这个“1句话生成视频”AI爆火:支持中文输入,分辨率达到480×480,清华&智源出品
萧箫 发自 凹非寺
量子位 | 公众号 QbitAI
一周不到,AI画师又“进阶”了,还是一个大跨步——
直接1句话生成视频的那种。
输入“一个下午在海滩上奔跑的女人”,立刻就蹦出一个4秒32帧的小片段:

又或是输入“一颗燃烧的心”,就能看见一只被火焰包裹的心:

这个最新的文本-视频生成AI,是清华&智源研究院出品的模型CogVideo。
Demo刚放到网上就火了起来,有网友已经急着要论文了:
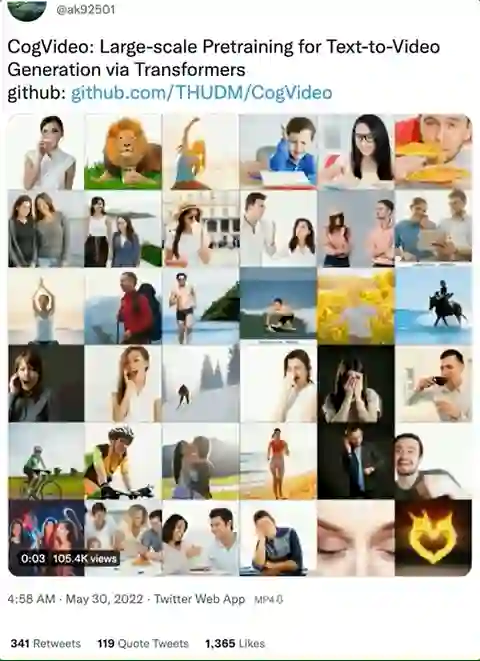
CogVideo“一脉相承”于文本-图像生成模型CogView2,这个系列的AI模型只支持中文输入,外国朋友们想玩还得借助谷歌翻译:

看完视频的网友直呼“这进展也太快了,要知道文本-图像生成模型DALL-E2和Imagen才刚出”

还有网友想象:照这个速度发展下去,马上就能看到AI一句话生成VR头显里的3D视频效果了:
所以,这只名叫CogVideo的AI模型究竟是什么来头?
生成低帧视频后再插帧
团队表示,CogVideo应该是当前最大的、也是首个开源的文本生成视频模型。
在设计模型上,模型一共有90亿参数,基于预训练文本-图像模型CogView2打造,一共分为两个模块。
第一部分先基于CogView2,通过文本生成几帧图像,这时候合成视频的帧率还很低;
第二部分则会基于双向注意力模型对生成的几帧图像进行插帧,来生成帧率更高的完整视频。
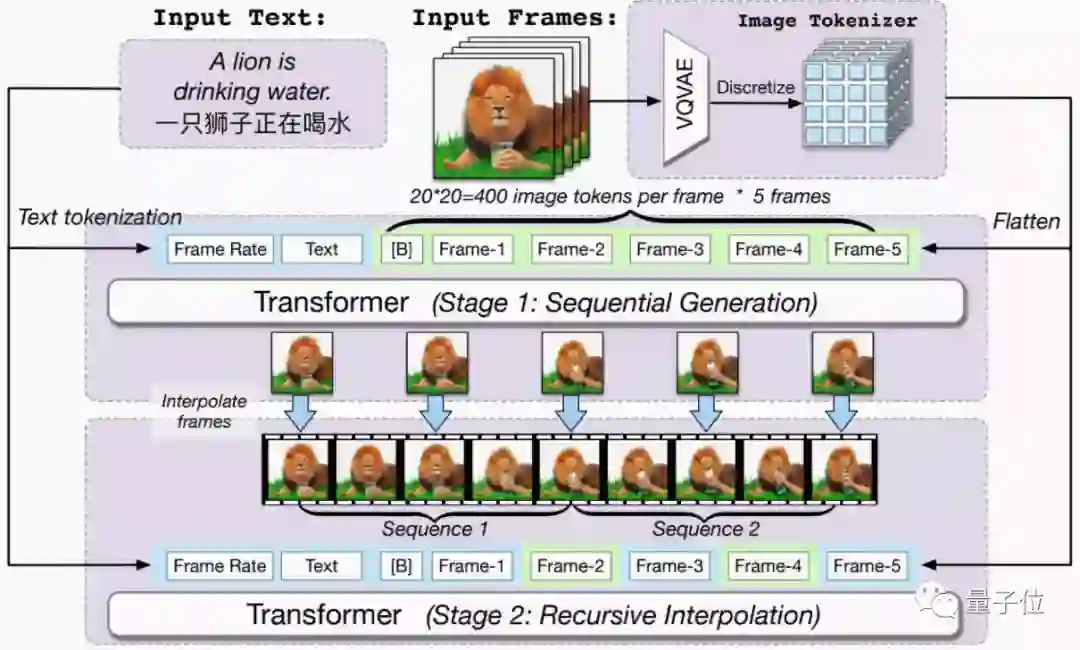
在训练上,CogVideo一共用了540万个文本-视频对。
这里不仅仅是直接将文本和视频匹配起来“塞”给AI,而是需要先将视频拆分成几个帧,并额外给每帧图像添加一个帧标记。
这样就避免了AI看见一句话,直接给你生成几张一模一样的视频帧。
其中,每个训练的视频原本是160×160分辨率,被CogView2上采样(放大图像)至480×480分辨率,因此最后生成的也是480×480分辨率的视频。
至于AI插帧的部分,设计的双向通道注意力模块则是为了让AI理解前后帧的语义。
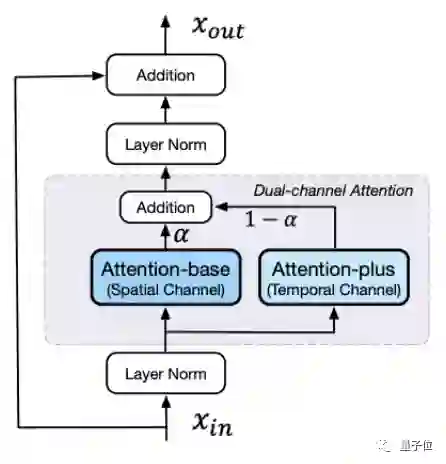
最后,生成的视频就是比较丝滑的效果了,输出的4秒视频帧数在32张左右。
在人类评估中得分最高
这篇论文同时用数据测试和人类打分两种方法,对模型进行了评估。
研究人员首先将CogVideo在UCF-101和Kinetics-600两个人类动作视频数据集上进行了测试。
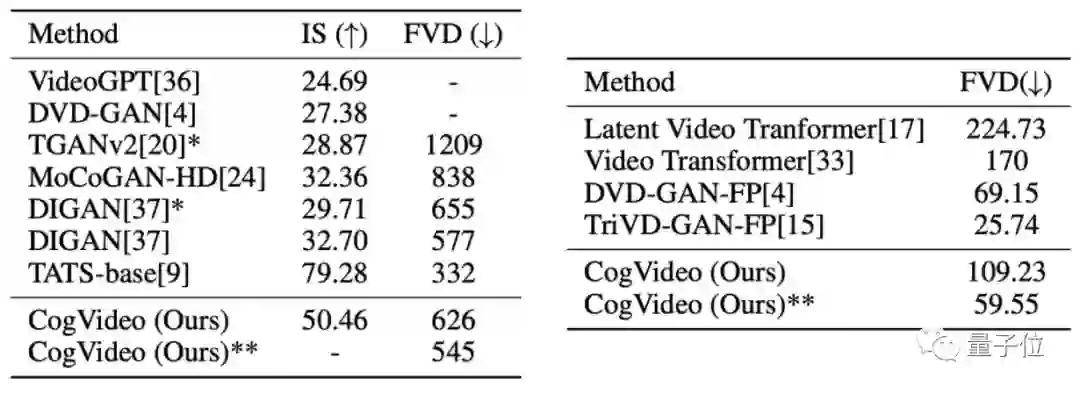
其中,FVD(Fréchet视频距离)用于评估视频整体生成的质量,数值越低越好;IS(Inception score)主要从清晰度和生成多样性两方面来评估生成图像质量,数值越高越好。
整体来看,CogVideo生成的视频质量处于中等水平。
但从人类偏好度来看,CogVideo生成的视频效果就比其他模型要高出不少,甚至在当前最好的几个生成模型之中,取得了最高的分数:
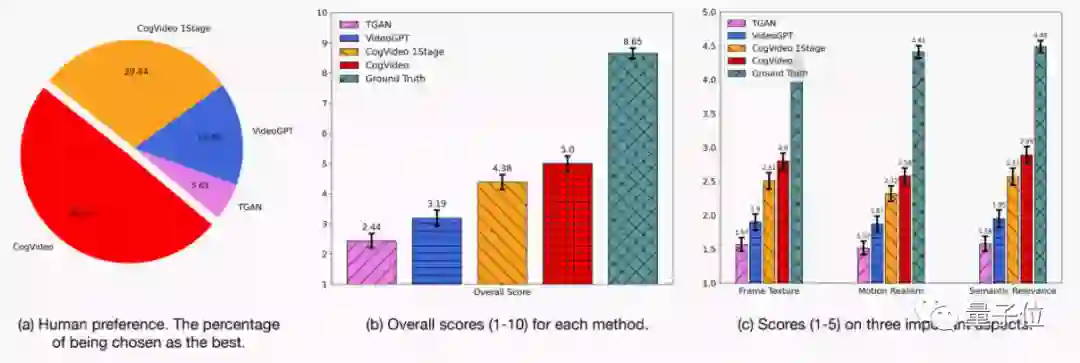
具体来说,研究人员会给志愿者一份打分表,让他们根据视频生成的效果,对几个模型生成的视频进行随机评估,最后判断综合得分:

CogVideo的共同一作洪文逸和丁铭,以及二作郑问迪,三作Xinghan Liu都来自清华大学计算机系。
此前,洪文逸、丁铭和郑问迪也是CogView的作者。
论文的指导老师唐杰,清华大学计算机系教授,智源研究院学术副院长,主要研究方向是AI、数据挖掘、机器学习和知识图谱等。
对于CogVideo,有网友表示仍然有些地方值得探究,例如DALL-E2和Imagen都有一些不同寻常的提示词来证明它们是从0生成的,但CogVideo的效果更像是从数据集中“拼凑”起来的:
例如,狮子直接“用手”喝水的视频,就不太符合我们的常规认知(虽然很搞笑):

(是不是有点像给鸟加上两只手的魔性表情包)

但也有网友指出,这篇论文给语言模型提供了一些新思路:
用视频训练可能会进一步释放语言模型的潜力。因为它不仅有大量的数据,还隐含了一些用文本比较难体现的常识和逻辑。

目前CogVideo的代码还在施工中,感兴趣的小伙伴可以去蹲一波了~
项目&论文地址:
https://github.com/THUDM/CogVideo
参考链接:
[1]https://twitter.com/ak92501/status/1531017163284393987
[2]https://news.ycombinator.com/item?id=31561845
[3]https://www.youtube.com/watch?v=P7JRvwfHFwo
[4]https://agc.platform.baai.ac.cn/CogView/index.html
[5]https://www.reddit.com/r/MediaSynthesis/comments/v0kqu8/cogvideo_largescale_pretraining_for_texttovideo/
— 完 —
「人工智能」、「智能汽车」微信社群邀你加入!
欢迎关注人工智能、智能汽车的小伙伴们加入我们,与AI从业者交流、切磋,不错过最新行业发展&技术进展。
ps.加好友请务必备注您的姓名-公司-职位哦~

点这里👇关注我,记得标星哦~
一键三连「分享」、「点赞」和「在看」
科技前沿进展日日相见~


