深度学习时代的目标检测算法综述

这或许是计算机视觉领域内最著名的问题。它主要指将一张图像归为某种类别。学术界最流行的一类数据集是ImageNet,由数以百万计已分好类的图像组成,部分用于年度ImageNet大规模视觉识别挑战比赛(ILSVRC)。近年来,分类模型已经超过了人类的表现,因此该问题基本算是一个已经解决的问题。图像分类领域有许多挑战,但是也有许多文章介绍已经解决了的,以及未解决的挑战。

分类样例
与分类类似,定位问题是找到图像中单一物体的位置。

目标定位示例
目标定位在实际生活中是很有用的。例如,智能裁剪(根据目标所在位置来裁剪图像),甚至对规则目标进行提取,以使用不同技术对其进行进一步处理。它可以与分类相结合,不仅可以定位对象,还可以将其进行分类。
从目标检测再进一步,我们不仅想在图像中找到目标,而且要找到每一个被检测目标的像素级掩膜。我们将此问题称为实例或目标分割。
将定位以及分类问题结合起来,最终我们需要同时检测和分类多个目标。目标检测是在图像上定位和分类数量可变的对象的问题。重要的区别是“变量”部分。与分类问题相比,目标检测的输出数量是可变的,因为对于每幅图来说,检测到的目标数目可能是不同的。在本文中,我们将介绍目标检测实际应用的细节,以及它作为一个机器学习问题,存在的主要问题是什么,过去几年中,解决该问题的方式是如何一步步变成深度学习的。

目标检测示例
在Tryolabs,我们专门从事应用最先进的机器学习技术来解决商业问题,所以即使我们热爱所有疯狂的机器学习研究问题,但是最后我们更多是在考虑实际应用问题。
尽管目标检测在工业界仍然是一个新工具,但已经有许多使用目标检测技术的实用而有趣的应用了。
自2000年年中,一些傻瓜相机已经开始自带人脸检测功能,能够进行更有效地自动对焦。虽然这只是目标检测的一种狭义类型,但它所使用的方法也适用于其他类型的目标,我们将在后面详述。
目标检测的一个很简单但常常被忽视的用途是计数。统计人、汽车、花卉甚至微生物数量的能力是各种图像信息系统应该要具备的。最近,随着视频监控设备的激增,其中蕴藏着前所未有的使用计算机视觉方法将原始信息转化为结构化数据的机会。
我们都很喜欢Pinterest视觉搜索引擎。他们使用目标检测技术作为系统的一部分,用于索引图像中的不同部分。这样,当你搜索某个特定的提包时,你能搜到你想要的手提袋在不同场景下的图像。这个功能比谷歌图像的反向搜索引擎要强大得多。
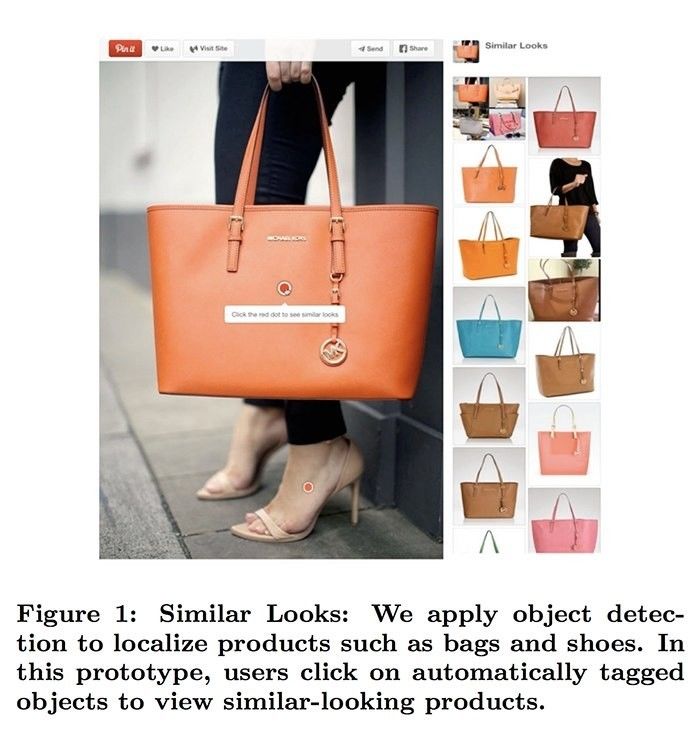
相似图像:我们应用目标检测技术来定位包或者鞋子这类产品。在这个例子中,用户可以点击自动标注好的物体去查看相似的产品。(Pinterest论文中的例子)
Jing,Yushi。 《Pinterest的视觉搜索》(Visual Search at Pinterest.)
在拥有廉价的无人机和(几乎)负担得起的卫星发射服务之前,从未有过如此多的地球俯瞰图。已经有公司开始使用来自Planet和Descartes Labs公司的卫星图像,应用目标检测技术进行车辆、树木和船只的数量统计。它带来了高质量的图像,这在以前是不可能的(或非常昂贵的),现在使用它的人已经越来越多了。
一些公司用无人机来自动勘察人类难以进入的区域(例如Betterview),或使用目标检测技术进行一般性的分析(如TensorFlight)。除此之外,一些公司在没有人工干预的情况下使用这种技术进行自动检测和定位问题。

TensorFlight
让我们开始深入研究目标检测的主要问题。
我们前面已经提到关于图片中目标数量可变的问题,但我们忽视了为什么它会成为一个问题。训练机器学习模型时,通常需要将数据表示成固定大小的向量。由于事先不知道图像中目标的数量,所以我们不知道正确的输出数量。正因为如此,我们需要一些后续处理,这也增加了模型的复杂度。
这种输出数量不定的问题已经使用基于滑动窗口的方法得到了解决,在图片的不同位置得到滑窗的固定大小特征。在得到所有的预测值之后,一些滑窗被丢弃,一些被合并,从而得到最终输出。
另一个大挑战是目标的大小不一致问题。当进行简单分类时,我们希望能对占图像比例最大的目标进行分类。另一方面,想要找到的目标可能只有几个像素大小(或只占原始图像的很小一部分)。传统方法使用不同大小的滑动窗口解决了这一问题,这种方法虽然简单但是效率很低。
第三个挑战是同时解决两个问题。我们如何将定位和分类这两种不同类型的问题最理想地结合进一个单一模型?
在接着介绍深度学习和如何应对这些挑战之前,让我们快速地回顾一下经典方法。
尽管近年来已经有很多不同类型的方法,我们主要介绍两个最流行的(现在依然广泛使用)。
第一个是2001年Paul Viola和Michael Jones在论文《鲁棒实时目标检测》中提出的Viola Jones框架。该方法快速并且相对简单,因此傻瓜相机的人脸检测就是使用这个算法,它能做到实时检测,并且运算量很小。
我们不会介绍它运作的底层细节以及如何训练它,但会介绍它的高层算法。它的工作原理是使用Haar特征产生多种(可能有数千个)简单的二进制分类器。这些分类器由级联的多尺度滑动窗口进行评估,并且在出现消极分类情况的早期及时丢弃错误分类。
另一个类似的经典方法是采用梯度方向直方图(Histogram of Oriented Gradients,HOG)作为特征,以及支持向量机(SVM)作为分类器。它仍然依赖多尺度滑动窗口,尽管它的效果比Viola Jones要好很多,但是速度也慢很多。
深度学习作为机器学习,尤其是计算机视觉中真正的“变革者”,已经是众人皆知了。与深度学习模型在图像分类任务上完全碾压其他经典模型类似,深度学习模型在目标检测领域也是最好的方法。
现在,你已经对目标检测的挑战是什么有了更直观的了解,也知道了如何解决这些问题,下面我们会对过去几年深度学习方法在目标检测领域的演变过程做一个综述介绍。
第一个使用深度学习进行目标检测并取得很大进展的方法是纽约大学在2013年提出的Overfeat。他们提出了一个使用卷积神经网络(CNN)的多尺度滑动窗口算法。
在Overfeat提出不久,来自加州大学伯克利分校的Ross Girshick等人发表了基于卷积神经网络特征的区域方法(Regions with CNN features,R-CNN),它在目标检测比赛上相比其他方法取得了50%的性能提升。他们提出了一个三阶段的方法:
使用区域候选算法提取包含可能目标的区域(最流行的选择性搜索算法)
使用CNN在每个区域上提取特征。
使用支持向量机对区域进行分类。
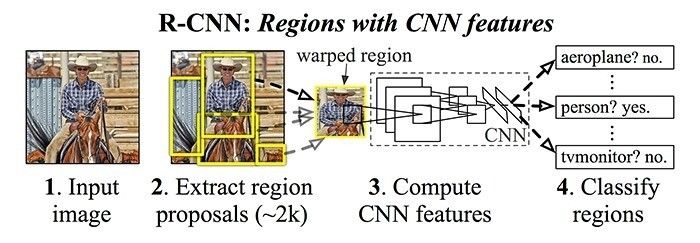
6Girshick, Ross, et al. "Rich feature hierarchies for accurate object detection and semantic segmentation." 2014.
虽然该方法取得了很好的结果,但是训练阶段有很多问题。要训练网络,首先要生成训练数据集的候选区域,然后对每一个区域使用CNN提取特征(对于Pascal 2012训练数据集来说,通常需要生成大于200GB的中间文件),最后训练SVM分类器。
一年以后,Ross Girshick(微软亚洲研究院)发表了Fast R-CNN,这个方法迅速演化成一个纯深度学习的方法。与R-CNN相似,它也使用选择性搜索来生成候选区域,但与R-CNN不同的是,Fast R-CNN在整张图上使用CNN来提取特征,然后在特征图上使用区域兴趣池化(Region of Interest,ROI),并且最后用前馈神经网络来进行分类和回归。这个方法不仅快,而且由于RoI池化层和全连接层的存在,该模型可以进行端到端的求导,并且训练也更容易。最大的不足是该模型仍旧依赖选择性搜索(或者其他的区域候选算法),这也成为了模型推理阶段的一个瓶颈。
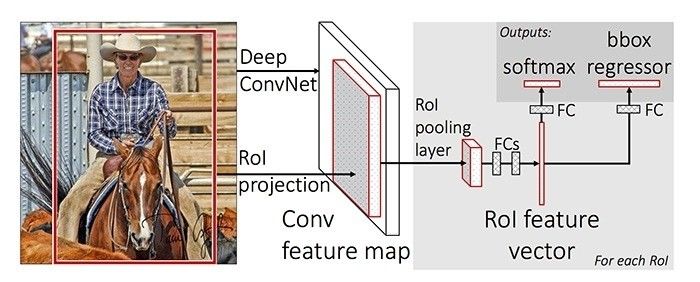
7Girshick, Ross. "Fast R-CNN" 2015.
不久之后,Joseph Redmon(Girshick也是共同作者之一)发表了一篇名为《你只用看一遍:统一框架的实时目标检测》(You Only Look Once: Unified, Real-Time Object Detection(YOLO))的论文。YOLO提出了一个简单的卷积神经网络方法,它取得了很好的结果,并且速度也非常快,第一次实现了实时的目标检测。

Redmon, Joseph, et al. "You only look once: Unified, real-time object detection." 2016.
随后,任少卿(Girshick也作为共同作者,现在Facebook研究院)发表了Faster R-CNN,这是R-CNN系列的第三代。Faster R-CNN增加了一个所谓的“区域候选网络(Regio Proosal Network,RPN)”,试图摆脱搜索选择算法,从而让模型实现完全端到端的训练。我们不会详细介绍RPN的原理,不过简单地说,它的作用是根据“属于目标”的分数来输出可能目标。RoI池化层和全连接层使用这些目标进行分类。我们会在后续的博客中详细介绍该结构的细节。
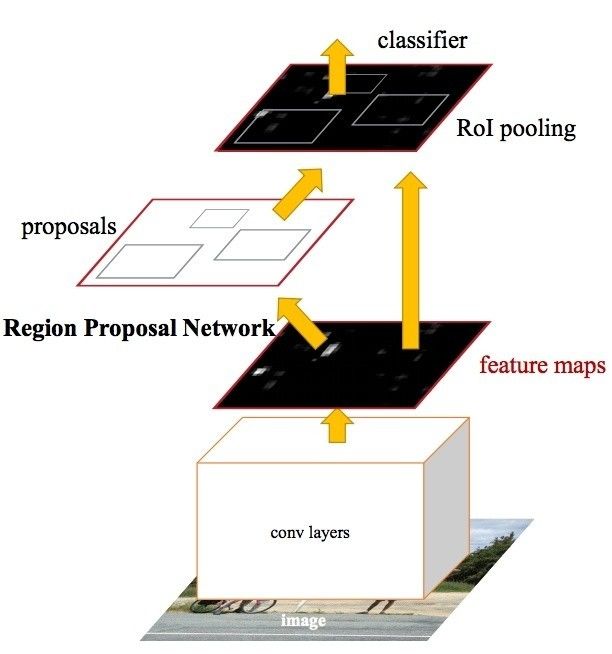
9Ren, Shaoqing, et al. "Faster R-CNN: Towards real-time object detection with region proposal networks." 2015.
最后,有两篇著名的论文,《单帧检测器》(Single Shot Detector,SSD),它在YOLO的基础上进行改良,通过使用多尺度的卷积特征图以达到更好的结果和速度,以及《基于区域的全卷积网络》(Region-based Fully Convolutional Networks,R-FCN),它使用了Faster RCNN的架构,但是只含有卷积网络。
在研究中,数据集起到非常重要的作用(有时被低估了)。每当一个新的数据集发布以后,新的论文接踵而至,新的模型被互相比较,不断进步,把可能性推向极致。
不幸的是,目标检测的数据集不是太多。数据比较难(也很昂贵)获得,公司可能不愿意免费发布他们投资的产品,而大学又没有足够的资源。
不过现在依然有一些很好的数据集,下面是一些主要的公开数据集:
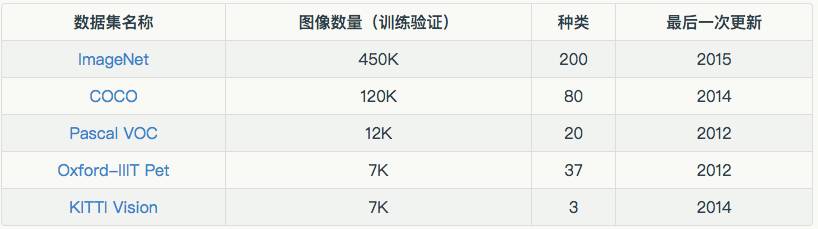
数据集名称 图像数量(训练验证) 种类 最后一次更新ImageNet 450K 200 2015COCO 120K 80 2014Pascal VOC 12K 20 2012Oxford-IIIT Pet 7K 37 2012KITTI Vision 7K 3 2014
总而言之,目标检测领域现在有很多机会,不管是在未知的应用还是在提出新方法推进领域内最先进的效果上。尽管这只是一个目标检测的概述,我希望它能让你们对目标检测有一个基本了解,从而引导你们了解深度知识。
后面几周,我们会做关于目标检测框架实现的细节、评估标准以及训练模型方法的系列文章。我们也会尝试将过去的目标检测算法应用到其他问题上。
查看英文原文:
https://tryolabs.com/blog/2017/08/30/object-detection-an-overview-in-the-age-of-deep-learning/
【好课推荐】斯达克学院(StuQ)倾心打造《3个月掌握Python机器学习》大课,专为对机器学习感兴趣、想从事相关职业的零基础学员打造,带领学员全面系统地掌握Python机器学习的相关知识,并能够胜任Python机器学习中级工程师及以上的工作。现团购价只要1999,感兴趣请添加小助手详细咨询。







