【深度学习】干货:目标检测入门,看这篇就够了
目标检测入门,看这篇就够了(上)

作者 | 李家丞( 同济大学数学系本科在读,现格灵深瞳算法部实习生)
近年来,深度学习模型逐渐取代传统机器视觉方法而成为目标检测领域的主流算法,本系列文章将回顾早期的经典工作,并对较新的趋势做一个全景式的介绍,帮助读者对这一领域建立基本的认识。(营长注:因本文篇幅较长,营长将其分为上、下两部分。)
导言:目标检测的任务表述
如何从图像中解析出可供计算机理解的信息,是机器视觉的中心问题。深度学习模型由于其强大的表示能力,加之数据量的积累和计算力的进步,成为机器视觉的热点研究方向。
那么,如何理解一张图片?根据后续任务的需要,有三个主要的层次。
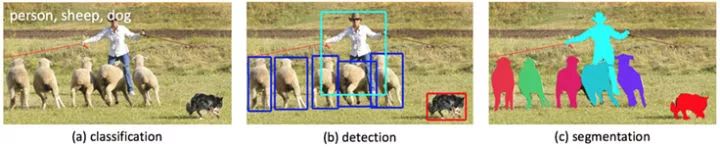
图像理解的三个层次
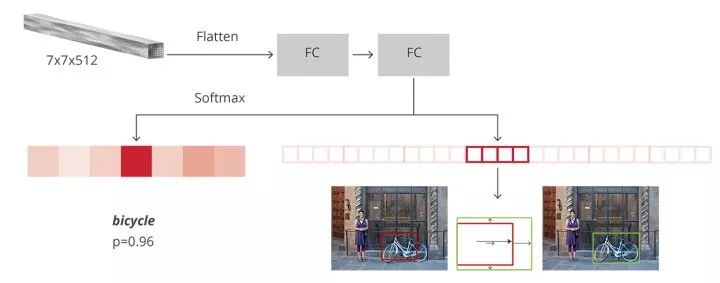
一是分类(Classification),即是将图像结构化为某一类别的信息,用事先确定好的类别(string)或实例ID来描述图片。这一任务是最简单、最基础的图像理解任务,也是深度学习模型最先取得突破和实现大规模应用的任务。其中,ImageNet是最权威的评测集,每年的ILSVRC催生了大量的优秀深度网络结构,为其他任务提供了基础。在应用领域,人脸、场景的识别等都可以归为分类任务。
二是检测(Detection)。分类任务关心整体,给出的是整张图片的内容描述,而检测则关注特定的物体目标,要求同时获得这一目标的类别信息和位置信息。相比分类,检测给出的是对图片前景和背景的理解,我们需要从背景中分离出感兴趣的目标,并确定这一目标的描述(类别和位置),因而,检测模型的输出是一个列表,列表的每一项使用一个数据组给出检出目标的类别和位置(常用矩形检测框的坐标表示)。
三是分割(Segmentation)。分割包括语义分割(semantic segmentation)和实例分割(instance segmentation),前者是对前背景分离的拓展,要求分离开具有不同语义的图像部分,而后者是检测任务的拓展,要求描述出目标的轮廓(相比检测框更为精细)。分割是对图像的像素级描述,它赋予每个像素类别(实例)意义,适用于理解要求较高的场景,如无人驾驶中对道路和非道路的分割。
本系列文章关注的领域是目标检测,即图像理解的中层次。
▌目标检测入门(一):目标检测经典模型回顾
本文结构
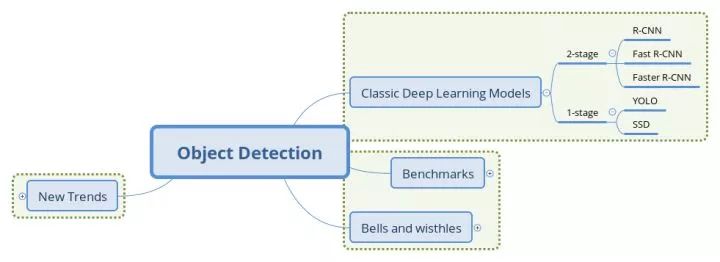
两阶段(2-stage)检测模型
两阶段模型因其对图片的两阶段处理得名,也称为基于区域(Region-based)的方法,我们选取R-CNN系列工作作为这一类型的代表。
R-CNN: R-CNN系列的开山之作
Rich feature hierarchies for accurate object detection and semantic segmentation
论文链接:
https://arxiv.org/abs/1311.2524
本文的两大贡献:
1)CNN可用于基于区域的定位和分割物体;
2)监督训练样本数紧缺时,在额外的数据上预训练的模型经过fine-tuning可以取得很好的效果。
第一个贡献影响了之后几乎所有2-stage方法,而第二个贡献中用分类任务(Imagenet)中训练好的模型作为基网络,在检测问题上fine-tuning的做法也在之后的工作中一直沿用。
传统的计算机视觉方法常用精心设计的手工特征(如SIFT, HOG)描述图像,而深度学习的方法则倡导习得特征,从图像分类任务的经验来看,CNN网络自动习得的特征取得的效果已经超出了手工设计的特征。本篇在局部区域应用卷积网络,以发挥卷积网络学习高质量特征的能力。
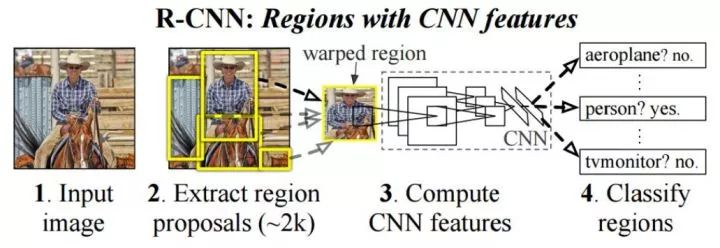
R-CNN网络结构
R-CNN将检测抽象为两个过程,一是基于图片提出若干可能包含物体的区域(即图片的局部裁剪,被称为Region Proposal),文中使用的是Selective Search算法;二是在提出的这些区域上运行当时表现最好的分类网络(AlexNet),得到每个区域内物体的类别。
另外,文章中的两个做法值得注意。
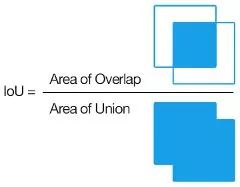
IoU的计算
一是数据的准备。输入CNN前,我们需要根据Ground Truth对提出的Region Proposal进行标记,这里使用的指标是IoU(Intersection over Union,交并比)。IoU计算了两个区域之交的面积跟它们之并的比,描述了两个区域的重合程度。
文章中特别提到,IoU阈值的选择对结果影响显著,这里要谈两个threshold,一个用来识别正样本(如跟ground truth的IoU大于0.5),另一个用来标记负样本(即背景类,如IoU小于0.1),而介于两者之间的则为难例(Hard Negatives),若标为正类,则包含了过多的背景信息,反之又包含了要检测物体的特征,因而这些Proposal便被忽略掉。
另一点是位置坐标的回归(Bounding-Box Regression),这一过程是Region Proposal向Ground Truth调整,实现时加入了log/exp变换来使损失保持在合理的量级上,可以看做一种标准化(Normalization)操作。
小结
R-CNN的想法直接明了,即将检测任务转化为区域上的分类任务,是深度学习方法在检测任务上的试水。模型本身存在的问题也很多,如需要训练三个不同的模型(proposal, classification, regression)、重复计算过多导致的性能问题等。尽管如此,这篇论文的很多做法仍然广泛地影响着检测任务上的深度模型革命,后续的很多工作也都是针对改进这一工作而展开,此篇可以称得上"The First Paper"。
Fast R-CNN: 共享卷积运算
Fast R-CNN
论文链接:
https://arxiv.org/abs/1504.08083
文章指出R-CNN耗时的原因是CNN是在每一个Proposal上单独进行的,没有共享计算,便提出将基础网络在图片整体上运行完毕后,再传入R-CNN子网络,共享了大部分计算,故有Fast之名。
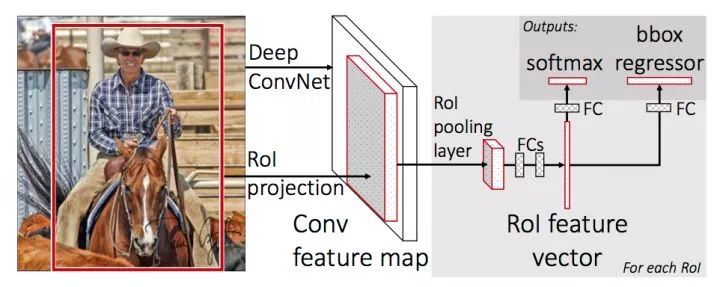
Fast R-CNN网络结构
上图是Fast R-CNN的架构。图片经过feature extractor得到feature map, 同时在原图上运行Selective Search算法并将RoI(Region of Interset,实为坐标组,可与Region Proposal混用)映射到到feature map上,再对每个RoI进行RoI Pooling操作便得到等长的feature vector,将这些得到的feature vector进行正负样本的整理(保持一定的正负样本比例),分batch传入并行的R-CNN子网络,同时进行分类和回归,并将两者的损失统一起来。
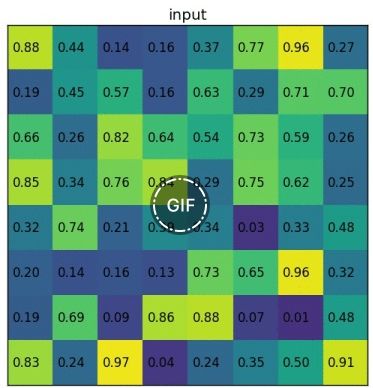
RoI Pooling图示,来源:https://blog.deepsense.ai/region-of-interest-pooling-explained/
RoI Pooling 是对输入R-CNN子网络的数据进行准备的关键操作。我们得到的区域常常有不同的大小,在映射到feature map上之后,会得到不同大小的特征张量。RoI Pooling先将RoI等分成目标个数的网格,再在每个网格上进行max pooling,就得到等长的RoI feature vector。
文章最后的讨论也有一定的借鉴意义:
multi-loss traing相比单独训练classification确有提升
multi-scale相比single-scale精度略有提升,但带来的时间开销更大。一定程度上说明CNN结构可以内在地学习尺度不变性
在更多的数据(VOC)上训练后,精度是有进一步提升的
Softmax分类器比"one vs rest"型的SVM表现略好,引入了类间的竞争
更多的Proposal并不一定带来精度的提升
小结
Fast R-CNN的这一结构正是检测任务主流2-stage方法所采用的元结构的雏形。
文章将Proposal, Feature Extractor, Object Classification&Localization统一在一个整体的结构中,并通过共享卷积计算提高特征利用效率,是最有贡献的地方。
Faster R-CNN: 两阶段模型的深度化
Faster R-CNN: Towards Real Time Object Detection with Region Proposal Networks
论文链接:
https://arxiv.org/abs/1506.01497
Faster R-CNN是2-stage方法的奠基性工作,提出的RPN网络取代Selective Search算法使得检测任务可以由神经网络端到端地完成。粗略的讲,Faster R-CNN = RPN + Fast R-CNN,跟RCNN共享卷积计算的特性使得RPN引入的计算量很小,使得Faster R-CNN可以在单个GPU上以5fps的速度运行,而在精度方面达到SOTA(State of the Art,当前最佳)。
本文的主要贡献是提出Regional Proposal Networks,替代之前的SS算法。RPN网络将Proposal这一任务建模为二分类(是否为物体)的问题。
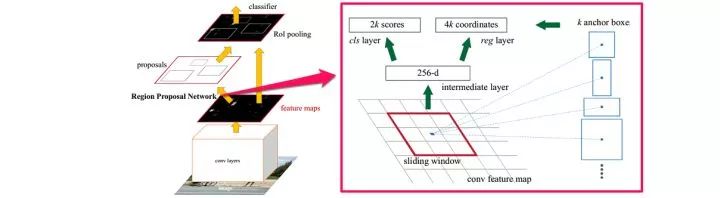
Faster R-CNN网络结构
第一步是在一个滑动窗口上生成不同大小和长宽比例的anchor box(如上图右边部分),取定IoU的阈值,按Ground Truth标定这些anchor box的正负。于是,传入RPN网络的样本数据被整理为anchor box(坐标)和每个anchor box是否有物体(二分类标签)。
RPN网络将每个样本映射为一个概率值和四个坐标值,概率值反应这个anchor box有物体的概率,四个坐标值用于回归定义物体的位置。最后将二分类和坐标回归的损失统一起来,作为RPN网络的目标训练。
由RPN得到Region Proposal在根据概率值筛选后经过类似的标记过程,被传入R-CNN子网络,进行多分类和坐标回归,同样用多任务损失将二者的损失联合。
小结
Faster R-CNN的成功之处在于用RPN网络完成了检测任务的"深度化"。使用滑动窗口生成anchor box的思想也在后来的工作中越来越多地被采用(YOLO v2等)。这项工作奠定了"RPN+RCNN"的两阶段方法元结构,影响了大部分后续工作。
单阶段(1-stage)检测模型
单阶段模型没有中间的区域检出过程,直接从图片获得预测结果,也被成为Region-free方法。
YOLO
You Only Look Once: Unified, Real-Time Object Detection
论文链接:
https://arxiv.org/abs/1506.02640
YOLO是单阶段方法的开山之作。它将检测任务表述成一个统一的、端到端的回归问题,并且以只处理一次图片同时得到位置和分类而得名。
YOLO的主要优点:
快。
全局处理使得背景错误相对少,相比基于局部(区域)的方法, 如Fast RCNN。
泛化性能好,在艺术作品上做检测时,YOLO表现比Fast R-CNN好。
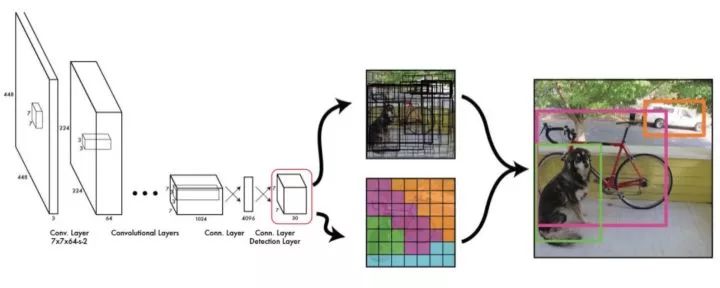
YOLO网络结构
YOLO的工作流程如下:
1.准备数据:将图片缩放,划分为等分的网格,每个网格按跟Ground Truth的IoU分配到所要预测的样本。
2.卷积网络:由GoogLeNet更改而来,每个网格对每个类别预测一个条件概率值,并在网格基础上生成B个box,每个box预测五个回归值,四个表征位置,第五个表征这个box含有物体(注意不是某一类物体)的概率和位置的准确程度(由IoU表示)。测试时,分数如下计算:
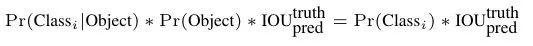
等式左边第一项由网格预测,后两项由每个box预测,以条件概率的方式得到每个box含有不同类别物体的分数。 因而,卷积网络共输出的预测值个数为S×S×(B×5+C),其中S为网格数,B为每个网格生成box个数,C为类别数。
3.后处理:使用NMS(Non-Maximum Suppression,非极大抑制)过滤得到最后的预测框
损失函数的设计
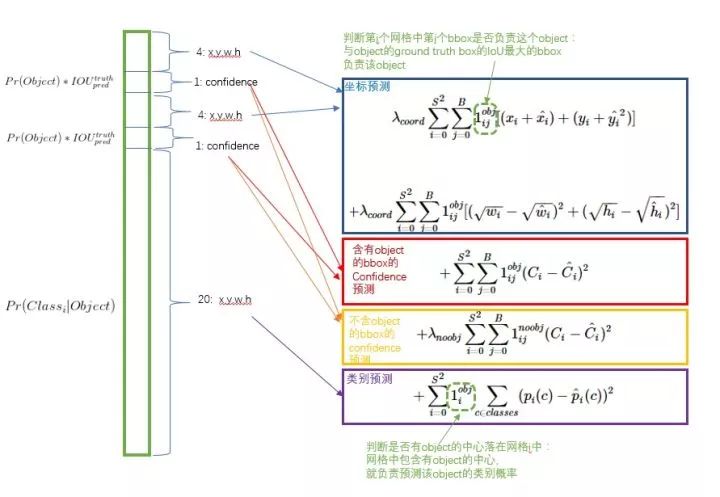
YOLO的损失函数分解,来源:https://zhuanlan.zhihu.com/p/24916786
损失函数被分为三部分:坐标误差、物体误差、类别误差。为了平衡类别不均衡和大小物体等带来的影响,损失函数中添加了权重并将长宽取根号。
小结
YOLO提出了单阶段的新思路,相比两阶段方法,其速度优势明显,实时的特性令人印象深刻。但YOLO本身也存在一些问题,如划分网格较为粗糙,每个网格生成的box个数等限制了对小尺度物体和相近物体的检测。
SSD: Single Shot Multibox Detector
SSD: Single Shot Multibox Detector
论文链接:
https://arxiv.org/abs/1512.02325
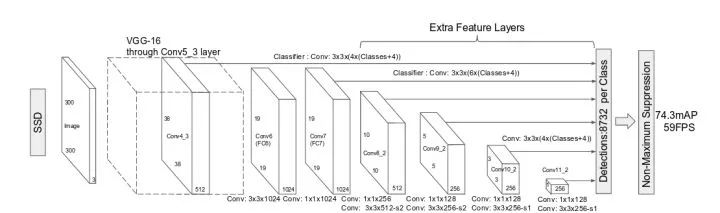
SSD网络结构
SSD相比YOLO有以下突出的特点:
多尺度的feature map:基于VGG的不同卷积段,输出feature map到回归器中。这一点试图提升小物体的检测精度。
更多的anchor box,每个网格点生成不同大小和长宽比例的box,并将类别预测概率基于box预测(YOLO是在网格上),得到的输出值个数为(C+4)×k×m×n,其中C为类别数,k为box个数,m×n为feature map的大小。
小结
SSD是单阶段模型早期的集大成者,达到跟接近两阶段模型精度的同时,拥有比两阶段模型快一个数量级的速度。后续的单阶段模型工作大多基于SSD改进展开。
检测模型基本特点
最后,我们对检测模型的基本特征做一个简单的归纳。
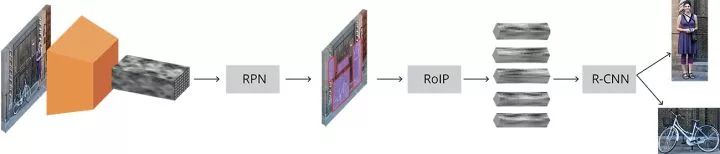
两阶段检测模型Pipeline,来源:https://tryolabs.com/blog/2018/01/18/faster-r-cnn-down-the-rabbit-hole-of-modern-object-detection/
检测模型整体上由基础网络(Backbone Network)和检测头部(Detection Head)构成。前者作为特征提取器,给出图像不同大小、不同抽象层次的表示;后者则依据这些表示和监督信息学习类别和位置关联。检测头部负责的类别预测和位置回归两个任务常常是并行进行的,构成多任务的损失进行联合训练。
检测模型头部并行的分支,来源同上
相比单阶段,两阶段检测模型通常含有一个串行的头部结构,即完成前背景分类和回归后,把中间结果作为RCNN头部的输入再进行一次多分类和位置回归。这种设计带来了一些优点:
对检测任务的解构,先进行前背景的分类,再进行物体的分类,这种解构使得监督信息在不同阶段对网络参数的学习进行指导
RPN网络为RCNN网络提供良好的先验,并有机会整理样本的比例,减轻RCNN网络的学习负担
这种设计的缺点也很明显:中间结果常常带来空间开销,而串行的方式也使得推断速度无法跟单阶段相比;级联的位置回归则会导致RCNN部分的重复计算(如两个RoI有重叠)。
另一方面,单阶段模型只有一次类别预测和位置回归,卷积运算的共享程度更高,拥有更快的速度和更小的内存占用。读者将会在接下来的文章中看到,两种类型的模型也在互相吸收彼此的优点,这也使得两者的界限更为模糊。
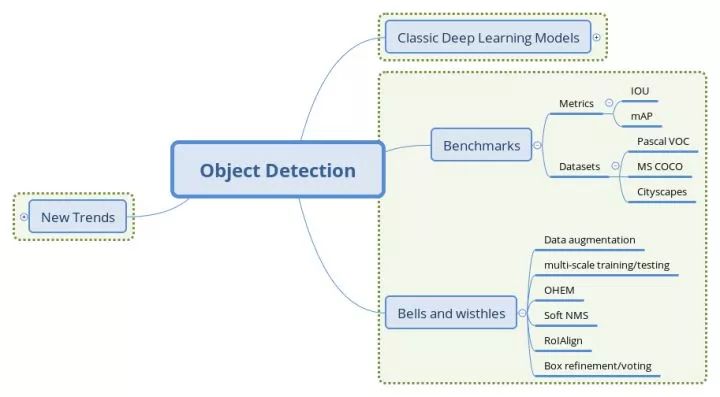
▌目标检测入门(二):模型的评测与训练技巧
文章结构
检测模型的评测指标
目标检测模型本源上可以用统计推断的框架描述,我们关注其犯第一类错误和第二类错误的概率,通常用准确率和召回率来描述。准确率描述了模型有多准,即在预测为正例的结果中,有多少是真正例;召回率则描述了模型有多全,即在为真的样本中,有多少被我们的模型预测为正例。不同的任务,对两类错误有不同的偏好,常常在某一类错误不多于一定阈值的情况下,努力减少另一类错误。在检测中,mAP(mean Average Precision)作为一个统一的指标将这两种错误兼顾考虑。
具体地,对于每张图片,检测模型输出多个预测框(常常远超真实框的个数),我们使用IoU(Intersection Over Union,交并比)来标记预测框是否为预测正确。标记完成后,随着预测框的增多,召回率总会提升,在不同的召回率水平下对准确率做平均,即得到AP,最后再对所有类别按其所占比例做平均,即得到mAP。
在较早的Pascal VOC数据集上,常采用固定的一个IoU阈值(如0.5, 0.75)来计算mAP,现阶段较为权威的MS COCO数据集上,对不同的IoU阈值(0.5-0.95,0.05为步长)分别计算AP,再综合平均,并且给出了不同大小物体分别的AP表现,对定位准确的模型给予奖励并全面地展现不同大小物体上检测算法的性能,更为科学合理。
在实践中,我们不仅关注检测模型的精度,还关注其运行的速度,常常用FPS(Frame Per Second,每秒帧率)来表示检测模型能够在指定硬件上每秒处理图片的张数。通常来讲,在单块GPU上,两阶段方法的FPS一般在个位数,而单阶段方法可以达到数十。现在检测模型运行的平台并不统一,实践中也不能部署较为昂贵的GPU进行推断。事实上,很多文章并没有严谨讨论其提出模型的速度表现(加了较多的trick以使精度达到SOTA),另外,考虑到目前移动端专用芯片的发展速度和研究进展,速度方面的指标可能较难形成统一的参考标准,需要谨慎看待文章中汇报的测试结果。
标准评测数据集
Pascal VOC(Pascal Visual Object Classes)
链接:http://host.robots.ox.ac.uk/pascal/VOC/
自2005年起每年举办一次比赛,最开始只有4类,到2007年扩充为20个类,共有两个常用的版本:2007和2012。学术界常用5k的trainval2007和16k的trainval2012作为训练集(07+12),test2007作为测试集,用10k的trainval2007+test2007和和16k的trainval2012作为训练集(07++12),test2012作为测试集,分别汇报结果。
Pascal VOC对早期检测工作起到了重要的推动作用,目前提升的空间相对有限,权威评测集的交接棒也逐渐传给了下面要介绍的COCO。
MS COCO(Common Objects in COntext-http://cocodataset.org)
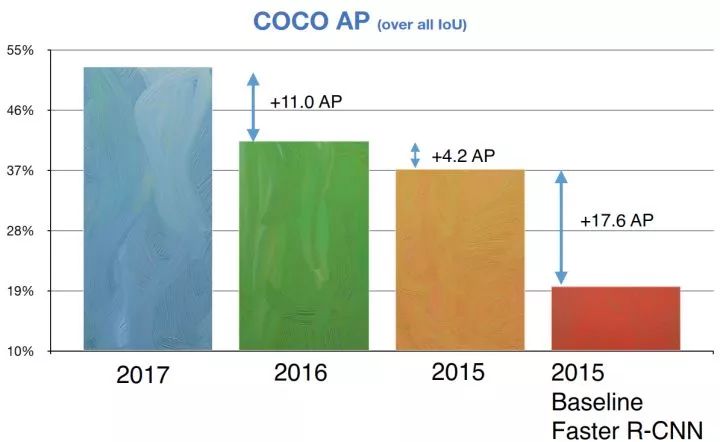
检测任务在COCO数据集上的进展
COCO数据集收集了大量包含常见物体的日常场景图片,并提供像素级的实例标注以更精确地评估检测和分割算法的效果,致力于推动场景理解的研究进展。依托这一数据集,每年举办一次比赛,现已涵盖检测、分割、关键点识别、注释等机器视觉的中心任务,是继ImageNet Chanllenge以来最有影响力的学术竞赛之一。

iconic与non-iconic图片对比
相比ImageNet,COCO更加偏好目标与其场景共同出现的图片,即non-iconic images。这样的图片能够反映视觉上的语义,更符合图像理解的任务要求。而相对的iconic images则更适合浅语义的图像分类等任务。
COCO的检测任务共含有80个类,在2014年发布的数据规模分train/val/test分别为80k/40k/40k,学术界较为通用的划分是使用train和35k的val子集作为训练集(trainval35k),使用剩余的val作为测试集(minival),同时向官方的evaluation server提交结果(test-dev)。除此之外,COCO官方也保留一部分test数据作为比赛的评测集。
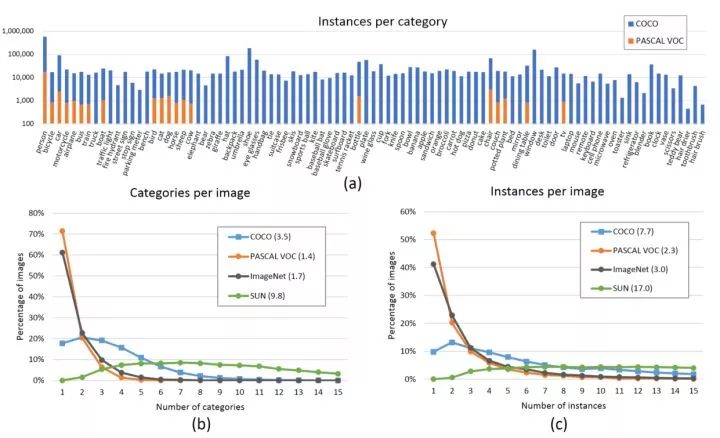
COCO数据集分布
在分布方面,COCO的每个类含有更多实例,分布也较为均衡(上图a),每张图片包含更多类和更多的实例(上图b和c,均为直方图,每张图片平均分别含3.3个类和7.7个实例),相比Pascal VOC,COCO还含有更多的小物体(下图,横轴是物体占图片的比例)。
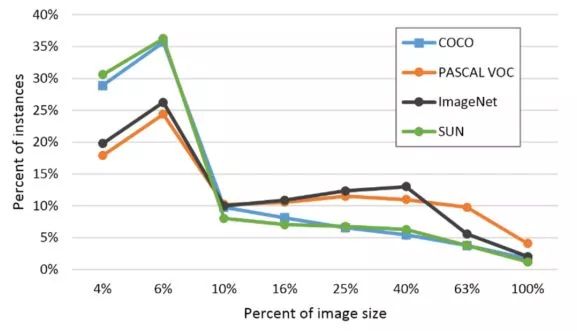
COCO数据集物体大小分布
如本文第一节所述,COCO提供的评测标准更为精细化,提供的API不仅包含了可视化、评测数据的功能,还有对模型的错误来源分析脚本,能够更清晰地展现算法的不足之处。COCO所建立的这些标准也逐渐被学术界认可,成为通用的评测标准。您可以在这里找到目前检测任务的LeaderBoard。
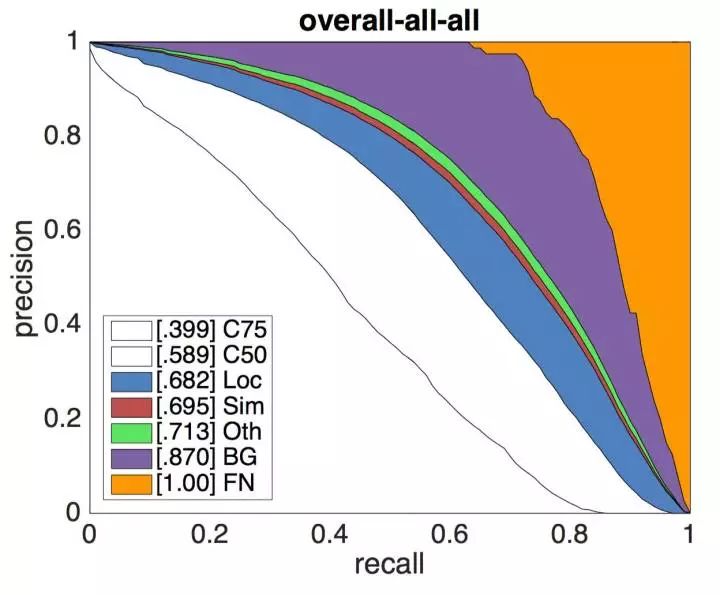
错误来源分解,详见http://cocodataset.org/#detections-eval
Cityscapes(https://www.cityscapes-dataset.com)

Cityscapes数据示例
Cityscapes数据集专注于现代城市道路场景的理解,提供了30个类的像素级标注,是自动驾驶方向较为权威的评测集。
检测模型中的Bells and wisthles
本节介绍常见的提升检测模型性能的技巧,它们常作为trick在比赛中应用。其实,这样的名称有失公允,部分工作反映了作者对检测模型有启发意义的观察,有些具有成为检测模型标准组件的潜力(如果在早期的工作中即被应用则可能成为通用做法)。读者将它们都看作学术界对解决这一问题的努力即可。对研究者,诚实地报告所引用的其他工作并添加有说服力的消融实验(ablation expriments)以支撑自己工作的原创性和贡献之处,则是值得倡导的行为。
Data augmentation 数据增强
数据增强是增加深度模型鲁棒性和泛化性能的常用手段,随机翻转、随机裁剪、添加噪声等也被引入到检测任务的训练中来,其信念是通过数据的一般性来迫使模型学习到诸如对称不变性、旋转不变性等更一般的表示。通常需要注意标注的相应变换,并且会大幅增加训练的时间。个人认为数据(监督信息)的适时传入可能是更有潜力的方向。
Multi-scale Training/Testing 多尺度训练/测试
输入图片的尺寸对检测模型的性能影响相当明显,事实上,多尺度是提升精度最明显的技巧之一。在基础网络部分常常会生成比原图小数十倍的特征图,导致小物体的特征描述不容易被检测网络捕捉。通过输入更大、更多尺寸的图片进行训练,能够在一定程度上提高检测模型对物体大小的鲁棒性,仅在测试阶段引入多尺度,也可享受大尺寸和多尺寸带来的增益。
multi-scale training/testing最早见于[1],训练时,预先定义几个固定的尺度,每个epoch随机选择一个尺度进行训练。测试时,生成几个不同尺度的feature map,对每个Region Proposal,在不同的feature map上也有不同的尺度,我们选择最接近某一固定尺寸(即检测头部的输入尺寸)的Region Proposal作为后续的输入。在[2]中,选择单一尺度的方式被Maxout(element-wise max,逐元素取最大)取代:随机选两个相邻尺度,经过Pooling后使用Maxout进行合并,如下图所示。
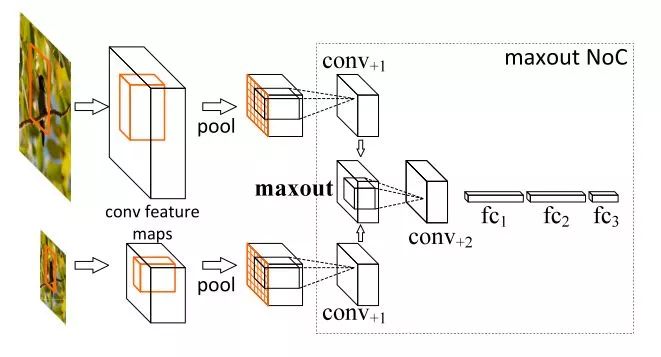
使用Maxout合并feature vector
近期的工作如FPN等已经尝试在不同尺度的特征图上进行检测,但多尺度训练/测试仍作为一种提升性能的有效技巧被应用在MS COCO等比赛中。
Global Context 全局语境
这一技巧在ResNet的工作[3]中提出,做法是把整张图片作为一个RoI,对其进行RoI Pooling并将得到的feature vector拼接于每个RoI的feature vector上,作为一种辅助信息传入之后的R-CNN子网络。目前,也有把相邻尺度上的RoI互相作为context共同传入的做法。
Box Refinement/Voting 预测框微调/投票法
微调法和投票法由工作[4]提出,前者也被称为Iterative Localization。微调法最初是在SS算法得到的Region Proposal基础上用检测头部进行多次迭代得到一系列box,在ResNet的工作中,作者将输入R-CNN子网络的Region Proposal和R-CNN子网络得到的预测框共同进行NMS(见下面小节)后处理,最后,把跟NMS筛选所得预测框的IoU超过一定阈值的预测框进行按其分数加权的平均,得到最后的预测结果。投票法可以理解为以顶尖筛选出一流,再用一流的结果进行加权投票决策。
OHEM 在线难例挖掘
OHEM(Online Hard negative Example Mining,在线难例挖掘)见于[5]。两阶段检测模型中,提出的RoI Proposal在输入R-CNN子网络前,我们有机会对正负样本(背景类和前景类)的比例进行调整。通常,背景类的RoI Proposal个数要远远多于前景类,Fast R-CNN的处理方式是随机对两种样本进行上采样和下采样,以使每一batch的正负样本比例保持在1:3,这一做法缓解了类别比例不均衡的问题,是两阶段方法相比单阶段方法具有优势的地方,也被后来的大多数工作沿用。
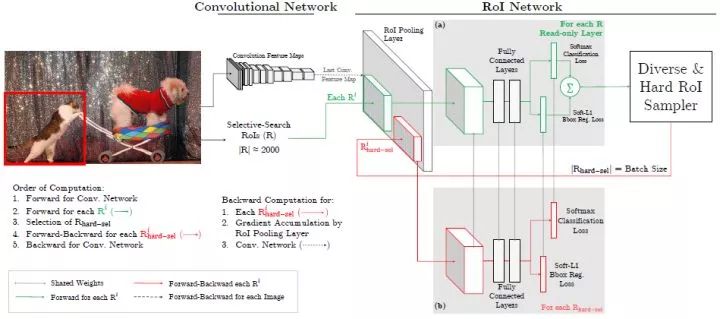
OHEM图解
但在OHEM的工作中,作者提出用R-CNN子网络对RoI Proposal预测的分数来决定每个batch选用的样本,这样,输入R-CNN子网络的RoI Proposal总为其表现不好的样本,提高了监督学习的效率。实际操作中,维护两个完全相同的R-CNN子网络,其中一个只进行前向传播来为RoI Proposal的选择提供指导,另一个则为正常的R-CNN,参与损失的计算并更新权重,并且将权重复制到前者以使两个分支权重同步。
OHEM以额外的R-CNN子网络的开销来改善RoI Proposal的质量,更有效地利用数据的监督信息,成为两阶段模型提升性能的常用部件之一。
Soft NMS 软化非极大抑制

NMS后处理图示
NMS(Non-Maximum Suppression,非极大抑制)是检测模型的标准后处理操作,用于去除重合度(IoU)较高的预测框,只保留预测分数最高的预测框作为检测输出。Soft NMS由[6]提出。在传统的NMS中,跟最高预测分数预测框重合度超出一定阈值的预测框会被直接舍弃,作者认为这样不利于相邻物体的检测。提出的改进方法是根据IoU将预测框的预测分数进行惩罚,最后再按分数过滤。配合Deformable Convnets(将在之后的文章介绍),Soft NMS在MS COCO上取得了当时最佳的表现。算法改进如下:

Soft-NMS算法改进
上图中的f即为软化函数,通常取线性或高斯函数,后者效果稍好一些。当然,在享受这一增益的同时,Soft-NMS也引入了一些超参,对不同的数据集需要试探以确定最佳配置。
RoIAlign RoI对齐
RoIAlign是Mask R-CNN([7])的工作中提出的,针对的问题是RoI在进行Pooling时有不同程度的取整,这影响了实例分割中mask损失的计算。文章采用双线性插值的方法将RoI的表示精细化,并带来了较为明显的性能提升。这一技巧也被后来的一些工作(如light-head R-CNN)沿用。
拾遗
除去上面所列的技巧外,还有一些做法也值得注意:
更好的先验(YOLOv2):使用聚类方法统计数据中box标注的大小和长宽比,以更好的设置anchor box的生成配置
更好的pre-train模型:检测模型的基础网络通常使用ImageNet(通常是ImageNet-1k)上训练好的模型进行初始化,使用更大的数据集(ImageNet-5k)预训练基础网络对精度的提升亦有帮助
超参数的调整:部分工作也发现如NMS中IoU阈值的调整(从0.3到0.5)也有利于精度的提升,但这一方面尚无最佳配置参照
最后,集成(Ensemble)作为通用的手段也被应用在比赛中。
总结
本篇文章里,我们介绍了检测模型常用的标准评测数据集和训练模型的技巧,上述内容在溯源和表述方面的不实之处也请读者评论指出。从下一篇开始,我们将介绍检测领域较新的趋势,请持续关注。
Reference
[1]: Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
[2]: Object Detection Networks on Convolutional Feature Maps
[3]: Deep Residual Learning for Image Classification
[4]: Object Detection via a Multi-region & Semantic Segmentatio-aware CNN Model
[5]: Training Region-based Object Detectors with Online Hard Example Mining
[6]: Improving Object Detection With One Line of Code
[7]: Mask R-CNN
目标检测入门,看这篇就够了(下)

作者 | 李家丞( 同济大学数学系本科在读,现格灵深瞳算法部实习生)
近年来,深度学习模型逐渐取代传统机器视觉方法而成为目标检测领域的主流算法,本系列文章将回顾早期的经典工作,并对较新的趋势做一个全景式的介绍,帮助读者对这一领域建立基本的认识
导言:目标检测的任务表述
如何从图像中解析出可供计算机理解的信息,是机器视觉的中心问题。深度学习模型由于其强大的表示能力,加之数据量的积累和计算力的进步,成为机器视觉的热点研究方向。
那么,如何理解一张图片?根据后续任务的需要,有三个主要的层次。
图像理解的三个层次
一是分类(Classification),即是将图像结构化为某一类别的信息,用事先确定好的类别(string)或实例ID来描述图片。这一任务是最简单、最基础的图像理解任务,也是深度学习模型最先取得突破和实现大规模应用的任务。其中,ImageNet是最权威的评测集,每年的ILSVRC催生了大量的优秀深度网络结构,为其他任务提供了基础。在应用领域,人脸、场景的识别等都可以归为分类任务。
二是检测(Detection)。分类任务关心整体,给出的是整张图片的内容描述,而检测则关注特定的物体目标,要求同时获得这一目标的类别信息和位置信息。相比分类,检测给出的是对图片前景和背景的理解,我们需要从背景中分离出感兴趣的目标,并确定这一目标的描述(类别和位置),因而,检测模型的输出是一个列表,列表的每一项使用一个数据组给出检出目标的类别和位置(常用矩形检测框的坐标表示)。
三是分割(Segmentation)。分割包括语义分割(semantic segmentation)和实例分割(instance segmentation),前者是对前背景分离的拓展,要求分离开具有不同语义的图像部分,而后者是检测任务的拓展,要求描述出目标的轮廓(相比检测框更为精细)。分割是对图像的像素级描述,它赋予每个像素类别(实例)意义,适用于理解要求较高的场景,如无人驾驶中对道路和非道路的分割。
本系列文章关注的领域是目标检测,即图像理解的中层次。
▌目标检测入门(三):基础网络演进、分类与定位的权衡
从此篇开始,我们对近几年检测领域的工作提供一个概览,并试图从中归纳出一些趋势。由于篇幅和视野所限,文章不会求全,相对注重思路的演进,淡化实验结果的报告。事实上,我们并没有看到这一任务上的"The Best Paper"和"The Final Paper",现阶段的工作远远没有到解决这一问题的程度,深度学习模型也仍然是非常年轻的研究领域。
实验结果方面,笔者维护了一个检测模型进展追踪项目:Obj_Det_Progress_Tracker(https://github.com/ddlee96/Obj_Det_progress_tracker),收集了论文汇报的在VOC和COCO上的精度进展,可供参考。
文章结构
本篇关注基础网络架构的演进和处理分类、定位这一矛盾问题上的进展。
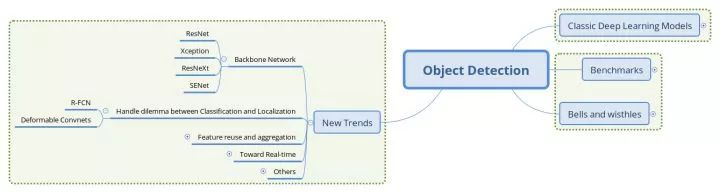
基础网络结构的演进
基础网络(Backbone network)作为特征提取器,对检测模型的性能有着至关重要的影响。在分类任务的权威评测集ImageNet上,基于卷积网络的方法已经取得超越人类水平的进步,并也促使ImageNet完成了她的历史使命。这也是机器视觉领域的整体进步,优秀的特征、深刻的解释都为其他任务的应用提供了良好的基础。在本节中,我们选取了几个在检测任务上成功应用的基础网络做一些介绍。
卷积网络结构演进的趋势
笔者认为,卷积网络已经有如下几个经典的设计范式:
Repeat. 由AlexNet和VGG等开拓,被之后几乎所有的网络采用。即堆叠相同的拓扑结构,整个网络成为模块化的结构。
Multi-path. 由Inception系列发扬,将前一层的输入分割到不同的路径上进行变换,最后拼接结果。
Skip-connection. 最初出现于Highway Network,由ResNet发扬并成为标配。即建立浅层信息与深层信息的传递通道,改变原有的单一线性结构。
以这些范式为脉络整理卷积网络的演进历程,可以归纳出下面的图景:
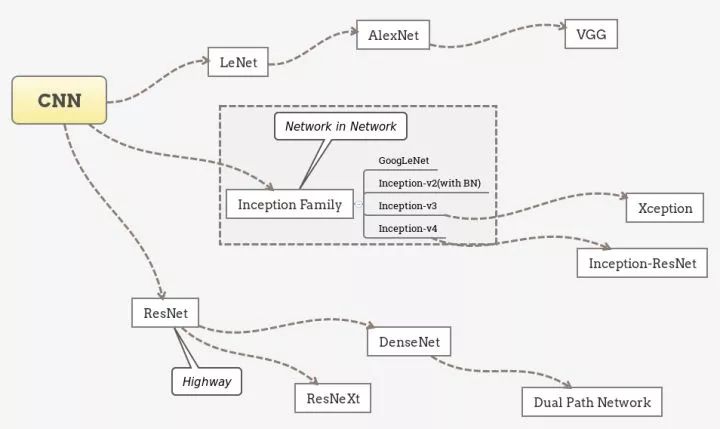
CNN的经典设计范式
需要说明的是,上图并不能概括完全近年来卷积网络的进步,各分支之间也有很多相互借鉴和共通的特征,而致力于精简网络结构的工作如SqueezeNet等则没有出现。除了上面归纳的三个范式,卷积网络结构方面另一个重要的潮流是深度可分离卷积(Depth-wise seperable convolution)的应用。下面我们选择几个在检测任务上成功应用的基础网络结构进行介绍。
ResNet: 残差学习
Deep Residual Learning for Image Recognition
https://arxiv.org/abs/1512.03385
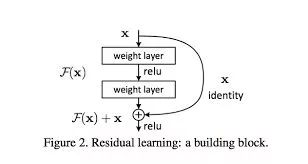
残差单元将原函数分解为残差
作者将网络的训练解释为对某一复杂函数的拟合,通过添加跳跃连接,变对这一函数的拟合为每层对某一残差的拟合(有点Boosting的意思),引入的恒等项也让BP得到的梯度更为稳定。
残差网络以skip-connection的设计较为成功地缓解了深层网络难以收敛的问题,将网络的深度提高了一个数量级,也带动了一系列对残差网络的解释研究和衍生网络的提出。
在检测领域,VGG作为特征提取器的地位也逐渐被ResNet系列网络替代,文章中以ResNet作为基础网络的Faster R-CNN也常作为后续工作的基线进行比较。
Xception:可分离卷积的大面积应用
Xception: Deep Learning with Depthwise Separable Convolutions
https://arxiv.org/abs/1610.02357
Xception网络可以看做对Inception系列网络的推进,也是深度可分离卷积的成功应用。
文章指出,Inception单元背后的假设是跨Channel和跨空间的相关性可以充分解耦,类似的还有长度和高度方向上的卷积结构(在Inception-v3里的3×3卷积被1×3和3×1卷积替代)。
进一步的,Xception基于更强的假设:跨channel和跨空间的相关性完全解耦。这也是深度可分离卷积所建模的理念。
一个简化的Inception单元:
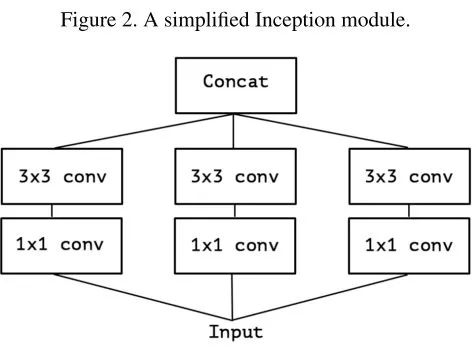
简化的Inception单元,去掉了Pooling分支
等价于:
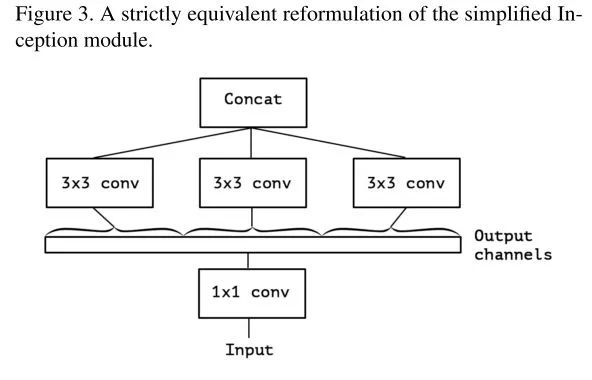
等价的简化Inception单元,将1x1卷积合并
将channel的group推向极端,即每个channel都由独立的3×3卷积处理:
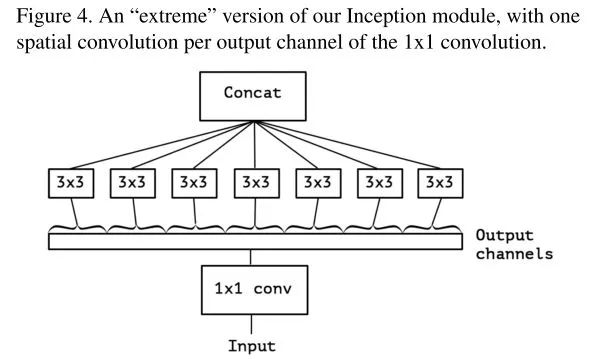
把分组的粒度降为1
这样就得到了深度可分离卷积。
Xception最终的网络结构如下,简单讲是线性堆叠的Depthwise Separable卷积,并附加了Skip-connection。
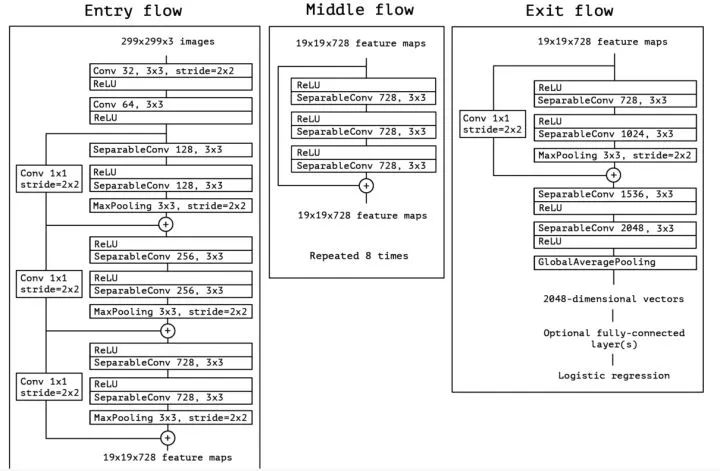
Xceptiong的网络结构
在MS COCO Chanllege 2017中,MSRA团队以对齐版本的Xception为基础网络取得前列的成绩,一定程度上说明了这一网络提取特征的能力;另一方面,Xception的一个改编版本也被Light-head R-CNN的工作(将在下一篇的实时性部分介绍)应用,以两阶段的方式取得了精度和速度都超越SSD等单阶段检测器的表现。
ResNeXt:新的维度
Aggregated Residual Transformations for Deep Neural Networks
https://arxiv.org/abs/1611.05431
本文提出了深度网络的新维度,除了深度、宽度(Channel数)外,作者将在某一层并行transform的路径数提取为第三维度,称为"cardinality"。跟Inception单元不同的是,这些并行路径均共享同一拓扑结构,而非精心设计的卷积核并联。除了并行相同的路径外,也添加了层与层间的shortcut connection。
相比Inception-ResNet,ResNeXt相当于将其Inception Module的每条路径规范化了,并将规范后的路径数目作为新的超参数。
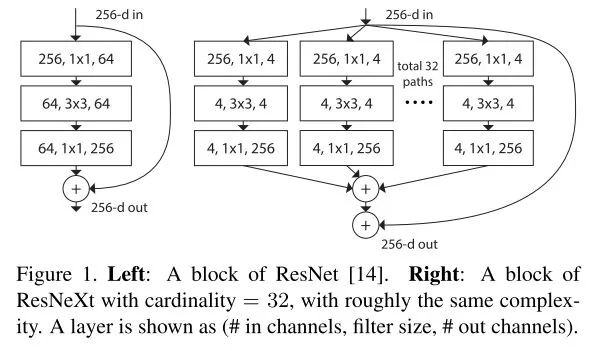
ResNeXt的基本单元
上图中,路径被扩展为多条,而每条路径的宽度(channel数)也变窄了(64->4)。
在近期Facebook开源的Detectron框架中,ResNeXt作为Mask R-CNN的基础网络也取得了非常高的精度。
SENet:卷积网络的Attention组件
Squeeze and Excitation Network
https://arxiv.org/abs/1709.01507
SENet是最后一届ImageNet Challenge的夺冠架构,中心思想是添加旁路为channel之间的相关性进行建模,可以认为是channel维度的attention。
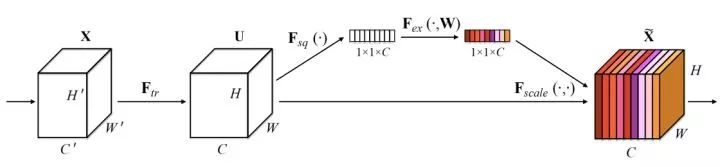
Squeeze和Excitation分支
SENet通过'特征重标定'(Feature Recalibration)来完成channel层面的注意力机制。具体地,先通过Squeeze操作将特征的空间性压缩掉,仅保留channel维度,再通过Excitation操作为每个特征通道生成一个权重,用于显式地建模channel之间的相关性,最后通过Reweight操作将权重加权到原来的channel上,即构成不同channel间重标定。
SENet可以作为网络中模块间的额外连接附属到原有的经典结构上,其Squeeze操作在压缩信息的同时也降低了这一附属连接的开销。
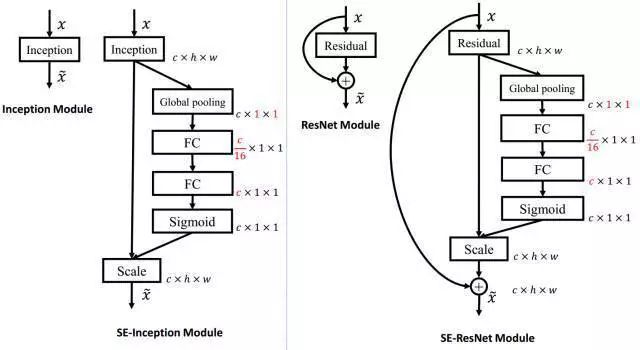
SE作为额外部件添加在经典结构上
经SENet改进的ResNet被UCenter团队应用在MS COCO Chanllenge 2017上,也取得了不错的效果。
NASNet:网络结构搜索
Learning Transferable Architectures for Scalable Image Recognition
https://arxiv.org/abs/1707.07012
NAS(Neural Architecture Searh,神经网络结构搜索)的框架最早出现于作者的另一项工作Neural Architecture Search with Reinforcement Learning,其核心思想是用一个RNN学习定义网络结构的超参,通过强化学习的框架来更新这一RNN来得到更好表现的网络结构。
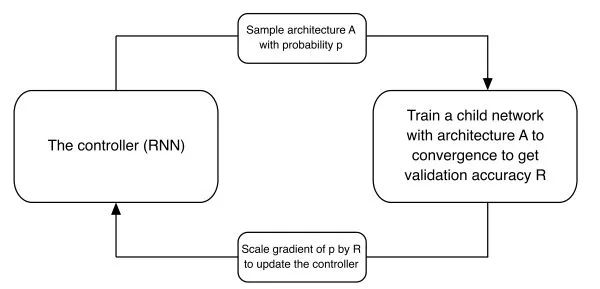
NAS的结构
在本文中,作者参考本节最初提到的"Repeat"范式,认为在小数据集上搜索到的结构单元具有移植性和扩展性,将这个结构单元通过堆叠得到的大网络能够在较大数据集上取得较好的表现。这就构成了文章的基本思路:将网络搜索局限在微观的局部结构上,以相对原工作较小的开销(实际开销仍然巨大)得到可供扩展的网络单元,再由这些单元作为基本部件填入人工设计的"元结构"。
微观层面,作者仍选择用RNN作为Controller,挑选跳跃连接、最大池化、空洞卷积、深度可分离卷积等等操作构成基本搜索空间,以逐元素相加(element-wise addition)和拼接(concatenation)作为合并操作,并重复一定的构建次数来搜索此基本单元。
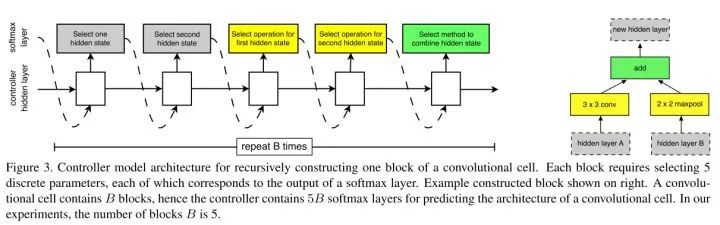
RNN作为Controller的微观结构搜索,右为示例结构
宏观层面,将基本单元分为Normal Cell(不改变feature map大小)和Reduction Cell(使feature map的spatial维度减半,即stride=2),交替堆叠一定数量的Normal Cell和Reduction Cell形成下面的元结构。
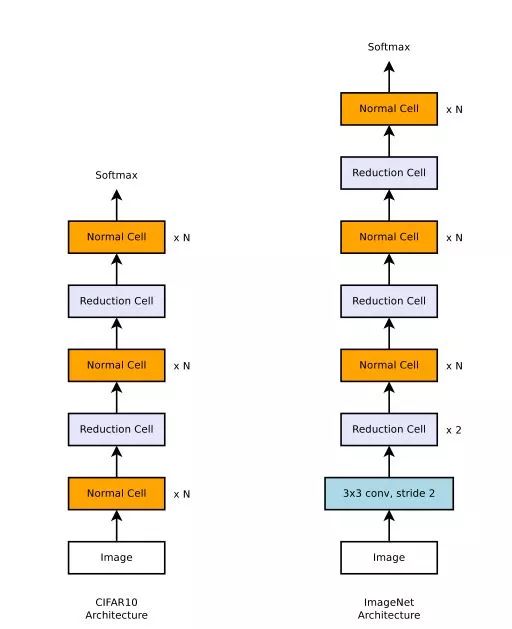
NASNet在不同数据集上的元结构,ImageNet的图片具有更多的像素数,需要更多的Reduction单元
NASNet采取了自动搜索的方式去设计网络的结构,人工的部分迁移到对搜索空间的构建和评测指标的设立上,是一种"元学习"的策略。应用在检测领域,NASNet作为基础框架的Faster R-CNN取得了SOTA的表现,也支撑了这一搜索得到结构的泛化性能。在最近的工作中,作者团队又设计了ENAS降低搜索的空间和时间开销,继续推动着这一方向的研究。
分类与定位问题的权衡
从R-CNN开始,检测模型常采用分类任务上表现最好的卷积网络作为基础网络提取特征,在其基础上添加额外的头部结构来实现检测功能。然而,分类和检测所面向的场景不尽相同:分类常常关注具有整体语义的图像(第二篇中介绍COCO数据集中提到的iconic image),而检测则需要区分前景和背景(non-iconic image)。
分类网络中的Pooling层操作常常会引入平移不变性等使得整体语义的理解更加鲁棒,而在检测任务中我们则需要位置敏感的模型来保证预测位置的精确性,这就产生了分类和定位两个任务间的矛盾。
R-FCN
R-FCN: Object Detection via Region-based Fully Convolutinal Networks
https://arxiv.org/abs/1605.06409
文章指出了检测任务之前的框架存在不自然的设计,即全卷积的特征提取部分+全连接的分类器,而表现最好的图像分类器都是全卷积的结构(ResNet等)。这篇文章提出采用"位置敏感分数图(Position Sensitive Score Map)"的方法来使检测网络保持全卷积结构的同时又拥有位置感知能力。
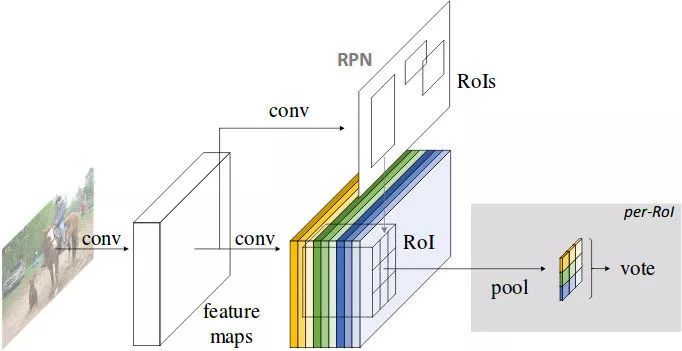
R-FCN中位置敏感分数图
位置敏感分数图的生成有两个重要操作,一是生成更"厚"的feature map,二是在RoI Pooling时选择性地输入feature map。
Faster R-CNN中,经过RPN得到RoI,转化成分类任务,还加入了一定量的卷积操作(ResNet中的conv5部分),而这一部分卷积操作是不能共享的。R-FCN则着眼于全卷积结构,利用卷积操作在Channel这一维度上的自由性,赋予其位置敏感的意义。下面是具体的操作:
在全卷积网络的最后一层,生成
个Channel的Feature map,其中 C为类别数,
代表k*k网格,用于分别检测目标物体的k*k个部分。即是用不同channel的feature map代表物体的不同局部(如左上部分,右下部分)。
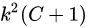
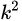
将RPN网络得到的Proposal映射到上一步得到的feature map(厚度为
)后,相应的,将RoI等分为k*k个bin,对第(i,j)个bin,仅考虑对应(i,j)位置的(C+1)个feature map,进行如下计算:其中(x0,y0)是这个RoI的锚点,得到的即是(i,j)号bin对 类别的相应分数。
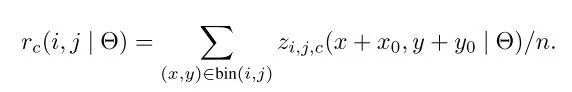
经过上一步,每个RoI得到的结果是
大小的分数张量, K*K编码着物体的局部分数信息,进行vote(平均)后得到(C+1)维的分数向量,再接入softmax得到每一类的概率。
上面第二步操作中"仅选取第(i,j)号feature map"是位置信息产生意义的关键。这样设计的网络结构,所有可学习的参数都分布在可共享的卷积层,因而在训练和测试性能上均有提升。
小结
R-FCN是对Faster R-CNN结构上的改进,部分地解决了位置不变性和位置敏感性的矛盾。通过最大化地共享卷积参数,使得在精度相当的情况下训练和测试效率都有了很大的提升。
Deformable Convolution Networks
Deformable Convolution Networks
https://arxiv.org/abs/1703.06211
本篇文章则提出在卷积和RoI Pooling两个层添加旁路显式学习偏置,来建模物体形状的可变性。这样的设计使得在保持目标全局上位置敏感的同时,对目标局部的建模添加灵活性。
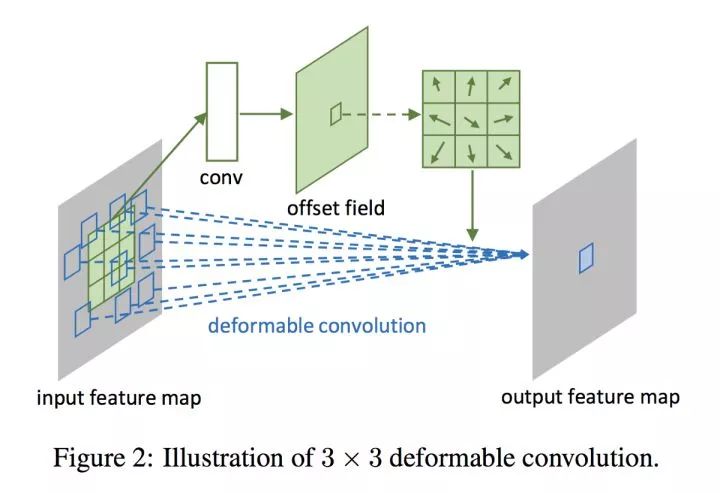
可变形卷积的旁支
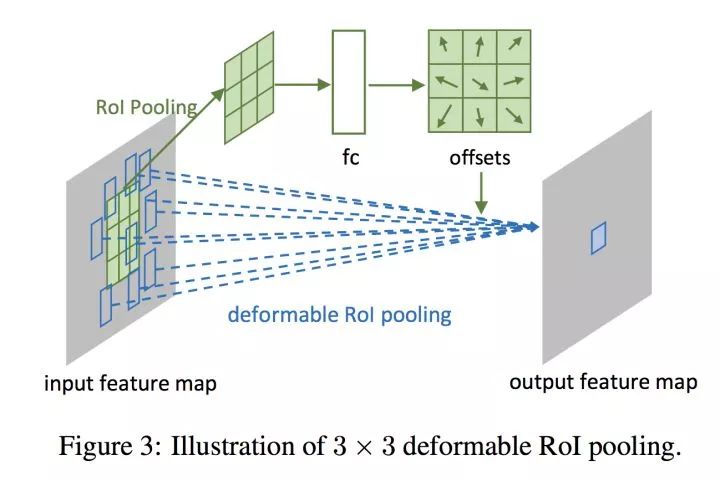
RoI Pooling的旁支
如上两图所示,通过在卷积部分添加旁路,显式地用一部分张量表示卷积核在图片不同部分的偏移情况,再添加到原有的卷积操作上,使卷积具有灵活性的特征,提取不同物体的特征时,其形状可变。而在RoI Pooling部分,旁路的添加则赋予采样块可活动的特性,更加灵活地匹配不同物体的形状。
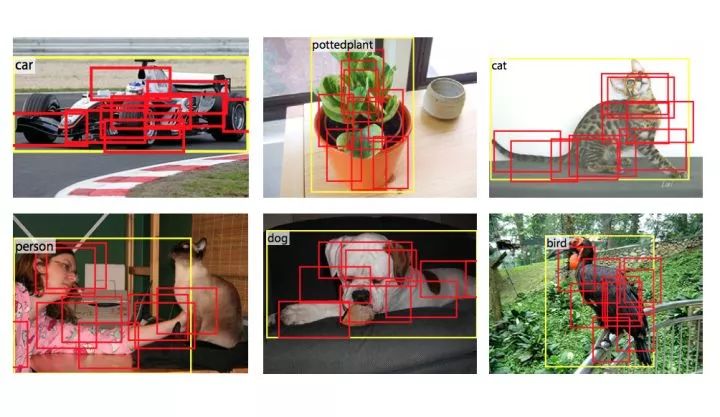 可变形卷积和RoIPooling的示例
可变形卷积和RoIPooling的示例
在MS COCO Chanllege 2017上,MSRA团队的结果向我们展示了可变形卷积在提升检测模型性能上的有效性:
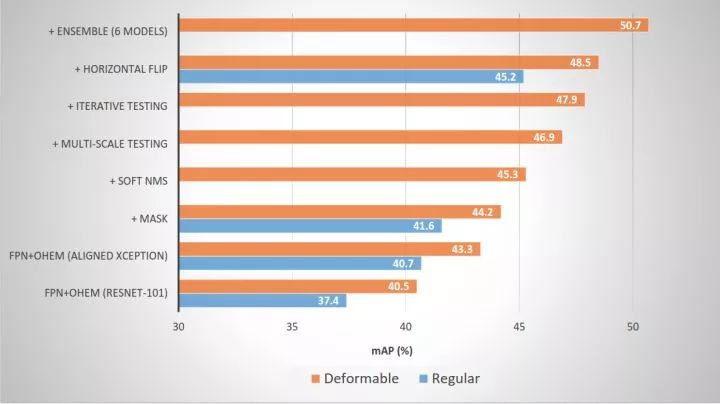
可变形卷积带来的增益
总结
本篇中,我们概述了检测领域基础网络的演进和处理分类定位这一矛盾问题上的进展,基础网络提供更具有语义级区分性的特征,为图像提供更有意义的编码,而分析分类和定位这一对矛盾,则提供给我们对这一任务另一种理解和分治的角度。在下一篇中,我们将关注基础网络提取的特征如何更有效地在检测模型的头部网络中得到利用,以及面向实时性检测的一些进展。
▌目标检测入门(四):特征复用、实时性
文章结构
本文的第一部分关注检测模型的头部部分。对与每张图片,深度网络其实是通过级联的映射获得了在某一流形上的一个表征,这个表征相比原图片更有计算机视角下的语义性。例如,使用Softmax作为损失函数的分类网络,最后一层获得的张量常常展现出成簇的分布。
深度网络因分布式表示带来的指数级增益,拥有远超其他机器学习模型的表示能力,近年来,有不少致力于对深度网络习得特征进行可视化的工作,为研究者提供了部分有直观意义的感知,如浅层学习线条纹理,深层学习物体轮廓。然而,现阶段的深度模型仍然是一个灰盒,缺乏有效的概念去描述网络容量、特征的好坏、表达能力等等被研究者常常提到但又给不出精确定义的指代。
本篇的第一节将介绍通过头部网络结构的设计来更有效利用基础网络所提供特征的工作,帮助读者进一步理解检测任务的难点和研究者的解决思路。
第二部分则关注面向实时性检测的工作,这也是检测任务在应用上的目标。如本系列文章第二篇所述,实时性这一要求并没有通用的评价标准,应用领域也涉及到更多网络的压缩、加速和工程上的优化乃至硬件层面的工作等,则不在本文的介绍范围。
特征复用与整合
FPN
Feature Pyramid Networks for Object Detection
https://arxiv.org/abs/1612.03144
对图片信息的理解常常关系到对位置和规模上不变性的建模。在较为成功的图片分类模型中,Max-Pooling这一操作建模了位置上的不变性:从局部中挑选最大的响应,这一响应在局部的位置信息就被忽略掉了。而在规模不变性的方向上,添加不同大小感受野的卷积核(VGG),用小卷积核堆叠感受较大的范围(GoogLeNet),自动选择感受野的大小(Inception)等结构也展现了其合理的一面。
回到检测任务,与分类任务不同的是,检测所面临的物体规模问题是跨类别的、处于同一语义场景中的。
一个直观的思路是用不同大小的图片去生成相应大小的feature map,但这样带来巨大的参数,使本来就只能跑个位数图片的显存更加不够用。另一个思路是直接使用不同深度的卷积层生成的feature map,但较浅层的feature map上包含的低等级特征又会干扰分类的精度。
本文提出的方法是在高等级feature map上将特征向下回传,反向构建特征金字塔。
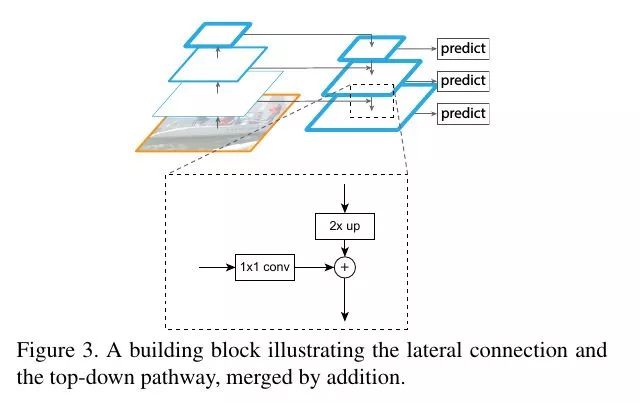
FPN结构
从图片开始,照常进行级联式的特征提取,再添加一条回传路径:从最高级的feature map开始,向下进行最近邻上采样得到与低等级的feature map相同大小的回传feature map,再进行逐元素相加(lateral connection),构成这一深度上的特征。
这种操作的信念是,低等级的feature map包含更多的位置信息,高等级的feature map则包含更好的分类信息,将这两者结合,力图达到检测任务的位置分类双要求。
特征金字塔本是很自然的想法,但如何构建金字塔同时平衡检测任务的定位和分类双目标,又能保证显存的有效利用,是本文做的比较好的地方。如今,FPN也几乎成为特征提取网络的标配,更说明了这种组合方式的有效性。
TDM
Beyond Skip Connections: Top-down Modulation for Object Detection
https://arxiv.org/abs/1612.06851
本文跟FPN是同一时期的工作,其结构也较为相似。作者认为低层级特征对小物体的检测至关重要,但对低层级特征的选择要依靠高层及特征提供的context信息,于是设计TDM(Top-Down Modulation)结构来将这两种信息结合起来处理。
TDM整体结构
可以看到,TDM的结构跟FPN相当类似,但也有如下显著的不同:
T模块和L模块都是可供替换的子网络单元,可以是Residual或者Inception单元,而在FPN中,二者分别是最近邻上采样(Neareast UpSample)和逐元素相加(Element-wise Addition)。
FPN在每个层级得到的feature map都进行RoI Proposal和RoI Pooling,而TDM只在自上而下传播后的最大feature map上接入检测头部。
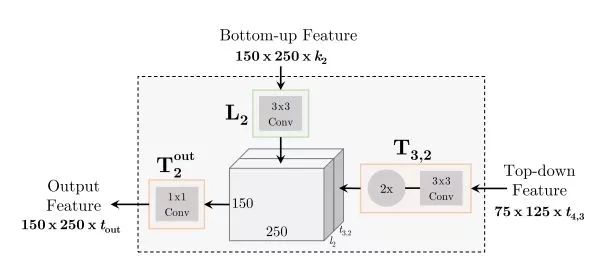
TDM中的T模块和L模块
TDM的设计相比FPN拥有更多可学习的参数和灵活性,文章的实验显示,TDM结构对小物体检测精度的提升帮助明显。而且,TDM是对检测头部的改进,也有推广到单阶段模型的潜力。
DSSD
Deconvolutional Single Shot Multibox Detector
https://arxiv.org/abs/1701.06659
本文是利用反卷积操作对SSD的改进。
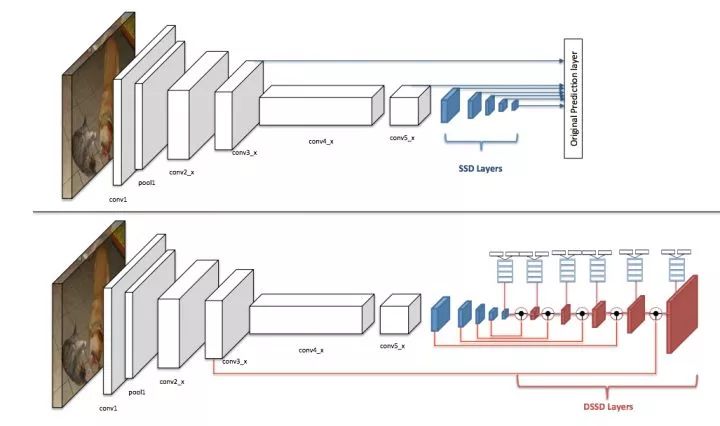
DSSD的网络结构
在原版SSD中,检测头部不仅从基础网络提取特征,还添加了额外的卷积层,而本文则在这些额外卷积层后再添加可学习的反卷积层,并将feature map的尺度扩展为原有尺寸,把两个方向上具有相同尺度的feature map叠加后再进行检测,这种设计使检测头部同时利用不同尺度上的低级特征和高级特征。跟FPN不同的是,反传的特征通过反卷积得到而非简单的最近邻上采样。
同时,在反卷积部分添加了额外的卷积层提供"缓冲",以免反卷积分支影响网络整体的收敛性。另外,文章也通过加入跳跃连接改进了检测头部,使得头部结构相比原版SSD更加复杂。
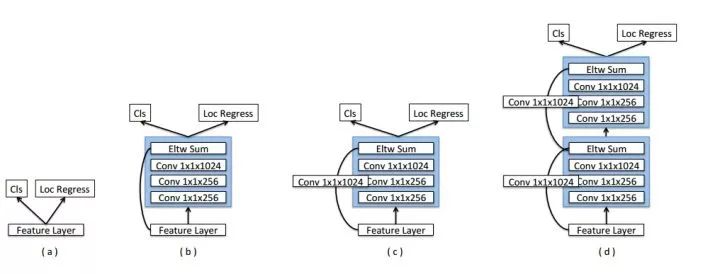
RON
RON: Reverse Connection with Objectness Prior Networksfor Object Detection
https://arxiv.org/abs/1707.01691
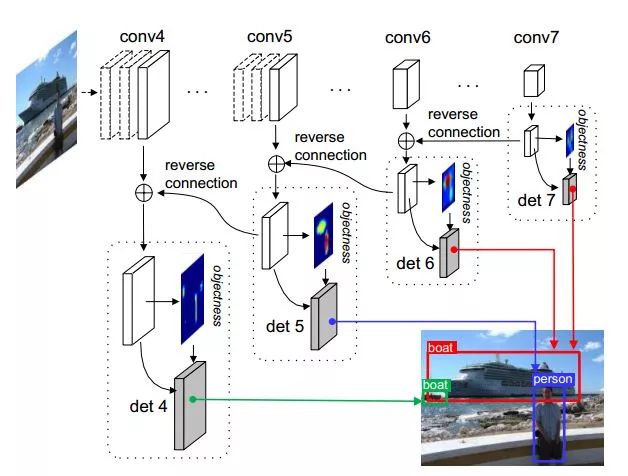
RON结构
文章关注两个问题:1)多尺度目标检测,2)正负样本比例失衡的问题。
对于前者,文章将相邻的feature map通过reverse connection相连,并在每个feature map上都进行检测,最后再整合过滤。对于后者,类似RPN,对每个anchor box生成一个Objectness priori,作为一个指标来过滤过多的box(但不对box进行调整,RPN对box进行调整,作者指出这会造成重复计算)。文章的实验显示RON在较低的分辨率下取得了超过SSD的表现。
FSSD
Feature Fusion Single Shot Multibox Detector
https://arxiv.org/abs/1712.00960
FSSD提出了另一种对不同层级特征进行融合的方式,从基础网络不同层级得到feature map后,利用采样操作将它们在spatial方向上规整化,再拼接到一起,并通过BN层以使不同层级特征的激活值数量级一致。最后,拼接后的feature map经过一系列的卷积操作,产生不同大小的融合feature map传入检测头部的预测网络。
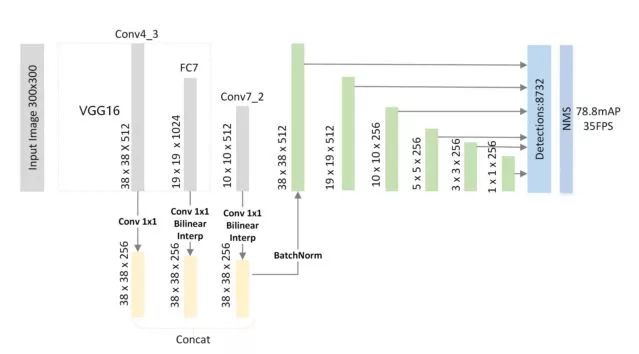
FSSD的特征融合方式
文章指出,特征融合的初衷还是同时利用高层级feature map提供的语义信息和低层级feature map的位置信息,而像FPN中的逐元素相加操作进行融合的方式要求不同层级的feature map具有完全一致的大小,本文则采用拼接的方式,不受channel数的限制。
RefineDet
Single-Shot Refinement Neural Network for Object Detection
https://arxiv.org/abs/1711.06897
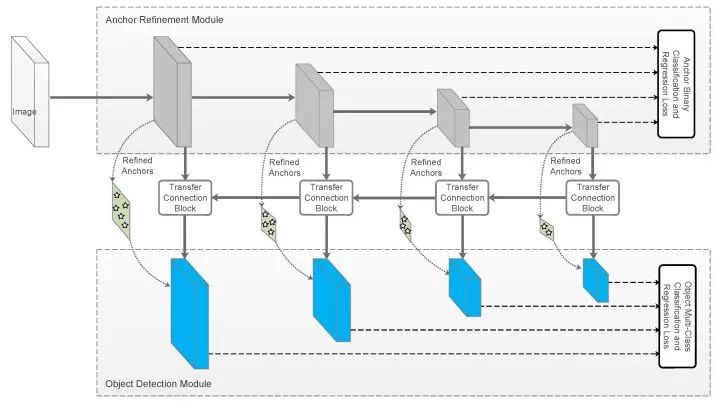
RefineDet的ARM和ODM
本文是单阶段的模型,但思路上却是两阶段的。文章指出两阶段方法精度有优势的原因有三点:
1)两阶段的设计使之有空间来用采样策略处理类别不均衡的问题;
2)级联的方式进行box回归;
3)两阶段的特征描述。
文章提出两个模块来在一阶段检测器中引入两阶段设计的优势:Anchor Refinement Module(ARM)和Object Detection Module(ODM)。前者用于识别并过滤背景类anchor来降低分类器的负担,并且调整anchor位置以更好的向分类器输入,后者用于多分类和box的进一步回归。
Single-shot的体现在上面两个模块通过Transfer Connection Block共用特征。除此之外,Transfer Connection Block还将特征图反传,构成类似FPN的效果。两个模块建立联合的损失使网络能够端到端训练。
实验结果显示RefineNet的效果还是不错的,速度跟YOLOv2相当,精度上更有优势。之后的Ablation experiments也分别支撑了负样本过滤、级联box回归和Transfer Connection Block的作用。可以说这篇文章的工作让两阶段和一阶段检测器的界限更加模糊了。
面向实时性的工作
Light Head R-CNN
Light-Head R-CNN: In Defense of Two-Stage Object Detector
https://arxiv.org/abs/1711.07264
文章指出两阶段检测器通常在生成Proposal后进行分类的"头"(head)部分进行密集的计算,如ResNet为基础网络的Faster-RCNN将整个stage5(或两个FC)放在RCNN部分, R-FCN要生成一个具有随类别数线性增长的channel数的Score map,这些密集计算正是两阶段方法在精度上领先而在推断速度上难以满足实时要求的原因。
针对这两种元结构(Faster-RCNN和RFCN),文章提出了"头"轻量化方法,试图在保持精度的同时又能减少冗余的计算量,从而实现精度和速度的Trade-off。
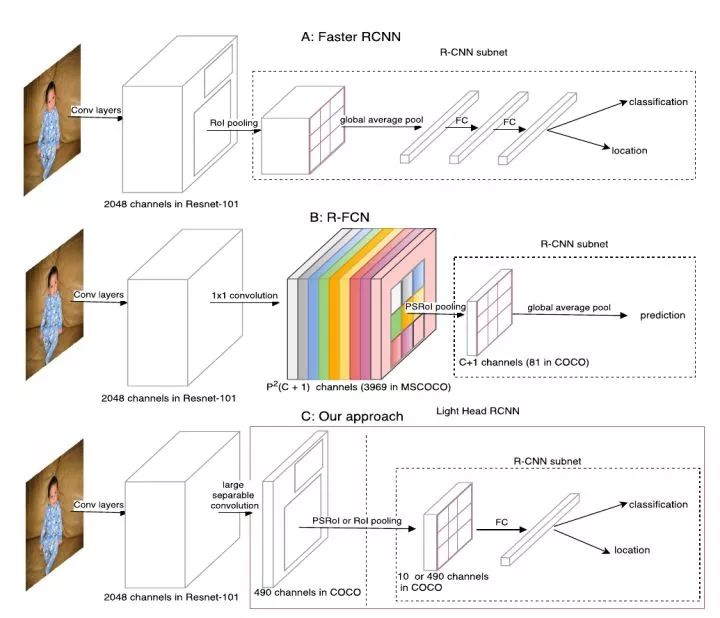
Light-head R-CNN与Faster R-CNN, R-FCN的对比
如上图,虚线框出的部分是三种结构的R-CNN子网络(在每个RoI上进行的计算),light-head R-CNN中,在生成Score map前,ResNet的stage5中卷积被替换为深度可分离卷积,产生的Score map也减少至10×p×p(相比原先的类别数×p×p,p为网格划分粒度,R-FCN中取7)。
一个可能的解释是,"瘦"(channel数较少)的score map使用于分类的特征信息更加紧凑,原先较"厚"的score map在经过PSROIPooling的操作时,大部分信息并没有提取(只提取了特定类和特定位置的信息,与这一信息处在同一score map上的其他数据都被忽略了)。
进一步地,位置敏感的思路将位置性在channel上表达出来,同时隐含地使用了更类别数相同长度的向量表达了分类性(这一长度相同带来的好处即是RCNN子网络可以免去参数)。
light-head在这里的改进则是把这一个隐藏的嵌入空间压缩到较小的值,而在RCNN子网络中加入FC层再使这个空间扩展到类别数的规模,相当于是把计算量分担到了RCNN子网络中。
粗看来,light-head将原来RFCN的score map的职责两步化了:thin score map主攻位置信息,RCNN子网络中的FC主攻分类信息。另外,global average pool的操作被去掉,用于保持精度。
YOLOv2
YOLO9000: Better, Faster, Stronger
单阶段检测模型的先驱工作YOLO迎来了全面的更新:
在卷积层添加BN,舍弃Dropout
更大尺寸的输入
使用Anchor Boxes,并在头部运用卷积替代全连接层
使用聚类方法得到更好的先验,用于生成Anchor Boxes
参考Fast R-CNN的方法对位置坐标进行log/exp变换使坐标回归的损失保持在合适的数量级
passthrough层:类似ResNet的skip-connection,将不同尺寸的feature map拼接到一起
多尺度训练
更高效的网络Darknet-19,类似VGG的网络,在ImageNet上以较少的参数量达到跟当前最佳相当的精度
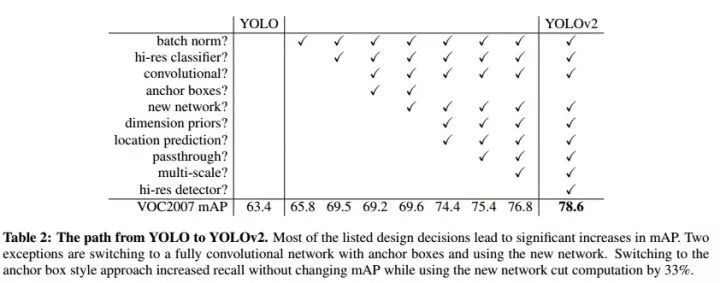
YOLOv2的改进
此次改进后,YOLOv2吸收了很多工作的优点,达到跟SSD相当的精度和更快的推断速度。
SSDLite(MobileNets V2)
SSDLite是在介绍MobileNets V2的论文Inverted Residuals and Linear Bottlenecks: Mobile Networks for Classification, Detection and Segmentation(https://arxiv.org/abs/1801.04381)中提出的。
MobileNets是一系列大面积应用深度可分离卷积的网络结构,试图以较小的参数量来达到跟大型网络相当的精度,以便能够在移动端部署。在本文中,作者提出了对MobileNets的改进版本,通过移动跳跃连接的位置并去掉某些ReLU层来实现更好的参数利用。可参考这个问题了解更多关于这一改进的解释。
在检测方面,SSDLite的改进之处在于将SSD的检测头部中的卷积运算替换为深度可分离卷积,降低了头部计算的参数量。另外,这项工作首次给出了检测模型在移动设备CPU上单核运行的速度,提供了现在移动终端执行类似任务性能的一个参考。
总结
从基础网络的不同层级提取习得的feature map并通过一定的连接将它们整合,是近年来检测模型的重要趋势。这些针对检测头部网络的改进也越来越多地体现着研究者们对检测任务要求的表述和探索。另一方面,面向实时性的改进则继续推动这检测任务在应用领域的发展。
▌目标检测入门(五):目标检测新趋势拾遗
文章结构
本篇为读者展现检测领域多样性的一个视角,跟其他任务联合,有YOLO9000、Mask R-CNN;改进损失函数,有Focal Loss;利用GAN提升检测模型的鲁棒性,有A-Fast-RCNN;建模目标关联,有Relation Moduel;还有mimicking思路、引入大batch训练的MegDet和从零训练的DSOD,再加上未收录的Cascade R-CNN、SNIP等,多样性的思路为检测任务的解决上注入着前所未有的活力,也推动着理解视觉这一终极目标的进步。
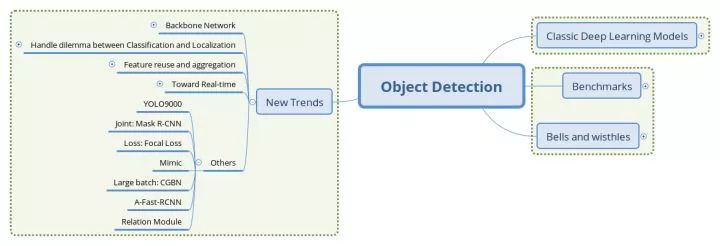
工作拾遗
YOLO9000
YOLO9000: Better, Faster, Stronger
这篇文章里,YOLO的作者不仅提出YOLOv2,大幅改进了原版YOLO,而且介绍了一种新的联合训练方式:同时训练分类任务和检测任务,使得检测模型能够泛化到检测训练集之外的目标类上。
YOLO9000使用了ImageNet和COCO数据集联合训练,在合并两者的标签时,根据WordNet的继承关系构建了了树状的类别预测图:
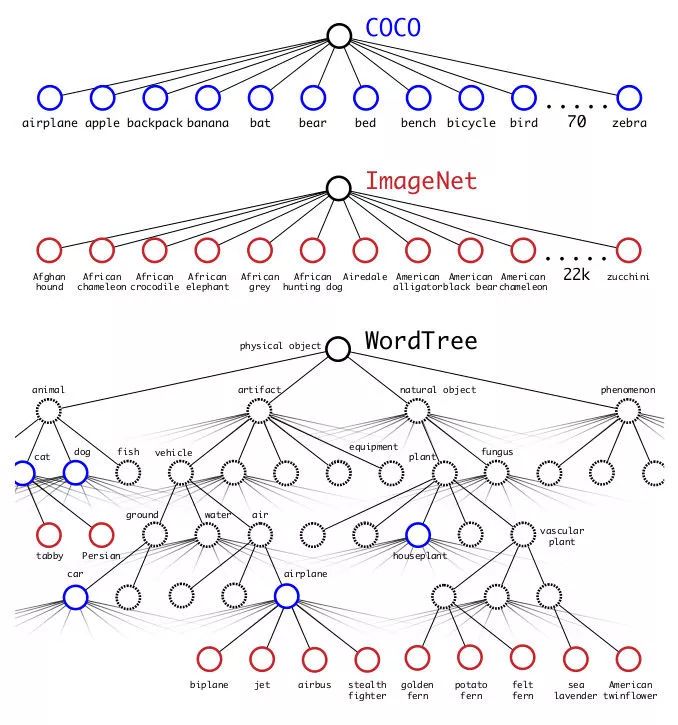
标签的合并
类似条件概率的方式计算每个子标签的概率值,超出一定的阈值com时则选定该类作为输出,训练时也仅对其路径上的类别进行损失的计算和BP。
YOLO9000为我们提供了一种泛化检测模型的训练方式,文章的结果显示YOLO9000在没有COCO标注的类别上有约20的mAP表现,能够检测的物体类别超过9000种。当然,其泛化性能也受检测标注类别的制约,在有类别继承关系的类上表现不错,而在完全没有语义联系的类上表现很差。
Mask R-CNN
Mask R-CNN通过将检测和实例分割联合训练的方式同时提高了分割和检测的精度。在原有Faster R-CNN的头部中分类和位置回归两个并行分支外再加入一个实例分割的并行分支,并将三者的损失联合训练。
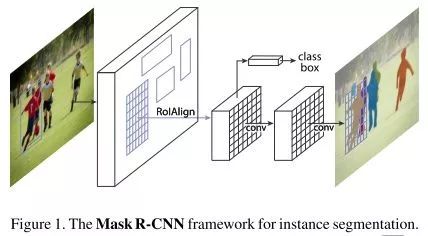
Mask R-CNN的头部结构
在分割方面,文章发现对每个类别单独生成二值掩膜(Binary Mask)相比之前工作中的多分类掩膜更有效,这样避免了类间竞争,仍是分类和标记的解耦。文章另外的一个贡献是RoIAlign的提出,笔者认为会是检测模型的标配操作。
FAIR团队在COCO Chanllege 2017上基于Mask R-CNN也取得了前列的成绩,但在实践领域,实例分割的标注相比检测标注要更加昂贵,而且按照最初我们对图像理解的三个层次划分,中层次的检测任务借用深层次的分割信息训练,事实上超出了任务的要求。
Focal Loss(RetinaNet)
Focal Loss for Dense Object Detection
由于缺少像两阶段模型的样本整理操作,单阶段模型的检测头部常常会面对比两阶段多出1-2个数量级的Region Proposal,文章作者认为,这些Proposal存在类别极度不均衡的现象,导致了简单样本的损失掩盖了难例的损失,这一easy example dominating的问题是单阶段模型精度不如两阶段的关键。
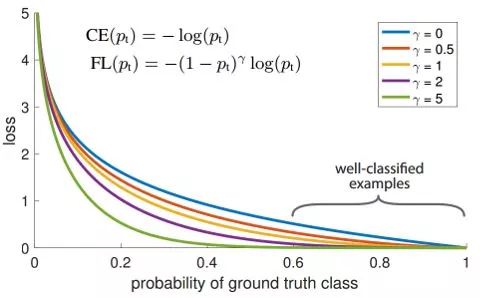
Focal Loss随概率变化曲线
于是,文章提出的解决措施即是在不同样本间制造不平衡,让简单样本的损失在整体的贡献变小,使模型更新时更关注较难的样本。具体的做法是根据预测概率给交叉熵的相应项添加惩罚系数,使得预测概率越高(越有把握)的样本,计算损失时所占比例越小。
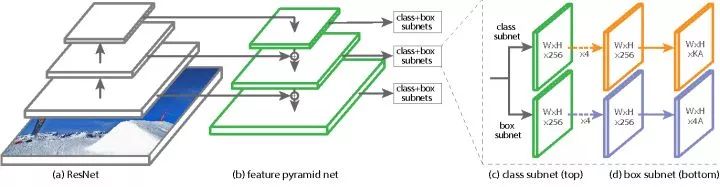
RetinaNet结构
以ResNet的FPN为基础网络,添加了Focal Loss的RetinaNet取得了跟两阶段模型相当甚至超出的精度。另外,Focal Loss的应用也不只局限在单阶段检测器,其他要处理类别不均衡问题任务上的应用也值得探索。
Mimicking
Mimicking Very Efficient Network for Object Detection
http://openaccess.thecvf.com/content_cvpr_2017/papers/Li_Mimicking_Very_Efficient_CVPR_2017_paper.pdf
本篇文章是Mimicking方法在检测任务上的尝试。mimicking作为一种模型压缩的方法,采用大网络指导小网络的方式将大网络习得的信息用小网络表征出来,在损失较小精度的基础上大幅提升速度。
Mimicking方法通常会学习概率输出的前一层,被称为"Deep-ID",这一层的张量被认为是数据在经过深度网络后得到的一个高维空间嵌入,在这个空间中,不同类的样例可分性要远超原有表示,从而达到表示学习的效果。本文作者提出的mimicking框架则是选择检测模型中基础网络输出的feature map进行学习,构成下面的结构:
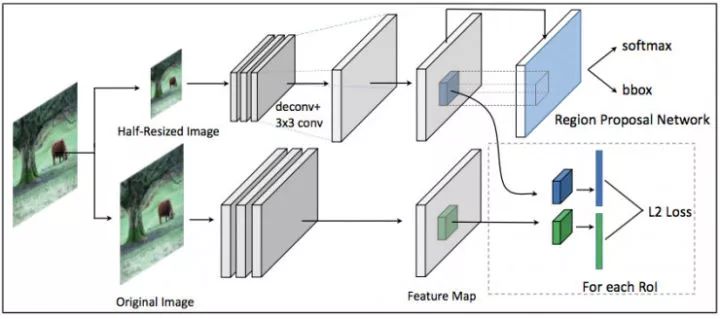
Mimicking网络结构
图中,上面分支是进行学习的小网络,下面分支的大网络则由较好表现的模型初始化,输入图片后,分别得到不同的feature map,小网络同时输入RPN的分类和位置回归,根据这一RoI Proposal,在两个分支的feature map上提取区域feature,令大网络的feature作为监督信息跟小网络计算L2 Loss,并跟RPN的损失构成联合损失进行学习。而对RCNN子网络,可用分类任务的mimicking方法进行监督。
文章在Pascal VOC上的实验显示这种mimicking框架可以在相当的精度下实现2倍以上的加速效果。
CGBN(Cross GPU Batch Normalization)
MegDet: A Large Mini-Batch Object Detector
https://arxiv.org/abs/1711.07240
这篇文章提出了多卡BN的实现思路,使得检测模型能够以较大的batch进行训练。
之前的工作中,两阶段模型常常仅在一块GPU上处理1-2张图片,生成数百个RoI Proposal供RCNN子网络训练。这样带来的问题是每次更新只学习了较少语义场景的信息,不利于优化的稳定收敛。要提高batch size,根据Linear Scaling Rule,需要同时增大学习率,但较大的学习率又使得网络不易收敛,文章尝试用更新BN参数的方式来稳定优化过程(基础网络的BN参数在检测任务上fine-tuning时通常固定)。加上检测中常常需要较大分辨率的图片,而GPU内存限制了单卡上的图片个数,提高batch size就意味着BN要在多卡(Cross-GPU)上进行。
BN操作需要对每个batch计算均值和方差来进行标准化,对于多卡,具体做法是,单卡独立计算均值,聚合(类似Map-Reduce中的Reduce)算均值,再将均值下发到每个卡,算差,再聚合起来,计算batch的方差,最后将方差下发到每个卡,结合之前下发的均值进行标准化。
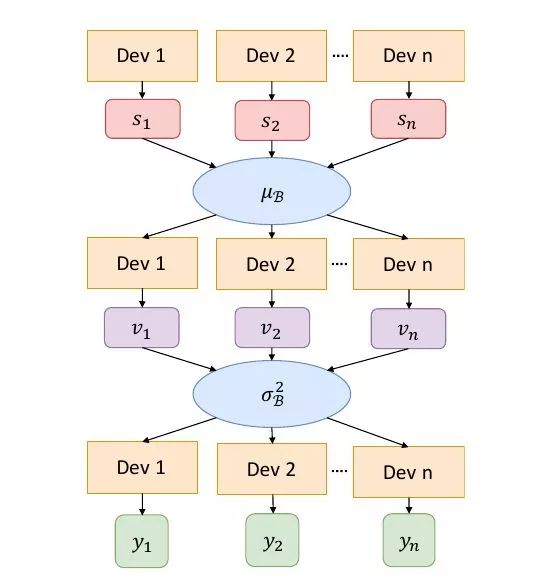
CGBN实现流程
更新BN参数的检测模型能够在较大的batch size下收敛,也大幅提高了检测模型的训练速度,加快了算法的迭代速度。
DSOD(Deeply Supervised Object Detector)
DSOD: Learning Deeply Supervised Object Detectors from Scratch
https://arxiv.org/abs/1708.01241
R-CNN工作的一个深远影响是在大数据集(分类)上pre-train,在小数据集(检测)fine-tune的做法,本文指出这限制了检测任务上基础网络结构的调整(需要在ImageNet上等预训练的分类网络),也容易引入分类任务的bias,因而提出从零训练检测网络的方法。
作者认为,由于RoI的存在,两阶段检测模型从零训练难以收敛,从而选择Region-free的单阶段方法进行尝试。一个关键的发现是,从零训练的网络需要Deep Supervision,文中采用紧密连接的方式来达到隐式Deep Supervision的效果,因而DSOD的基础网络部分类似DenseNet,浅层的feature map也有机会得到更接近损失函数的监督。
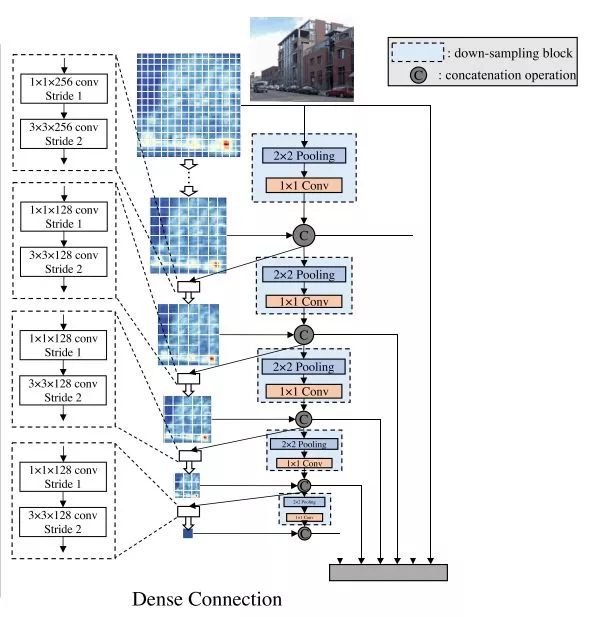
DSOD结构
文章的实验显示,DSOD从零开始训练也可以达到更SSD等相当的精度,并且模型的参数更少,但速度方面有所下降。
A-Fast-RCNN
A-Fast-RCNN: Hard Positive Generation via Adversary for Object Detection
https://arxiv.org/abs/1704.03414
本文将GAN引入检测模型,用GAN生成较难的样本以提升检测网络应对遮挡(Occlusion)、形变(Deformation)的能力。
对于前者,作者设计了ASDN(Adversarial Spatial Dropout Network),在feature map层面生成mask来产生对抗样本。对于feature map,在旁支上为每个位置生成一个概率图,根据一定的阈值将部分feature map上的值drop掉,再传入后面的头部网络。
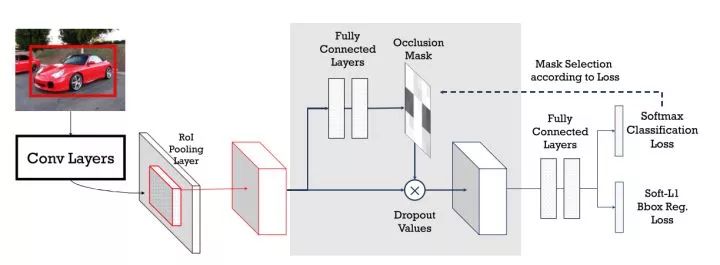
ASDN
类似的,ASTN(Adversarial Spatial Transformer Network)在旁支上生成旋转等形变并施加到feature map上。整体上,两个对抗样本生成的子网络串联起来,加入到RoI得到的feature和头部网络之间。
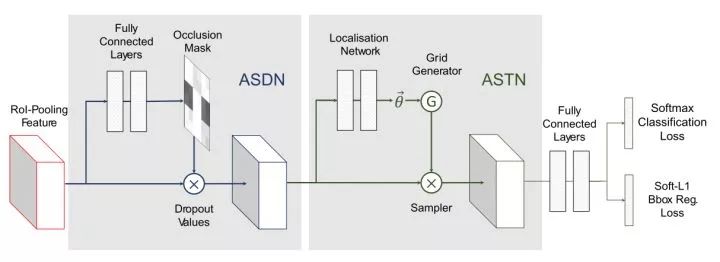
ASDN和ASTN被串联
文中的实验显示,在VOC上,对抗训练对plant, bottle等类别的检测精度有提升,但对个别类别却有损害。这项工作是GAN在检测任务上的试水,在feature空间而不是原始数据空间生成对抗样本的思路值得借鉴。
Relation Module
Relation Networks for Object Detection
https://arxiv.org/abs/1711.11575
Attention机制在自然语言处理领域取得了有效的进展,也被SENet等工作引入的计算机视觉领域。本文试图用Attention机制建模目标物体之间的相关性。
理解图像前背景的语义关系是检测任务的潜在目标,权威数据集COCO的收集过程也遵循着在日常情景中收集常见目标的原则,本文则从目标物体间的关系入手,用geometric feature(fG)和appearance feature(fA)来表述某一RoI,并联合其他RoI建立relation后,生成一个融合后的feature map。计算如下图:
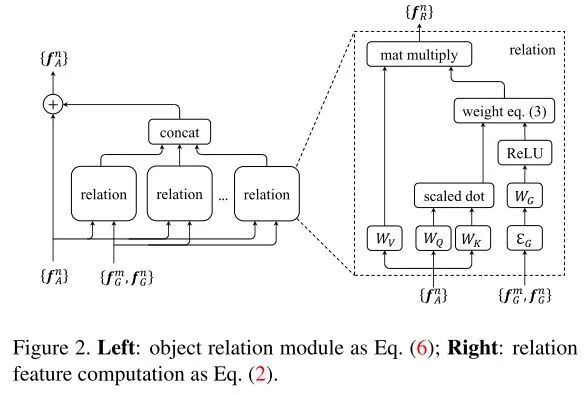
Relation Module
作者将这样的模块插入两阶段检测器的头部网络,并用改装后的duplicate removal network替代传统的NMS后处理操作,形成真正端到端的检测网络。在Faster R-CNN, FPN, Deformable ConvNets上的实验显示,加入Relation Module均能带来精度提升。
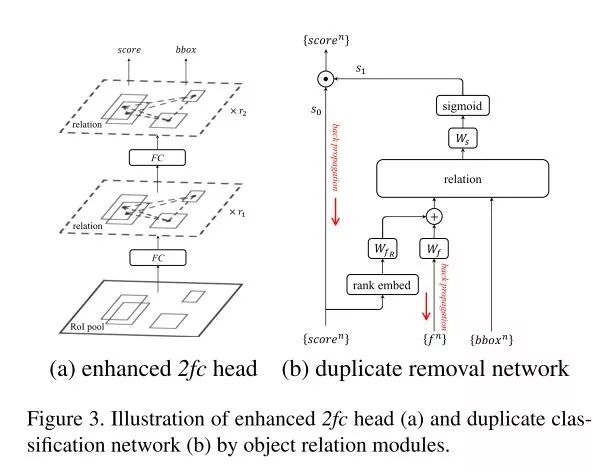
Relation Module应用在头部网络和替代NMS
结语
检测领域在近年来取得的进展只是这场深度模型潮流的一个缩影。理解图像、理解视觉这一机器视觉的中心问题上,仍不断有新鲜的想法出现。推动整个机器视觉行业跃进的同时,深度模型也越来越来暴露出自身的难收敛、难解释等等问题,整个领域仍在负重前行。
本系列文章梳理了检测任务上深度方法的经典工作和较新的趋势,并总结了常用的测评集和训练技巧,期望为读者建立对这一任务的基本认识。在介绍对象的选择和章节的划分上,都带有笔者自己的偏见,本文仅仅可作为一个导读,更多的细节应参考实现的代码,更多的讨论应参考文章作者的扩展实验。
事实上,每项工作都反映着作者对这一问题的洞察,而诸多工作间的横向对比也有助于培养独立和成熟的视角来评定每项工作的贡献。另外,不同文献间的相互引述、所投会议期刊审稿人的意见等,都是比本文更有参考价值的信息来源。
在工业界还有更多的问题,比如如何做到单模型满足各种不同场景的需求,如何解决标注中的噪声和错误干扰,如何针对具体业务类型(如人脸)设计特定的网络,如何在廉价的硬件设备上做更高性能的检测,如何利用优化的软件库、模型压缩方法进行加速等等,就不在本文讨论之列。

人工智能赛博物理操作系统
AI-CPS OS
“人工智能赛博物理操作系统”(新一代技术+商业操作系统“AI-CPS OS”:云计算+大数据+物联网+区块链+人工智能)分支用来的今天,企业领导者必须了解如何将“技术”全面渗入整个公司、产品等“商业”场景中,利用AI-CPS OS形成数字化+智能化力量,实现行业的重新布局、企业的重新构建和自我的焕然新生。
AI-CPS OS的真正价值并不来自构成技术或功能,而是要以一种传递独特竞争优势的方式将自动化+信息化、智造+产品+服务和数据+分析一体化,这种整合方式能够释放新的业务和运营模式。如果不能实现跨功能的更大规模融合,没有颠覆现状的意愿,这些将不可能实现。
领导者无法依靠某种单一战略方法来应对多维度的数字化变革。面对新一代技术+商业操作系统AI-CPS OS颠覆性的数字化+智能化力量,领导者必须在行业、企业与个人这三个层面都保持领先地位:
重新行业布局:你的世界观要怎样改变才算足够?你必须对行业典范进行怎样的反思?
重新构建企业:你的企业需要做出什么样的变化?你准备如何重新定义你的公司?
重新打造自己:你需要成为怎样的人?要重塑自己并在数字化+智能化时代保有领先地位,你必须如何去做?
AI-CPS OS是数字化智能化创新平台,设计思路是将大数据、物联网、区块链和人工智能等无缝整合在云端,可以帮助企业将创新成果融入自身业务体系,实现各个前沿技术在云端的优势协同。AI-CPS OS形成的数字化+智能化力量与行业、企业及个人三个层面的交叉,形成了领导力模式,使数字化融入到领导者所在企业与领导方式的核心位置:
精细:这种力量能够使人在更加真实、细致的层面观察与感知现实世界和数字化世界正在发生的一切,进而理解和更加精细地进行产品个性化控制、微观业务场景事件和结果控制。
智能:模型随着时间(数据)的变化而变化,整个系统就具备了智能(自学习)的能力。
高效:企业需要建立实时或者准实时的数据采集传输、模型预测和响应决策能力,这样智能就从批量性、阶段性的行为变成一个可以实时触达的行为。
不确定性:数字化变更颠覆和改变了领导者曾经仰仗的思维方式、结构和实践经验,其结果就是形成了复合不确定性这种颠覆性力量。主要的不确定性蕴含于三个领域:技术、文化、制度。
边界模糊:数字世界与现实世界的不断融合成CPS不仅让人们所知行业的核心产品、经济学定理和可能性都产生了变化,还模糊了不同行业间的界限。这种效应正在向生态系统、企业、客户、产品快速蔓延。
AI-CPS OS形成的数字化+智能化力量通过三个方式激发经济增长:
创造虚拟劳动力,承担需要适应性和敏捷性的复杂任务,即“智能自动化”,以区别于传统的自动化解决方案;
对现有劳动力和实物资产进行有利的补充和提升,提高资本效率;
人工智能的普及,将推动多行业的相关创新,开辟崭新的经济增长空间。
给决策制定者和商业领袖的建议:
超越自动化,开启新创新模式:利用具有自主学习和自我控制能力的动态机器智能,为企业创造新商机;
迎接新一代信息技术,迎接人工智能:无缝整合人类智慧与机器智能,重新
评估未来的知识和技能类型;
制定道德规范:切实为人工智能生态系统制定道德准则,并在智能机器的开
发过程中确定更加明晰的标准和最佳实践;
重视再分配效应:对人工智能可能带来的冲击做好准备,制定战略帮助面临
较高失业风险的人群;
开发数字化+智能化企业所需新能力:员工团队需要积极掌握判断、沟通及想象力和创造力等人类所特有的重要能力。对于中国企业来说,创造兼具包容性和多样性的文化也非常重要。
子曰:“君子和而不同,小人同而不和。” 《论语·子路》云计算、大数据、物联网、区块链和 人工智能,像君子一般融合,一起体现科技就是生产力。
如果说上一次哥伦布地理大发现,拓展的是人类的物理空间。那么这一次地理大发现,拓展的就是人们的数字空间。在数学空间,建立新的商业文明,从而发现新的创富模式,为人类社会带来新的财富空间。云计算,大数据、物联网和区块链,是进入这个数字空间的船,而人工智能就是那船上的帆,哥伦布之帆!
新一代技术+商业的人工智能赛博物理操作系统AI-CPS OS作为新一轮产业变革的核心驱动力,将进一步释放历次科技革命和产业变革积蓄的巨大能量,并创造新的强大引擎。重构生产、分配、交换、消费等经济活动各环节,形成从宏观到微观各领域的智能化新需求,催生新技术、新产品、新产业、新业态、新模式。引发经济结构重大变革,深刻改变人类生产生活方式和思维模式,实现社会生产力的整体跃升。
产业智能官 AI-CPS
用“人工智能赛博物理操作系统”(新一代技术+商业操作系统“AI-CPS OS”:云计算+大数据+物联网+区块链+人工智能),在场景中构建状态感知-实时分析-自主决策-精准执行-学习提升的认知计算和机器智能;实现产业转型升级、DT驱动业务、价值创新创造的产业互联生态链。


长按上方二维码关注微信公众号: AI-CPS,更多信息回复:
新技术:“云计算”、“大数据”、“物联网”、“区块链”、“人工智能”;新产业:“智能制造”、“智能金融”、“智能零售”、“智能驾驶”、“智能城市”;新模式:“财富空间”、“工业互联网”、“数据科学家”、“赛博物理系统CPS”、“供应链金融”。
官方网站:AI-CPS.NET
本文系“产业智能官”(公众号ID:AI-CPS)收集整理,转载请注明出处!
版权声明:由产业智能官(公众号ID:AI-CPS)推荐的文章,除非确实无法确认,我们都会注明作者和来源。部分文章推送时未能与原作者取得联系。若涉及版权问题,烦请原作者联系我们,与您共同协商解决。联系、投稿邮箱:erp_vip@hotmail.com


