你有哪些深度学习(rnn、cnn)调参的经验?

你有哪些深度学习(rnn、cnn)调参的经验?
解析:
解析一
@陈运文:cnn的调参主要是在优化函数、embedding的维度还要残差网络的层数几个方面。
优化函数方面有两个选择:sgd、adam,相对来说adam要简单很多,不需要设置参数,效果也还不错。
embedding随着维度的增大会出现一个最大值点,也就是开始时是随维度的增加效果逐渐变好,到达一个点后,而后随维度的增加,效果会变差。
残差网络的层数与embedding的维度有关系,随层数的增加,效果变化也是一个凸函数。
另外还有激活函数,dropout层和batchnormalize层的使用。激活函数推荐使用relu,dropout层数不易设置过大,过大会导致不收敛,调节步长可以是0.05,一般调整到0.4或者0.5就可找到最佳值。
以上是个人调参的一些经验,可供参考。
解析二
一、参数初始化
下面几种方式,随便选一个,结果基本都差不多。但是一定要做。否则可能会减慢收敛速度,影响收敛结果,甚至造成Nan等一系列问题。
下面的n_in为网络的输入大小,n_out为网络的输出大小,n为n_in或(n_in+n_out)*0.5
Xavier初始法论文:http://jmlr.org/proceedings/papers/v9/glorot10a/glorot10a.pdf
He初始化论文:https://arxiv.org/abs/1502.01852
A)uniform均匀分布初始化:w = np.random.uniform(low=-scale, high=scale, size=[n_in,n_out])
①Xavier初始法,适用于普通激活函数(tanh,sigmoid):scale = np.sqrt(3/n)
②He初始化,适用于ReLU:scale = np.sqrt(6/n)
B)normal高斯分布初始化:w = np.random.randn(n_in,n_out) * stdev # stdev为高斯分布的标准差,均值设为0
①Xavier初始法,适用于普通激活函数 (tanh,sigmoid):stdev = np.sqrt(n)
②He初始化,适用于ReLU:stdev = np.sqrt(2/n)
C)svd初始化:对RNN有比较好的效果。参考论文:https://arxiv.org/abs/1312.6120
二、数据预处理方式
zero-center ,这个挺常用的.X -= np.mean(X, axis = 0) # zero-centerX /= np.std(X, axis = 0) # normalize
PCA whitening,这个用的比较少.
三、训练技巧
要做梯度归一化,即算出来的梯度除以minibatch size
clip c(梯度裁剪): 限制最大梯度,其实是value = sqrt(w1^2+w2^2….),如果value超过了阈值,就算一个衰减系系数,让value的值等于阈值: 5,10,15
dropout对小数据防止过拟合有很好的效果,值一般设为0.5,小数据上dropout+sgd在我的大部分实验中,效果提升都非常明显.因此可能的话,建议一定要尝试一下。 dropout的位置比较有讲究, 对于RNN,建议放到输入->RNN与RNN->输出的位置.关于RNN如何用dropout,可以参考这篇论文:http://arxiv.org/abs/1409.2329
adam,adadelta等,在小数据上,我这里实验的效果不如sgd, sgd收敛速度会慢一些,但是最终收敛后的结果,一般都比较好。如果使用sgd的话,可以选择从1.0或者0.1的学习率开始,隔一段时间,在验证集上检查一下,如果cost没有下降,就对学习率减半. 我看过很多论文都这么搞,我自己实验的结果也很好. 当然,也可以先用ada系列先跑,最后快收敛的时候,更换成sgd继续训练.同样也会有提升.据说adadelta一般在分类问题上效果比较好,adam在生成问题上效果比较好。
除了gate之类的地方,需要把输出限制成0-1之外,尽量不要用sigmoid,可以用tanh或者relu之类的激活函数.1. sigmoid函数在-4到4的区间里,才有较大的梯度。之外的区间,梯度接近0,很容易造成梯度消失问题。2. 输入0均值,sigmoid函数的输出不是0均值的。
rnn的dim和embdding size,一般从128上下开始调整. batch size,一般从128左右开始调整.batch size合适最重要,并不是越大越好.
word2vec初始化,在小数据上,不仅可以有效提高收敛速度,也可以可以提高结果.
四、尽量对数据做shuffle
LSTM 的forget gate的bias,用1.0或者更大的值做初始化,可以取得更好的结果,来自这篇论文:http://jmlr.org/proceedings/papers/v37/jozefowicz15.pdf, 我这里实验设成1.0,可以提高收敛速度.实际使用中,不同的任务,可能需要尝试不同的值.
Batch Normalization据说可以提升效果,不过我没有尝试过,建议作为最后提升模型的手段,参考论文:Accelerating Deep Network Training by Reducing Internal Covariate Shift
如果你的模型包含全连接层(MLP),并且输入和输出大小一样,可以考虑将MLP替换成Highway Network,我尝试对结果有一点提升,建议作为最后提升模型的手段,原理很简单,就是给输出加了一个gate来控制信息的流动,详细介绍请参考论文: http://arxiv.org/abs/1505.00387
来自@张馨宇的技巧:一轮加正则,一轮不加正则,反复进行。
五、Ensemble
Ensemble是论文刷结果的终极核武器,深度学习中一般有以下几种方式
同样的参数,不同的初始化方式
不同的参数,通过cross-validation,选取最好的几组
同样的参数,模型训练的不同阶段,即不同迭代次数的模型。
不同的模型,进行线性融合. 例如RNN和传统模型.
解析三
@罗浩.ZJU:其实我发现现在深度学习越来越成熟,调参工作比以前少了很多,绝大多数情况自己设计的参数都不如教程和框架的默认参数好,不过有一些技巧我一直都在用的
(1)relu+bn。这套好基友组合是万精油,可以满足95%的情况,除非有些特殊情况会用identity,比如回归问题,比如resnet的shortcut支路,sigmoid什么的都快从我世界里消失了
(2)dropout 。分类问题用dropout ,只需要最后一层softmax 前用基本就可以了,能够防止过拟合,可能对accuracy提高不大,但是dropout 前面的那层如果是之后要使用的feature的话,性能会大大提升
(3)数据的shuffle 和augmentation 。这个没啥好说的,aug也不是瞎加,比如行人识别一般就不会加上下翻转的,因为不会碰到头朝下的异型种
(4)降学习率。随着网络训练的进行,学习率要逐渐降下来,如果你有tensorboard,你有可能发现,在学习率下降的一瞬间,网络会有个巨大的性能提升,同样的fine-tuning也要根据模型的性能设置合适的学习率,比如一个训练的已经非常好的模型你上来就1e-3的学习率,那之前就白训练了,就是说网络性能越好,学习率要越小
(5)tensorboard。以前不怎么用,用了之后发现太有帮助,帮助你监视网络的状态,来调整网络参数
(6)随时存档模型,要有validation 。这就跟打游戏一样存档,把每个epoch和其对应的validation 结果存下来,可以分析出开始overfitting的时间点,方便下次加载fine-tuning
(7)网络层数,参数量什么的都不是大问题,在性能不丢的情况下,减到最小
(8)batchsize通常影响没那么大,塞满卡就行,除了特殊的算法需要batch大一点
(9)输入减不减mean归一化在有了bn之后已经不那么重要了
上面那些都是大家所知道的常识,也是外行人觉得深度学习一直在做的就是这些很low的东西,其实网络设计上博大精深,这也远超过我的水平范畴,只说一些很简单的
(10)卷积核的分解。从最初的5×5分解为两个3×3,到后来的3×3分解为1×3和3×1,再到resnet的1×1,3×3,1×1,再xception的3×3 channel-wise conv+1×1,网络的计算量越来越小,层数越来越多,性能越来越好,这些都是设计网络时可以借鉴的
(11)不同尺寸的feature maps的concat,只用一层的feature map一把梭可能不如concat好,pspnet就是这种思想,这个思想很常用
(12)resnet的shortcut确实会很有用,重点在于shortcut支路一定要是identity,主路是什么conv都无所谓,这是我亲耳听resnet作者所述
(13)针对于metric learning,对feature加个classification 的约束通常可以提高性能加快收敛
题目来源:七月在线官网(www.julyedu.com)——面试题库——面试大题——深度学习

今日学习推荐
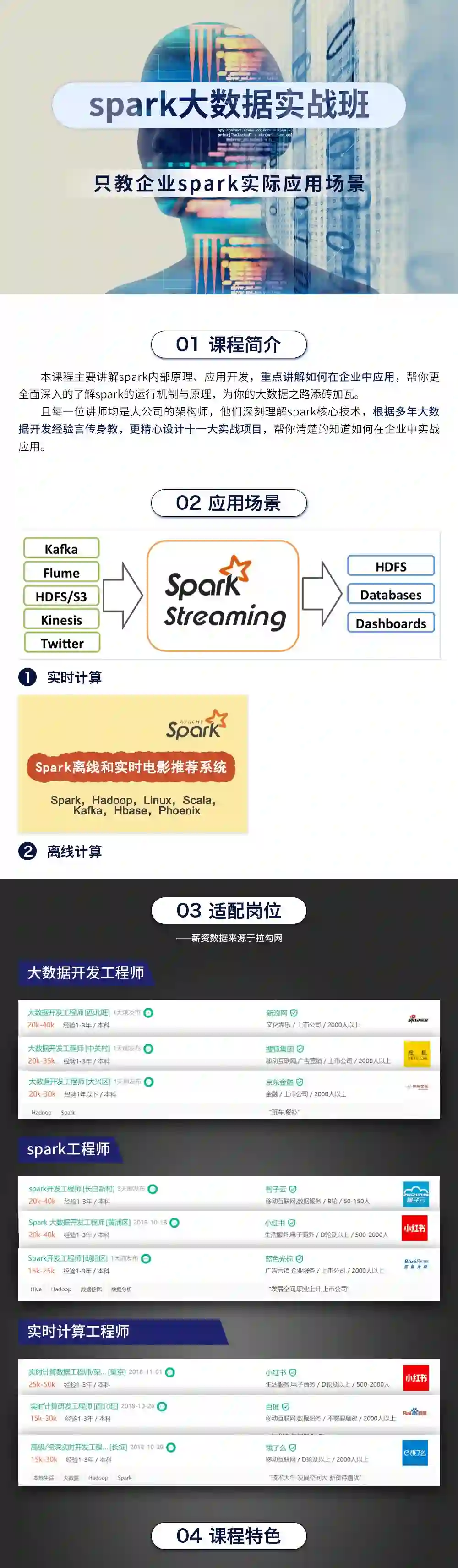
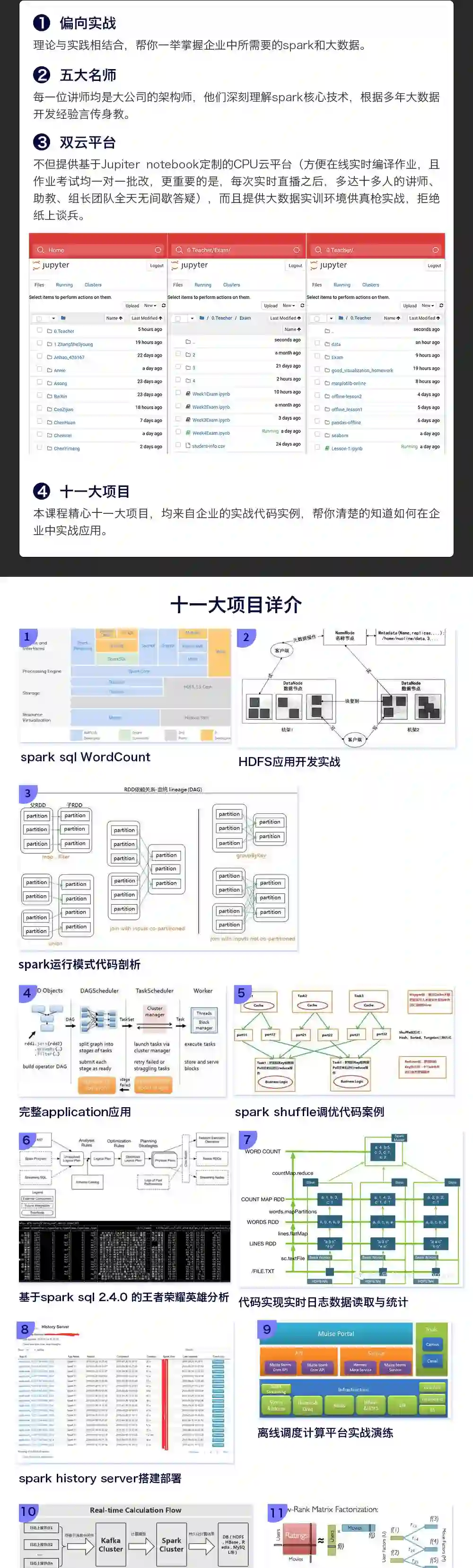
spark大数据实战班
只交企业spark实际应用场景

更多课程详情扫描二维码获取:

END
扫描下方二维码 关注:七月在线实验室
后台回复:100 免费领取【机器学习面试100题】PDF版一份







