谷歌赢两次?AI作画大师Parti一出,DALL-E 2.0成「爷爷辈」了
![]()
新智元报道

新智元报道
编辑:David 如願 好困
【新智元导读】时隔仅一月,谷歌又推出新的「AI画图」模型Parti,换个姿势吊打其他选手,两战告捷!




从Imagen到Parti,谷歌又整了啥新活?
从Imagen到Parti,谷歌又整了啥新活?
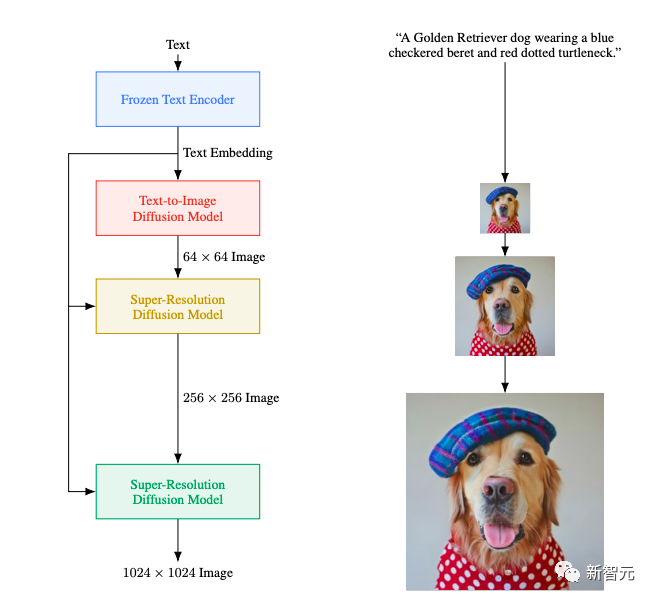
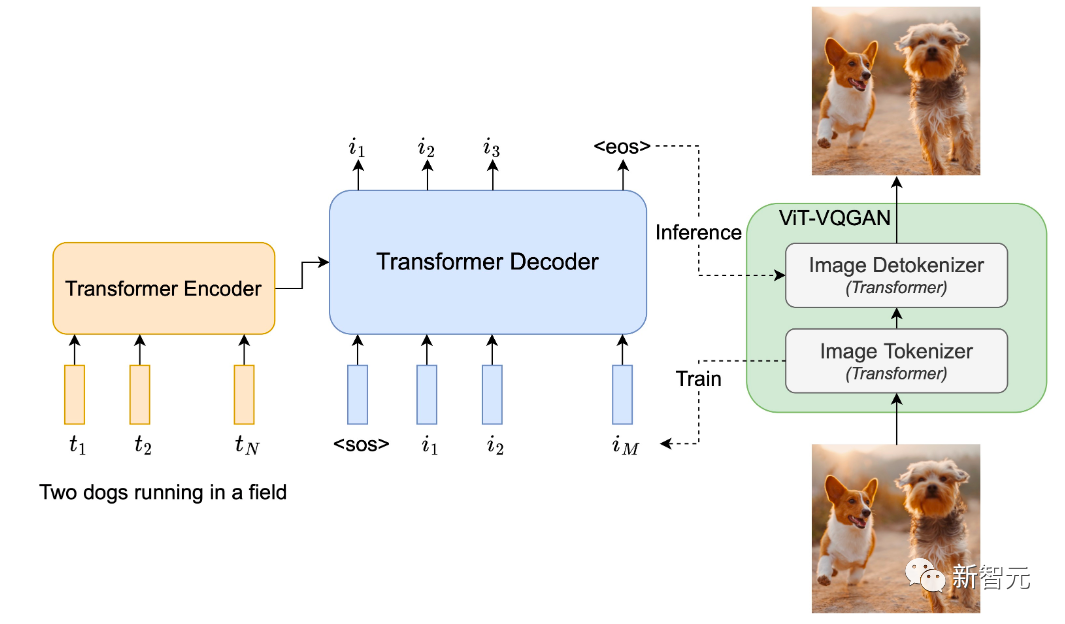
参数从3.5亿到200亿:有啥区别?
参数从3.5亿到200亿:有啥区别?


多面手「艺术家」,风格百搭







参考资料:

登录查看更多
相关内容
Arxiv
0+阅读 · 2022年9月2日
Arxiv
0+阅读 · 2022年9月1日




相关VIP内容
相关资讯