中国科学院大学和图森未来提出:TridentNet 处理目标检测中尺度变化新思路
点击上方“CVer”,选择"星标"和“置顶”
重磅干货,第一时间送达

前戏
最近出了很多论文,各种SOTA,CVer也立即跟进报道(点击可访问):
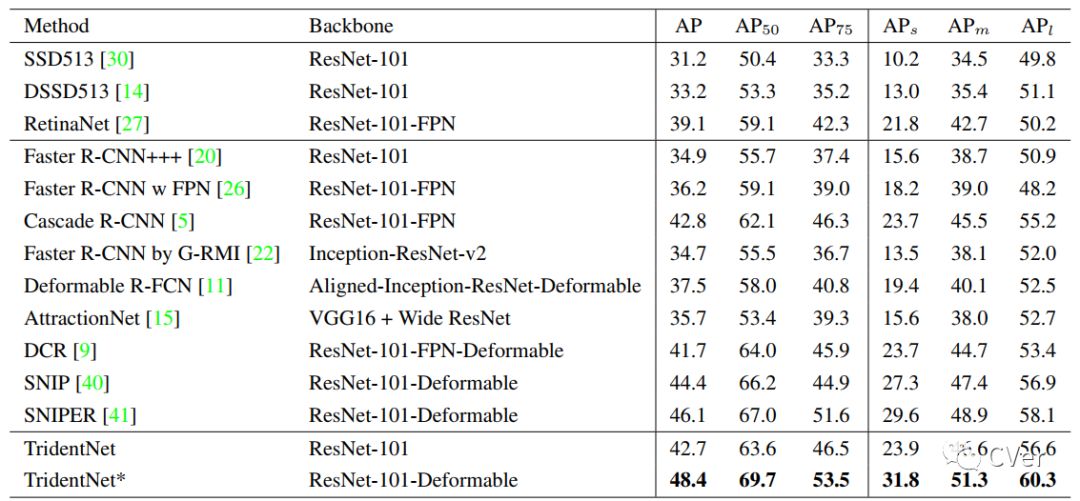
今天po的TridentNet,可以说是现在(2019-01-27)目标检测最强算法(不管是one-stage还是two-stage),这里的强是指mAP高。说再多,不如实验结果来的客观:在COCO test-dev数据集上,mAP为48.4
本文其实压了较久,因为半个月前,TridentNet就已经在arXiv刊登出来了,Amusi一直在等项目开源,但感觉月底不会开源了,所以先介绍给大家,并附上论文原作者的解读。
简介
Scale-Aware Trident Networks for Object Detection

arXiv: https://arxiv.org/abs/1901.01892
github: 即将开源
作者团队:中国科学院大学&图森未来
注:2019年01月07日刚出炉的paper
下面附上论文原作者:图森未来首席科学家王乃岩对TridentNet的解读
链接(已获权转载):
https://zhuanlan.zhihu.com/p/54334986
论文解读
今天破天荒地为大家介绍一篇我们自己的工作(Scale-Aware Trident Networks for Object Detection),因为我是真的对这个工作很满意,哈哈。这篇文章主要要解决的问题便是目标检测中最为棘手的scale variation问题。我们使用了非常简单干净的办法在标准的COCO benchmark上,使用ResNet101单模型可以得到MAP 48.4的结果,远远超越了目前公开的单模型最优结果。
在正式介绍我们的方法之前,我先简单回顾一下现有的两大类方法。第一大类,也是从非Deep时代,乃至CV初期就被就被广泛使用的方法叫做image pyramid。在image pyramid中,我们直接对图像进行不同尺度的缩放,然后将这些图像直接输入到detector中去进行检测。虽然这样的方法十分简单,但其效果仍然是最佳,也后续启发了SNIP这一系列的工作。单论性能而言,multi-scale training/testing仍然是一个不可缺少的组件。然而其缺点也是很明显的,测试时间大幅度提高,对于实际使用并不友好。另外一大类方法,也是Deep方法所独有的,也就是feature pyramid。最具代表性的工作便是经典的FPN了。这一类方法的思想是直接在feature层面上来近似image pyramid。非Deep时代在检测中便有经典的channel feature这样的方法,这个想法在CNN中其实更加直接,因为本身CNN的feature便是分层次的。从开始的MS-CNN直接在不同downsample层上检测大小不同的物体,再到后续TDM和FPN加入了新的top down分支补充底层的语义信息不足,都是延续类似的想法。然而实际上,这样的近似虽然有效,但是仍然性能和image pyramid有较大差距。

几种处理scale variation方法的比较
我们方法的motivation其实早在16年刷KITTI榜单的时候就有初步形成,但是一直因为各种原因搁置,直到今年暑假有两位很优秀的同学一起将这个初步的想法改进,做扎实,结果其实也很出乎我最开始的意料。我们考虑对于一个detector本身而言,backbone有哪些因素会影响性能。总结下来,无外乎三点:network depth(structure),downsample rate和receptive field。对于前两者而言,其影响一般来说是比较明确的,即网络越深(或叫表示能力更强)结果会越好,下采样次数过多对于小物体有负面影响。但是没有工作,单独分离出receptive field,保持其他变量不变,来验证它对detector性能的影响。所以,我们做了一个验证性实验,分别使用ResNet50和ResNet101作为backbone,改变最后一个stage中每个3*3 conv的dilation rate。通过这样的方法,我们便可以固定同样的网络结构,同样的参数量以及同样的downsample rate,只改变网络的receptive field。我们很惊奇地发现,不同尺度物体的检测性能和dilation rate正相关!也就是说,更大的receptive field对于大物体性能会更好,更小的receptive field对于小物体更加友好。于是下面的问题就变成了,我们有没有办法把不同receptive field的优点结合在一起呢?
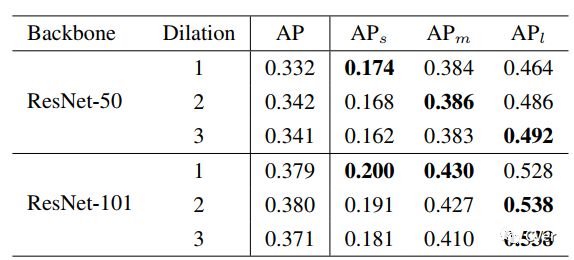
所以我们最开始的一个想法便是直接加入几支并行,但是dilation rate不同的分支,在文中我们把每一个这样的结构叫做trident block。这样一个简单的想法已经可以带来相当可观的性能提升。我们进一步考虑我们希望这三支的区别应该仅仅在于receptive field,它们要检测的物体类别,要对特征做的变换应该都是一致的。所有自然而然地想到我们对于并行的这几支可以share weight。 一方面是减少了参数量以及潜在的overfitting风险,另一方面充分利用了每个样本,同样一套参数在不同dilation rate下训练了不同scale的样本。最后一个设计则是借鉴SNIP,为了避免receptive field和scale不匹配的情况,我们对于每一个branch只训练一定范围内样本,避免极端scale的物体对于性能的影响。
总结一下,我们的TridentNet在原始的backbone上做了三点变化:第一点是构造了不同receptive field的parallel multi-branch,第二点是对于trident block中每一个branch的weight是share的。第三点是对于每个branch,训练和测试都只负责一定尺度范围内的样本,也就是所谓的scale-aware。这三点在任何一个深度学习框架中都是非常容易实现的。
在测试阶段,我们可以只保留一个branch来近似完整TridentNet的结果,后面我们做了充分的对比实验来寻找了这样single branch approximation的最佳setting,一般而言,这样的近似只会降低0.5到1点map,但是和baseline比起来不会引入任何额外的计算和参数。
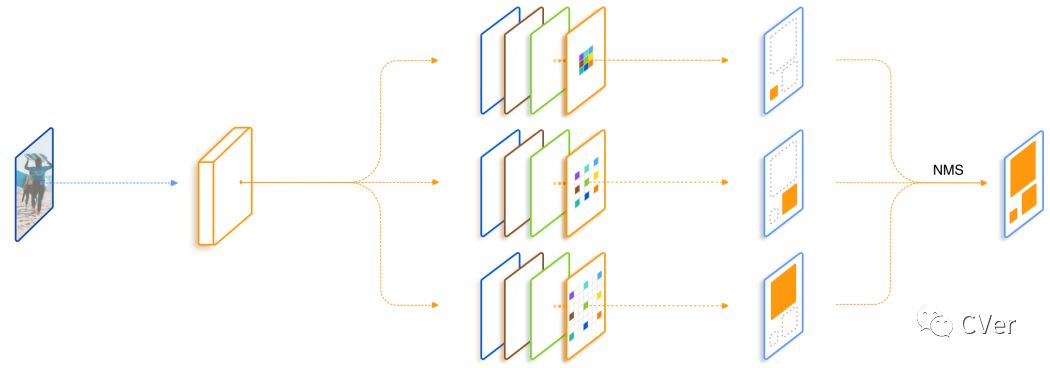
TridentNet网络结构
我们在论文中做了非常详尽的ablation analyses,包括有几个branch性能最好;trident block应该加在网络的哪个stage;trident block加多少个性能会饱和。这些就不展开在这里介绍了,有兴趣的读者可以参照原文。这里主要介绍两个比较重要的ablation。
第一个当然是我们提出的这三点,分别对性能有怎样的影响。我们分别使用了两个很强的结构ResNet101和ResNet101-Deformable作为我们的backbone。这里特地使用了Deformable的原因是,我们想要证明我们的方法和Deformable Conv这种 去学习adaptive receptive field的方法仍然相兼容。具体结果见下:
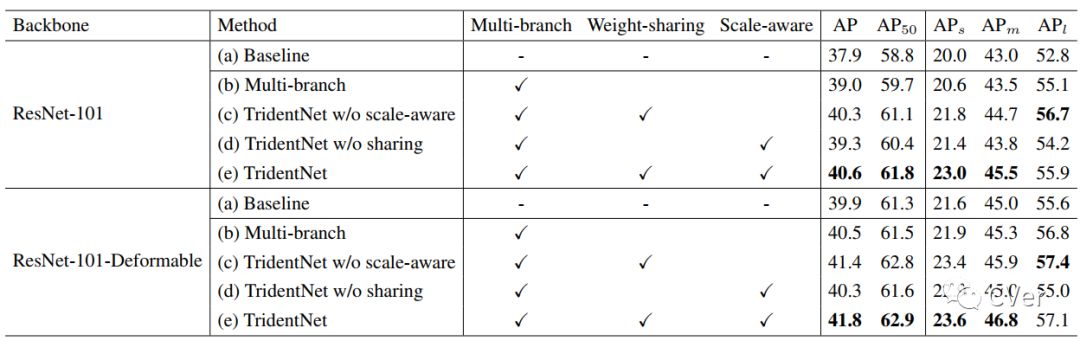
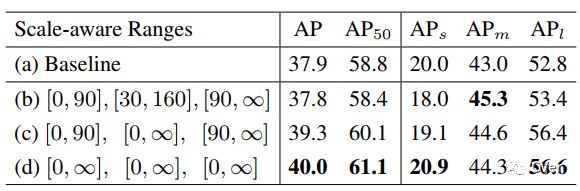
可以看到,在接近map 40的baseline上,我们提出的每一部分都是有效的,在这两个baseline上分别有2.7和1.9 map的提升。
另外一个值得一提的ablation是,对于我们上面提出的single branch approximation,我们如何选择合适的scale-aware training参数使得近似的效果最好。其实我们发现很有趣的一点是,如果采用single branch近似的话,那么所有样本在所有branch都训练结果最好。这一点其实也符合预期,因为最后只保留一支的话那么参数最好在所有样本上所有scale上充分训练。如果和上文40.6的baseline比较,可以发现我们single branch的结果比full TridentNet只有0.6 map的下降。这也意味着我们在不增加任何计算量和参数的情况,仍然获得2.1 map的提升。这对于实际产品中使用的detector而言无疑是个福音。
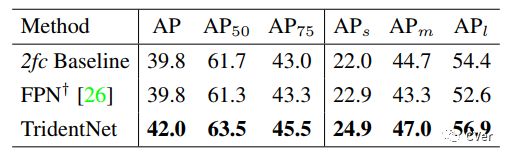
我们还和经典的feature pyramid方法FPN做了比较。为了保证比较公平,我们严格遵循Detectron中的实现方式,并使用两层fc作为detector的head。可以看到在这样的setting下,FPN其实对于baseline而言小物体有一定提升,然而大物体性能下降,综合下来并没有比baseline有提高,但是我们的方法仍然可以持续地提升2.2个点map,就算使用single branch approximation,仍然也有1.2个点的提升。这充分证明了我们的方法的普适性。
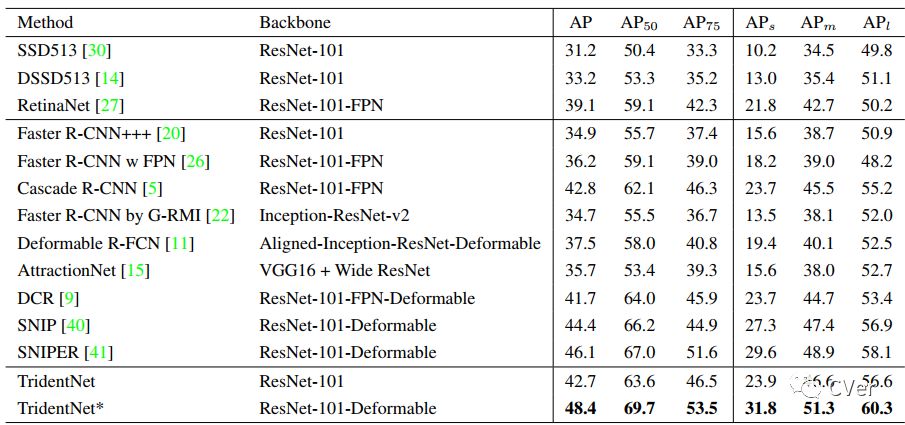
最后我们将我们的方法和各paper中报告的最好结果相比较。但是其实很难保证绝对公平,因为每篇paper使用的trick都不尽相同。所以我们在这里报告了两个结果,一个是ResNet101不加入任何trick直接使用TridentNet的结果,一个是和大家一样加入了全部trick(包括sync BN,multi-scale training/testing,deformable conv,soft-nms)的结果。在这样的两个setting下,分别取得了在COCO test-dev集上42.7和48.4的结果。这应该分别是这样两个setting下目前最佳的结果。single branch approximation也分别取得了42.2和47.6的map,不过这可是比baseline不增加任何计算量和参数量的情况下得到的。
最后的最后,我们会在本月内开源整套训练代码,可以很方便复现TridentNet结果以及各种常见trick。这个框架下也包含了其他Detection和Instance Segmentation方面的经典工作,敬请期待!
---End---
想要了解最新最快最好的论文速递、开源项目和干货资料,欢迎加入CVer学术交流群。涉及图像分类、目标检测、图像分割、人脸检测&识别、目标跟踪、GANs、学术竞赛交流、Re-ID、风格迁移、医学影像分析、姿态估计、OCR、SLAM、场景文字检测&识别和超分辨率等方向。

扫码进群
这么硬的论文速递,麻烦给我一个好看

▲长按关注我们
麻烦给我一个好看!




