看到这有网友指出,谷歌最后采用的T5-XXL参数规模还不到最新PaLM语言模型5400亿参数的1%,如果用上PaLM,又会是啥样?

除了语言模型部分的发现,谷歌通过Imagen的研究对扩算模型作出不少优化。
首先,增加无分类器引导(classifier-free guidance)的权重可以改善图文对齐,但会损害图像保真度。
解决的办法是每一步采样时使用动态阈值,能够防止过饱和。

第二,使用高引导权重的同时在低分辨率图像上增加噪声,可以改善扩散模型多样性不足的问题。
第三,对扩散模型的经典结构U-Net做了改进,新的Efficient U-Net改善了内存使用效率、收敛速度和推理时间。
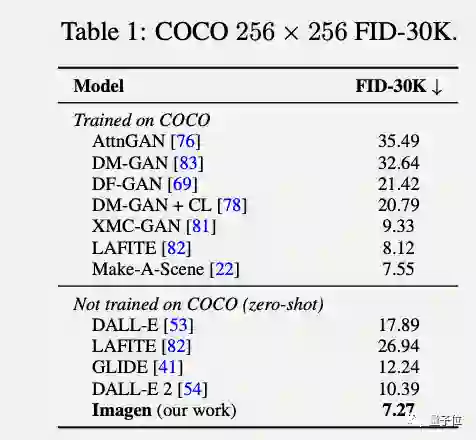
对语言理解和图像生成都做出改进之后,Imagen模型作为一个整体在评估中也取得了很好的成绩。
比如在COCO基准测试上达到新SOTA,却根本没用COCO数据集训练。
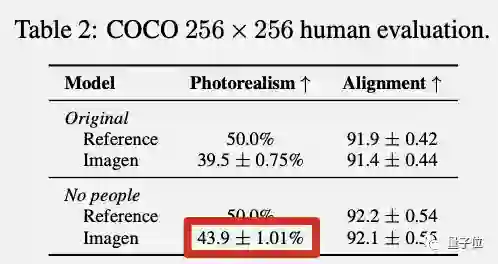
在COCO测试的人类评估部分也发现了Imagen的一个缺点,不擅长生成人类图像。
具体表现是,无人类图像在写实度上获得更高的人类偏好度。
同时,谷歌推出了比COCO更有挑战性的测试基准DrawBench,包含各种刁钻的提示词。
实验发现,DALL·E 2难以准确理解同时出现两个颜色要求的情况,而Imagen就没问题。

反常识情况,比如“马骑着宇航员”两者表现都不佳,只能画出“宇航员骑着马”。
但是Imagen对“一只熊猫在做咖啡拉花”理解更准确,只错了一次。DALL·E 2则全都把熊猫画进了拉花图案里。

大概“马骑着宇航员”有点反常识(狗头)
对于要求图像中出现文字的,也是Imagen做得更好。
除了最基本的把文字写对以外,还可以正确给文字加上烟花效果。

AI画画越来越出圈
说起来,AI作画这件事,最早便源起于谷歌。
2015年,谷歌推出DeepDream,开创了AI根据文本生成图像的先河。

DeepDream作品
但要说相关技术真正开“卷”、出圈,标志性事件还得数2021年OpenAI的DALL·E横空出世。
当时,吴恩达、Keras之父等一众大佬都纷纷转发、点赞,DALL·E甚至被称为2021年第一个令人兴奋的AI技术突破。
随后,语言理解模型和图像生成模型多年来的技术进展,便在“AI作画”这件事上集中爆发,一系列CLIP+GAN、CLIP+扩散模型的研究和应用,频频在网络上掀起热潮。
从此一发不可收拾,技术更新迭代越来越快。
DALL·E 2刚发布的时候就有网友发起一个投票,问多长时间会出现新的SOTA。
当时大多数人选了几个月或1年以上。
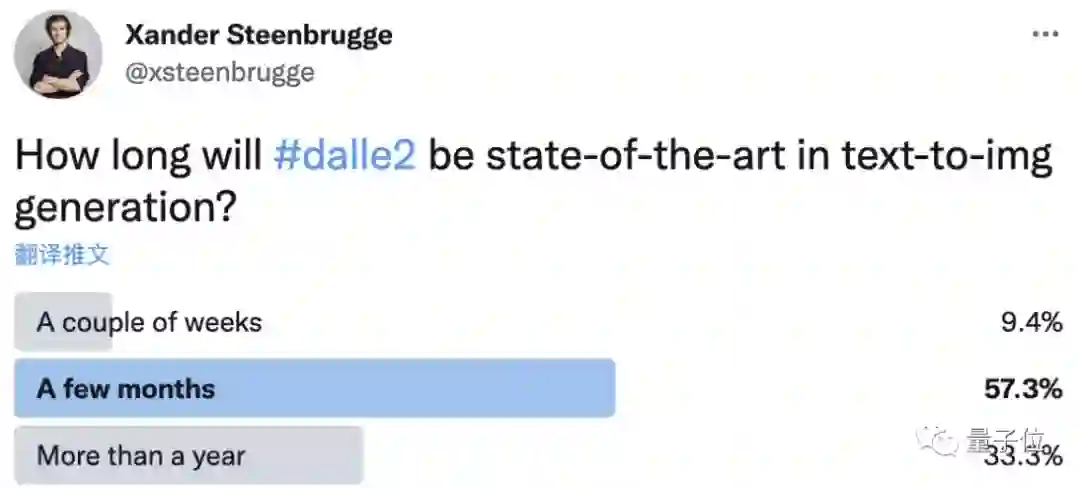
但现在,Imagen的出现只用了6周。
随着AI画画效果越来越强大,受众范围也不断扩大,突破技术圈进入大众视野。
前一阵,就有AI画画应用登上苹果App Store图形与设计排行榜榜首。
现在最新的潮流,是各路设计师排队申请Midjourney、Tiamat等商业化产品的内测,刷爆社交网络。
如此出圈,也给OpenAI和谷歌这样的大公司带来很大压力。
出于AI伦理、公平性等方面考虑,DALL·E 2和Imagen都没有直接开源或开放API。
各自也都在论文里有大篇幅涉及风险、社会影响力的内容。

OpenAI选择了内测模式,而谷歌还在做进一步研究和规范,等到确保AI不被滥用之后再择机公开。
现在想体验Imagen的话,有一个在线Demo演示。
可以从给定的几个提示词中自由组合出不同场景。
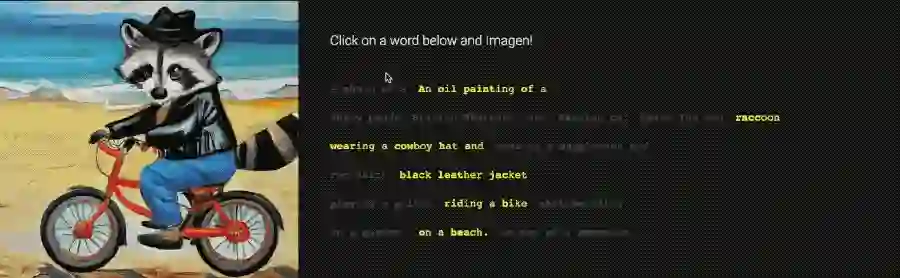
快来试试吧~
Demo地址:
https://gweb-research-imagen.appspot.com
论文地址:
https://gweb-research-imagen.appspot.com/paper.pdf
参考链接:
https://twitter.com/ak92501/status/1528861980702146560



