点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
点击进入—> CVer 微信技术交流群
转载自:机器之心 作者:Chitwan Saharia等
OpenAI:DALL・E 2 就是最好的。谷歌:看下我们 Imagen 生成的柴犬?
多模态学习近来受到重视,特别是文本 - 图像合成和图像 - 文本对比学习两个方向。一些模型因在创意图像生成、编辑方面的应用引起了公众的广泛关注,例如 OpenAI 的文本转图像模型 DALL・E、英伟达的 GauGAN。现在,来自谷歌的研究者也在这一方向做出了探索,提出了一种文本到图像的扩散模型 Imagen。
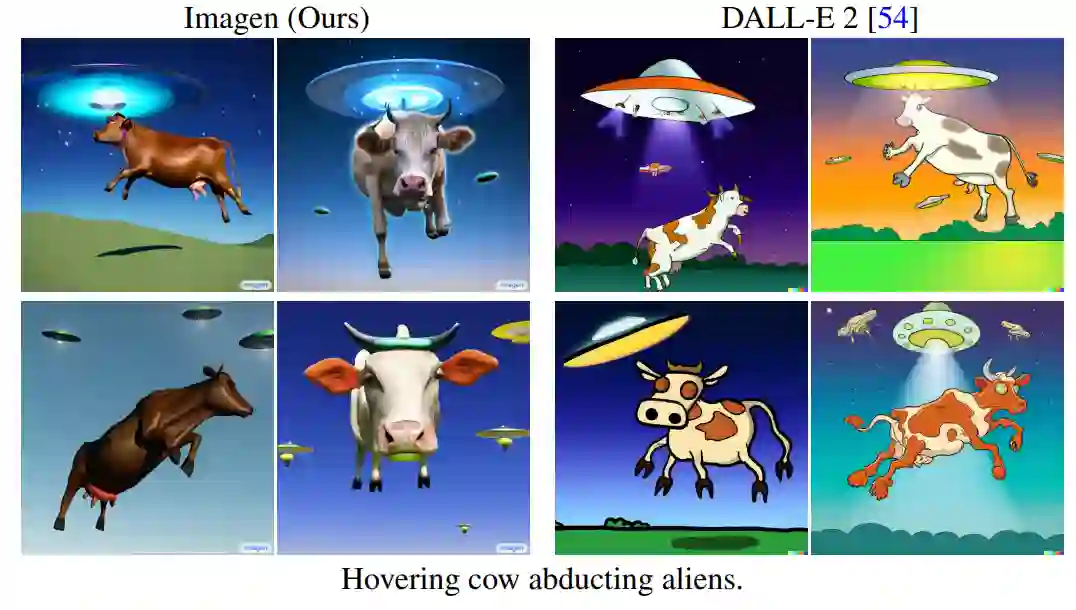
Imagen 结合了 Transformer 语言模型和高保真扩散模型的强大功能,在文本到图像的合成中提供前所未有的逼真度和语言理解能力。与仅使用图像 - 文本数据进行模型训练的先前工作相比,Imagen 的关键突破在于:谷歌的研究者发现在纯文本语料库上预训练的大型 LM 的文本嵌入对文本到图像的合成显著有效。Imagen 的文本到图像生成可谓天马行空,能生成多种奇幻却逼真的有趣图像。
![]()
![]()
![]()
![]()
如果你觉得这些图片过于魔幻,那下面这张小鸟生气的图就非常真实了,隔着屏幕都能感觉到它的愤怒:
![]()
我们发现这些图片的分辨率都很高,像是人工精心 PS 过的。然而这些模型都出自 Imagen 这个 AI 模型之手。
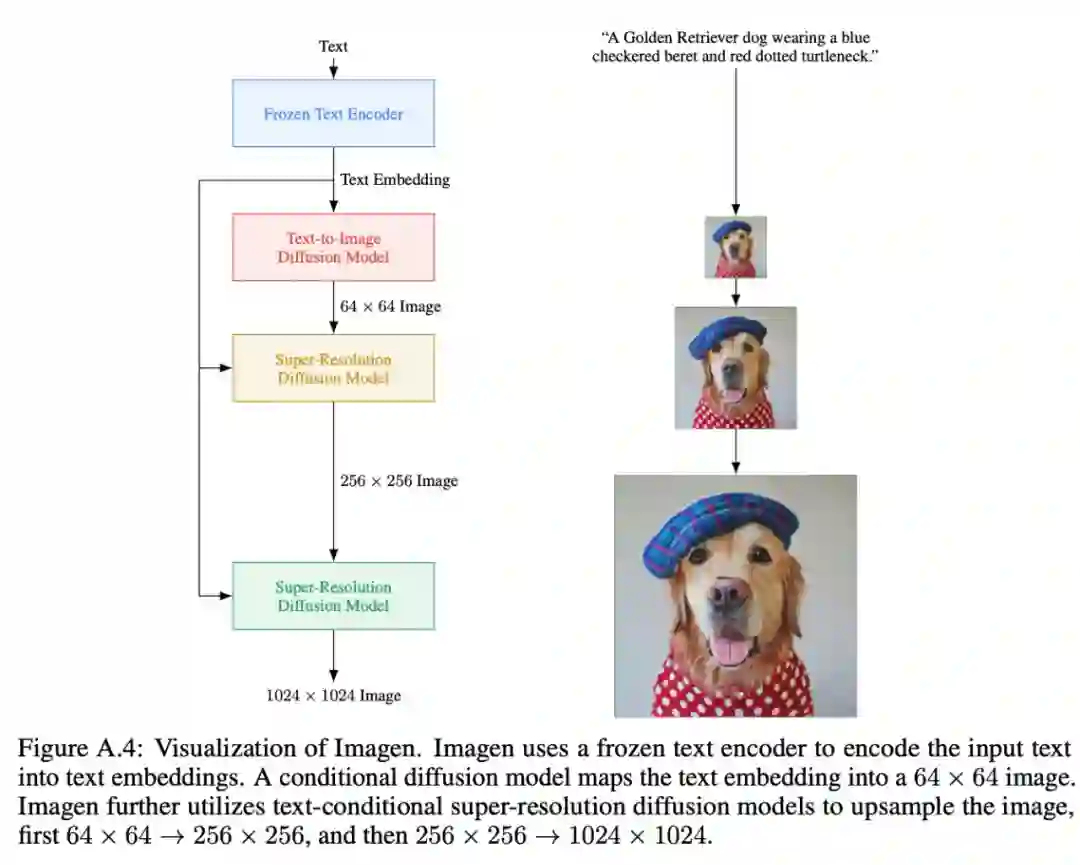
Imagen 模型中包含一个 frozen T5-XXL 编码器,用于将输入文本映射到一系列嵌入和一个 64×64 的图像扩散模型中,并带有两个超分辨率扩散模型,用于生成 256×256 和 1024×1024 的图像。
![]()
其中,所有扩散模型都以文本嵌入序列为条件,并使用无分类器指导。借助新型采样技术,Imagen 允许使用较大的指导权重,而不会发生样本质量下降,使得生成的图像具有更高的保真度、图像与文本更加吻合。
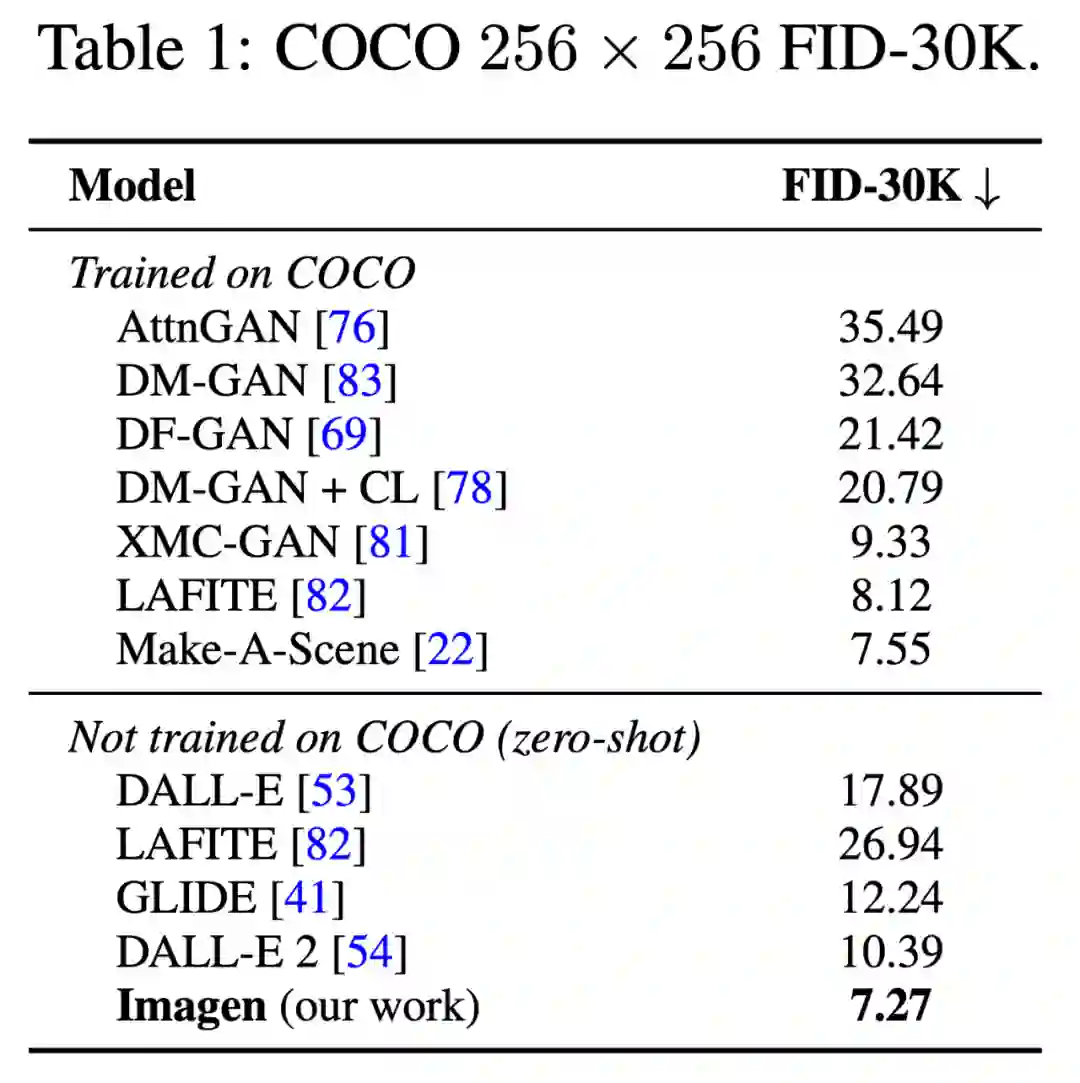
虽然架构简单且易于训练,但 Imagen 产生了令人惊讶的强大结果。Imagen 在 COCO 上的零样本 FID-30K 分数为 7.27,性能显著优于之前的方法(GLIDE、DALL-E 2 等),并超越了当前的 SOTA 模型 Make-A-Scene(7.27 VS 7.55)。从人工评估看,Imagen 生成的样本在图像文本对齐方面与 COCO captions 的参考图像相当。
![]()
![]()
![]()
![]()
此外,研究者还提出了一种用于文本到图像评估的文本 prompt 结构化新套件 DrawBench。DrawBench 对文本到图像模型进行多维评估,文本 prompt 旨在探索模型的不同语义属性。这些 prompt 包括组合性、基数、空间关系、处理复杂文本 prompt 或带有稀有单词的 prompt 的能力,它们包括创造性 prompt,这些 prompt 将模型生成高度难以置信的场景的能力扩展到训练数据范围之外。
借助 DrawBench,研究者进行了广泛的人工评估,结果表明,Imagen 的性能明显优于其他方法。研究者进一步展示了相对于多模态嵌入(例如 CLIP), 使用大型预训练语言模型作为 Imagen 的文本编码器具有明显的优势。
![]()
论文地址:https://gweb-research-imagen.appspot.com/paper.pdf
不过,和前段时间大火的 DALL・E 2 一样,我们很难指望谷歌将这个模型开源。对此,有网友建议说,可以去 GitHub 上找一些「野生」复现来玩一玩,比如已经放出一段时间的「DALL-E 2-Pytorch」项目:
![]()
项目地址:https://github.com/lucidrains/DALLE2-pytorch
Imagen 由一个文本编码器和一系列条件扩散模型组成,前者将文本映射为一系列嵌入,后者将这些嵌入映射为分辨率不断提高的图像,如图 Fig. A.4 所示。
在构建 Imagen 的过程中,研究者探索了几个预训练文本编码器:BERT、T5 和 CLIP。为了简单起见,他们冻结了这些文本编码器的权重。冻结有几个优点,例如嵌入的离线计算,这使得文本 - 图像模型训练期间的计算或内存占用可以忽略。
在这项工作中,研究者发现,扩展文本编码器的大小可以提高文本到图像生成的质量。他们还发现,虽然 T5-XXL 和 CLIP 文本编码器在 MS-COCO 等简单基准上性能相似,但在 DrawBench 上的图像 - 文本对齐和图像保真度方面,人类评估员更喜欢 T5-XXL 编码器而不是 CLIP 文本编码器。
扩散模型是一类生成模型,通过迭代去噪过程,将高斯噪声从已知的数据分布转换为样本。这类模型可以是有条件的,例如类标签、文本或低分辨率图像。
分类器指导是一种在采样期间使用来自预训练模型 p (c|z_t) 的梯度来提高样本质量,同时减少条件扩散模型多样性的技术。无分类器指导是一种替代技术,通过在训练期间随机丢弃 c(例如 10% 的概率),在有条件和无条件目标上联合训练单个扩散模型,从而避开上述预训练模型。
研究者证实了最近的文本指导扩散工作的结果,并发现增加无分类器指导权重可以改善图像 - 文本对齐,但也会损害图像保真度,产生高度饱和、不自然的图像。他们发现这是由于高指导权重引起的训练 - 测试不匹配所造成的。并且由于扩散模型在整个采样过程中迭代地应用于其自身的输出,采样过程就产生了不自然的图像。
为了解决这个问题,他们研究了静态阈值(static thresholding)和动态阈值(dynamic thresholding)。他们发现,动态阈值对于提升图像真实感和图像 - 文本对齐能力要有效得多,特别是在使用非常大的指导权重的时候。
Imagen 利用一个 64 × 64 基本模型、两个文本条件超分辨率扩散模型将生成的 64 × 64 图像上采样为 256 × 256 图像,然后再上采样为 1024 × 1024 图像。具有噪声调节增强的扩散模型组在逐步生成高保真图像方面非常有效。
此外,研究者通过噪声水平调节使超分辨率模型意识到添加的噪声量,显著提高了样本质量,而且有助于提高超分辨率模型处理较低分辨率模型产生的 artifacts 的稳健性。Imagen 对两个超分辨率模型都使用了噪声调节增强。研究者发现这是生成高保真图像的关键。
给定调节低分辨率图像和增强水平(aug_level,例如高斯噪声或模糊的强度),研究者用增强(对应于 aug_level)破坏低分辨率图像,并在 aug_level 上调节扩散模型。在训练期间,aug_level 是随机选择的,而在推理期间,可以扫描它的不同值以找到最佳样本质量。在这项研究中,研究者使用高斯噪声作为一种增强形式,并应用类似于扩散模型中使用的正向过程的方差来保持高斯噪声增强。
研究者采用 U-Net 架构作为基本的 64 × 64 文本到图像扩散模型。该网络通过池化嵌入向量以文本嵌入为条件,加入到扩散时间步嵌入中,类似于 [16, 29] 中使用的类嵌入条件方法。通过在多分辨率的文本嵌入上添加交叉注意力,研究者进一步对整个文本嵌入序列进行了限制。此外,他们在注意力层和池化层发现了用于文本嵌入、可以大大提高性能的层归一化。
对于 64 × 64→256 × 256 的超分辨率模型,研究者采用了改编自 [40,58] 的 U-Net 模型。为了提高内存效率、推理时间和收敛速度,研究者对 U-Net 模型进行了一些修改(该变体比 [40,58] 中使用的 U-Net 模型的每秒速度快 2-3 倍),并称这种变体为 Efficient U-Net。256 × 256→1024 × 1024 的超分辨率模型是在 1024 × 1024 图像的 64×64 → 256×256 crop 上训练的。他们去掉了自注意力层,但保留了文本交叉注意力层,这一点是很关键的。
在推理过程中,模型接收完整 256 × 256 低分辨率图像作为输入,输出上采样的 1024 × 1024 图像。注意,研究者在两个超分辨率模型上都使用了文本交叉注意力。
尽管 COCO 是一个很有价值的基准,但很明显它的 prompt 范围是有限的,不能很好地提供对模型之间差异的洞察。因此,研究者提出了 DrawBench,这是一个综合的、具有挑战性的 prompt 集,支持文本到图像模型的评估和比较。
DrawBench 包含 11 种类型的 prompt,用于测试模型的不同功能,比如颜色渲染、对象数量、空间关系、场景中的文本以及对象之间的非常规交互。类别中还包括复杂的 prompt,包括冗长复杂的文本描述、不常见词汇以及拼写错误的 prompt。此外也包含从 DALL-E、Gary Marcus et al. [38]、Reddit 收集的几个 prompt 集。
在 11 个类别中,DrawBench 共包含 200 个 prompt,且在「足够大而全面」与「足够小而人工评估可行」之间取得了很好的平衡。图 2 展示了来自带有 Imagen 样本的 DrawBench 的示例 prompt。
![]()
第 4.1 节描述了训练细节,第 4.2 节和第 4.3 节分析了 MS-COCO 和 DrawBench 上的实验结果,第 4.4 节总结了消融研究和主要发现。对于下面的所有实验,图像是来自 Imagen 的公平随机样本,没有后期处理或重新排序。
研究者使用了 FID 评分对 COCO 验证集上的 Imagen 进行了评估,结果如表 1 所示。
![]()
Imagen 以 7.27 的得分在 COCO 上实现了 zero-shot FID 的 SOTA 结果,超越了 DALL-E 2 及其他同期工作,甚至超过了其他在 COCO 上训练的模型。
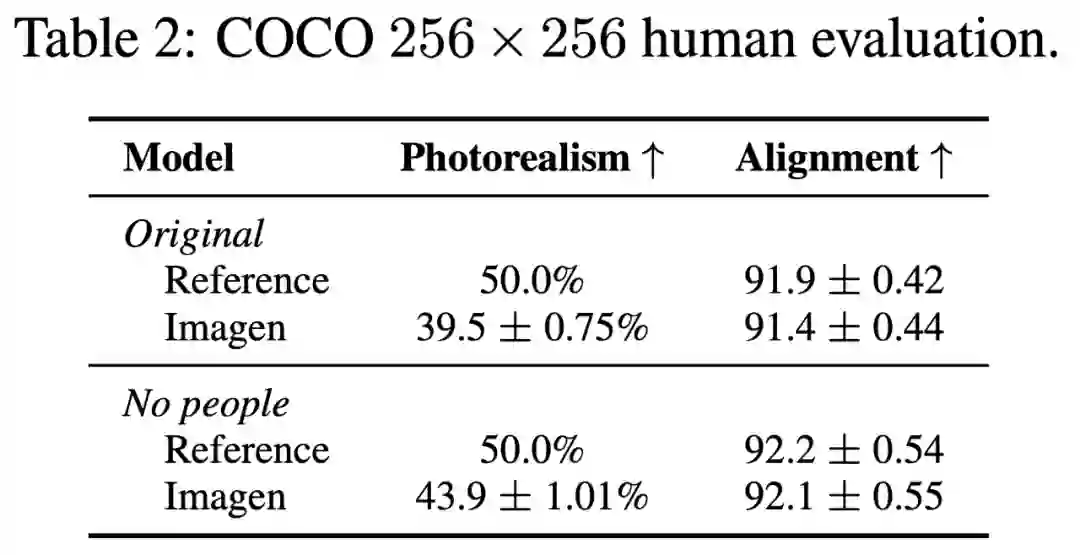
表 2 展示了在 COCO 验证集上测试图像质量和对齐的人工评估结果,包括原始 COCO 验证集和过滤后的版本。在这个版本中,所有与人相关的参考数据都被删除了。在没有人的设置下,Imagen 的偏好率提高到了 43.6% ,这表明 Imagen 生成逼真人物的能力有限。在标题相似度方面,Imagen 的得分与原始的参考图片相当,这表明 Imagen 有能力生成与 COCO 标题相一致的图片。
![]()
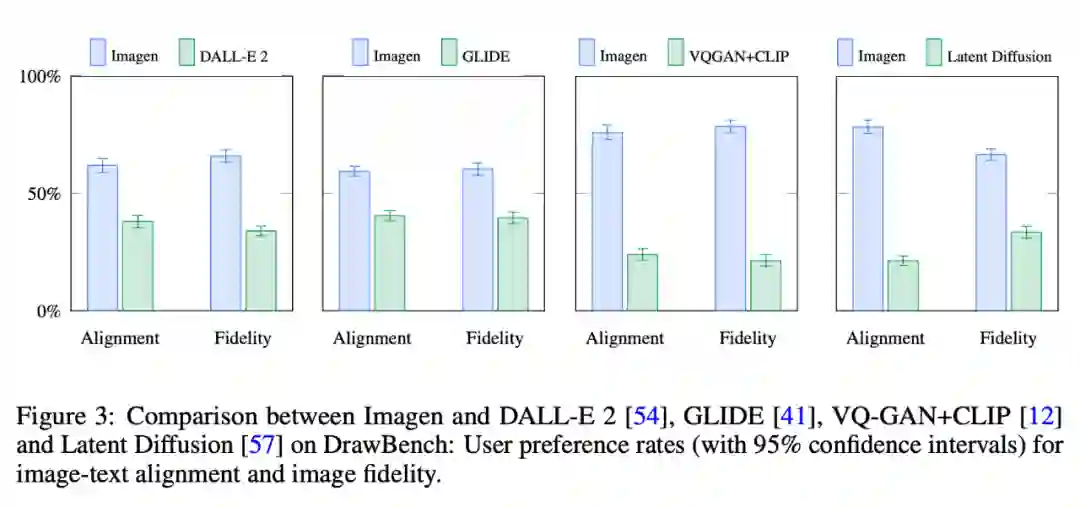
使用 DrawBench,研究者将 Imagen 与 DALL-E 2 (公共版本)、 GLIDE、Latent Diffusion 和 CLIP-guided VQGAN 进行了比较。
图 3 展示了三个模型中每一个模型对 Imagen 成对比较的人类评估结果,包括偏好模型 A、模型 B,或者不受图像保真度和图像文本对齐影响。可以看出,在图文对齐和图像保真度方面,人类评估者极其偏爱 Imagen 模型。读者可以参考附录 E,了解更详细的类别对比和定性对比。
![]()
ICCV和CVPR 2021论文和代码下载
后台回复:CVPR2021,即可下载CVPR 2021论文和代码开源的论文合集
后台回复:ICCV2021,即可下载ICCV 2021论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
目标检测和Transformer交流群成立
扫描下方二维码,或者添加微信:CVer6666,即可添加CVer小助手微信,便可申请加入CVer-目标检测或者Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer等。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测或者Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
![]()
▲扫码或加微信: CVer6666,进交流群
CVer学术交流群(知识星球)来了!想要了解最新最快最好的CV/DL/ML论文速递、优质开源项目、学习教程和实战训练等资料,欢迎扫描下方二维码,加入CVer学术交流群,已汇集数千人!
![]()
▲扫码进群
整理不易,请点赞和在看![]()