深度学习之CNN简介
本来想把CNN的一个kaggle比赛和这个放在一起,结果软件一直出问题。就先把这部分贴上。后面再奉上CNN实战的代码。
深度学习概述
传统的机器学习和深度学习一个很重要的差别就是特征的自动提取。深度学习现在更适合处理一些原始信息的特征,比如图片识别,音频,视频等。比如图片可以通过像素作为原始的特征,通过卷积神经网络不断的提取特征,最后再在这些特征上进行学习。对于音频就是通过声音的声波作为特征。
深度学习可以参考书籍:https://item.jd.com/12128543.html
深度学习的课程可以参考:https://www.coursera.org/learn/neural-networks/home
本节主要是讲解图像识别案例,这里就稍微提一下。
CNN(卷积神经网络)
图像识别中采用卷积神经网络,这里大致的介绍下CNN的运行原理。在很久以前呢其实图像识别采用的是传统的方法,比如SVM。在12年的ImageNet大会中,来自多伦多大学的 Geoffrey Hinton、Ilya Sutskever 和 Alex Krizhevsky 提交了名为“AlexNet”的深度卷积神经网络算法,这种算法的图形识别错误率低至 16%,比第二名低超过 40%。可以这么说,人工智能在“看特定的图”这件事上第一次接近了人类。
这里提一下上面提到的深度学习课程就是由Geoffrey Hinton 讲授的。
而图像识别中的神经网络一般会采用卷积神经网络,即CNN。
层级结构
一般的神经网络采用了全连接的方式,这样的话会导致参数量太大。Cnn以及rnn都修改了网络结构以使其能达到特定的功能。
全连接的神经网络如下:
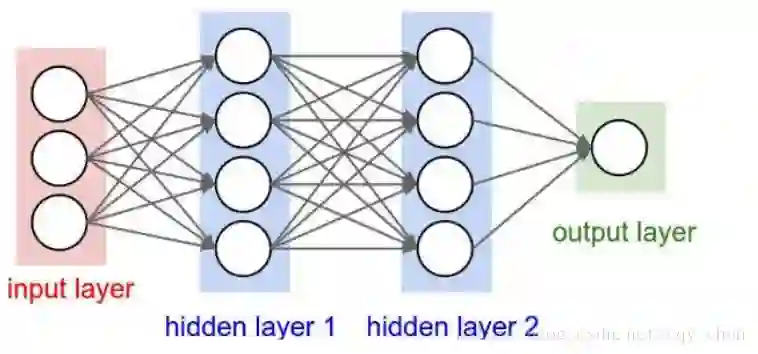
隐层的话其实可以是0~N多层,如果没有隐层,而激活函数又采用了逻辑函数,那么就成了逻辑回归模型了。这里只画了两层。
而卷积神经网络主要有以下几种层次
1)数据输入层
2)卷积计算层
3)Relu激活层
4)池化层
5)全连接层
6)输出层
数据输入层
数据输入层和全连接层一样的,就是第0层。一般来说图形图像处理前需要进行数据的预处理,比如图片的大小放缩到一致,主要有如下的处理方法:
1)去均值,比如一个图片的像素,RGB形式的吧,范围都在0~256之间。将其都减去均值,得到每个特征的维度均值为0.
2)归一化,就是降维度的数值缩放到一个幅度内。
3)降维
卷积计算层
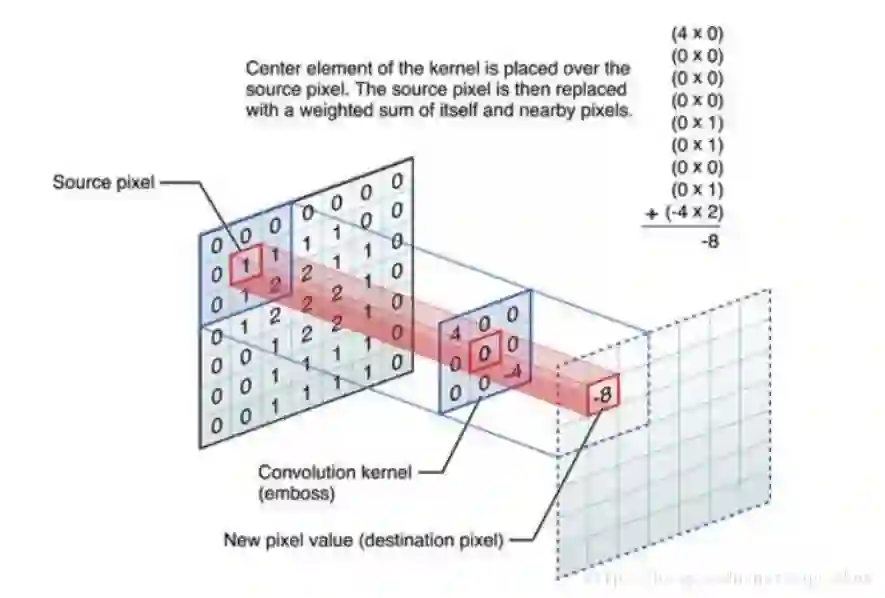
这个应该是CNN的一个比较关键的地方了,首先看卷积运算,卷积是对两个实变函数的一种数学运算。这里不想讲的太复杂,比如
这里x是输入,w是核函数就是需要将x转换到其他的特征中。下面将二维平面的情况展示: 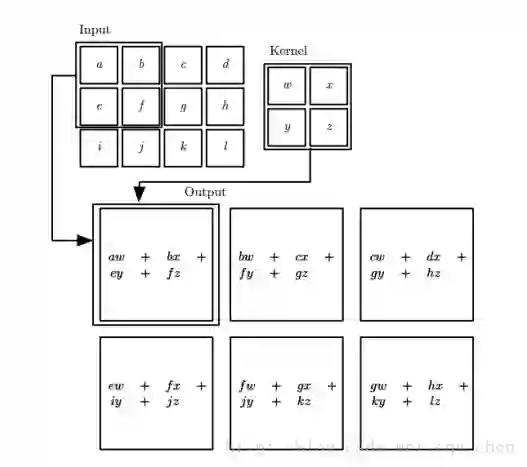
这是进行了一次的卷积运算,这里我们很明显的知道参数共享的。在一次卷积运算的过程中,这些kernel是保持不变的。变得是每次滑动窗口的数据。
这里介绍三个相关的概念:
1)步长,如上图是1。
2)滑动窗口,上面的是一个2*2的大小。
3)填充值,因为在步长大于1的情况下,可能导致滑动窗口在向右移动的过程中,右边没有值了,这个时候需要值进行填充,一般采用0值填充。还有一个原因就是当步长为1的时候,如果不进行填充会导致输出的维度低于输入的维度,这样经过几次迭代,就没有输入了……
形象化的如下图,周围补了一圈的0填充。
注意这里只是一个下一层的一个神经元的情况如果是n个,就会有n次卷积运算了。
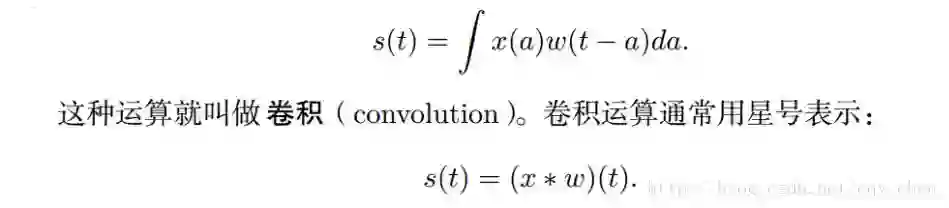
Relu激活层
当通过卷积运算之后需要经过激活函数进行非线性变换。常的激活函数如下:
1)Sigmoid
2)Relu
3)Tanh
4)Elu
5)Maxout
6)Leaky relu
可以参考:https://en.wikipedia.org/wiki/Activation_function
在cnn中有如下一些经验:
1)CNN尽量不要用sigmoid ,因为sigmoid会导致梯度消失问题。
2)首先使用relu
3)然后使用leaky relu
4)如果不行,采用maxout

池化层
由于图片的像素点很多,如果不进行压缩处理,那么会导致参数过多,就过拟合啦。所以需要将图片大小进行压缩。那咋个压缩呢?只能采用下采样啦。如下图所示: 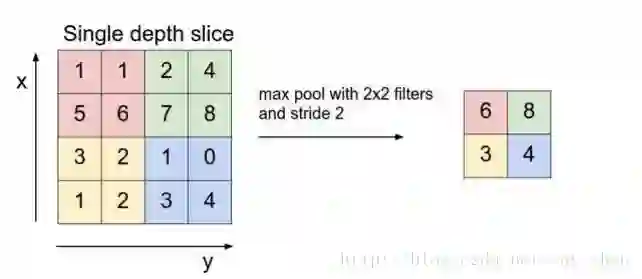
这个有点像卷积计算,但是呢,没有kernel。一般采用的是
1)Max
2)Average
两种下采样方式,不过用的多的还是max。因为average会带来新的特征值,不太好。
全连接层
经过了若干的卷积层,池化层,在输出层的前一层,加一个全连接层,用于最后的输出。
输出层
最后就是再次通过一个激活函数输出数据了。
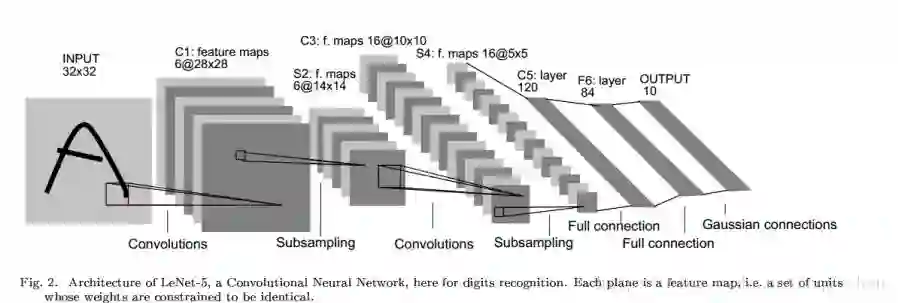
总的层级结构如下: 
一般来说,CNN的结构中,会有若干的卷积层,然后通过激活层,然后池化,然后继续卷积等等,最后全连接输出数据。不过有的也不用全连接做最后一层,用一维的卷积层代替。
正则化
在深度学习中,优化算法基本都是采用的SGD。正则化不是像传统的方式L1或者L2。而是通过一定的概率丢弃神经网络节点,这就被称为dropout
如下图所示,每次运算的时候随机的使一些节点失效。或者可以理解,选择神经节点服从一个概率分布。 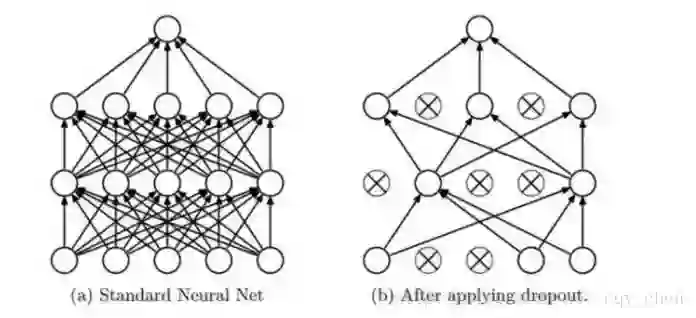
通过dropout的方式可以防止过拟合
1)神经元的个数少了,参数减小,那么根据机器学习的VC维可以得到过拟合风险减小。
2)通过随机的丢弃一些神经元,可以组成不同的神经网络,最后做到一个aggregation的神经网络,就像随机森林一样的的想法。
典型结构
CNN常见的结构有:
1)LeNet ,最早用于数字识别
2)AlexNet ,2012年的视觉大赛冠军
3)ZF Net,2013年的视觉大赛冠军
4)Google Net,2014年
5)VGG Net,2014年
6)ResNet,2015年,152层。
具体可以参考:http://blog.csdn.net/u012905422/article/details/53312302
计算机视觉竞赛可以参考:http://image-net.org/ 里面每年的winner可以看看其使用的结构。