深度学习时代的目标检测算法
目前目标检测领域的深度学习方法主要分为两类:two stage的目标检测算法;one stage的目标检测算法。前者是先由算法生成一系列作为样本的候选框,再通过卷积神经网络进行样本分类;后者则不用产生候选框,直接将目标边框定位的问题转化为回归问题处理。正是由于两种方法的差异,在性能上也有不同,前者在检测准确率和定位精度上占优,后者在算法速度上占优。
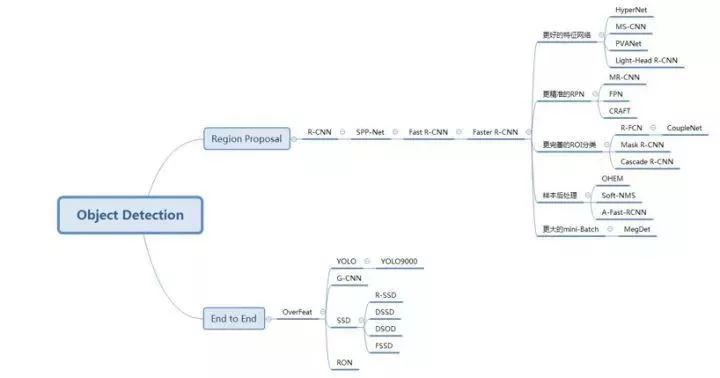
目标检测算法脉络
1. two stage的方法
在早期深度学习技术发展进程中,主要都是围绕分类问题展开研究,这是因为神经网络特有的结构输出将概率统计和分类问题结合,提供一种直观易行的思路。国内外研究人员虽然也在致力于将其他如目标检测领域和深度学习结合,但都没有取得成效,这种情况直到R-CNN算法出现才得以解决。
1.1 R-CNN
2014年加州大学伯克利分校的Ross B. Girshick提出R-CNN算法,其在效果上超越同期的Yann Lecun提出的端到端方法OverFeat算法,其算法结构也成为后续two stage的经典结构。
R-CNN算法利用选择性搜索(Selective Search)算法评测相邻图像子块的特征相似度,通过对合并后的相似图像区域打分,选择出感兴趣区域的候选框作为样本输入到卷积神经网络结构内部,由网络学习候选框和标定框组成的正负样本特征,形成对应的特征向量,再由支持向量机设计分类器对特征向量分类,最后对候选框以及标定框完成边框回归操作达到目标检测的定位目的。
虽然R-CNN算法相较于传统目标检测算法取得了50%的性能提升,但其也有缺陷存在:训练网络的正负样本候选区域由传统算法生成,使得算法速度受到限制;卷积神经网络需要分别对每一个生成的候选区域进行一次特征提取,实际存在大量的重复运算,制约了算法性能。
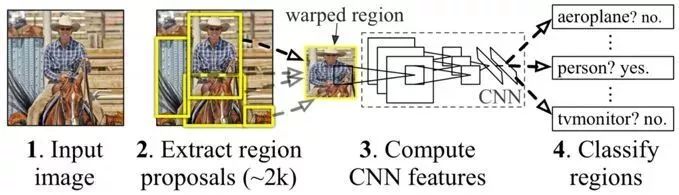
图1.1 R-CNN
1.2 SPP-Net
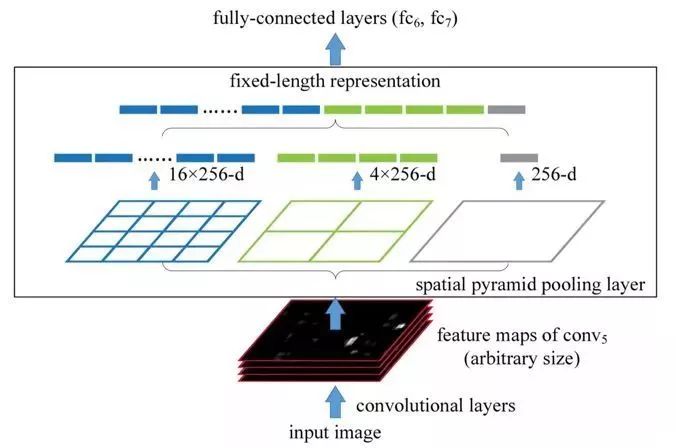
图1.2 spatial pyramid pooling layer
针对卷积神经网络重复运算问题,2015年微软研究院的何恺明等提出一种SPP-Net算法,通过在卷积层和全连接层之间加入空间金字塔池化结构(Spatial Pyramid Pooling)代替R-CNN算法在输入卷积神经网络前对各个候选区域进行剪裁、缩放操作使其图像子块尺寸一致的做法。
利用空间金字塔池化结构有效避免了R-CNN算法对图像区域剪裁、缩放操作导致的图像物体剪裁不全以及形状扭曲等问题,更重要的是解决了卷积神经网络对图像重复特征提取的问题,大大提高了产生候选框的速度,且节省了计算成本。但是和R-CNN算法一样训练数据的图像尺寸大小不一致,导致候选框的ROI感受野大,不能利用BP高效更新权重。
1.3 Fast R-CNN
针对SPP-Net算法的问题,2015年微软研究院的Ross B. Girshick又提出一种改进的Fast R-CNN算法,借鉴SPP-Net算法结构,设计一种ROI pooling的池化层结构,有效解决R-CNN算法必须将图像区域剪裁、缩放到相同尺寸大小的操作。
提出多任务损失函数思想,将分类损失和边框回归损失结合统一训练学习,并输出对应分类和边框坐标,不再需要额外的硬盘空间来存储中间层的特征,梯度能够通过RoI Pooling层直接传播。但是其仍然没有摆脱选择性搜索算法生成正负样本候选框的问题。
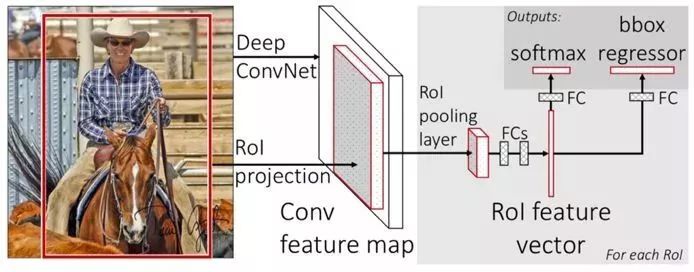
图1.3 Fast R-CNN
1.4 Faster R-CNN
为了解决Fast R-CNN算法缺陷,使得算法实现two stage的全网络结构,2015年微软研究院的任少庆、何恺明以及Ross B Girshick等人又提出了Faster R-CNN算法。设计辅助生成样本的RPN(Region Proposal Networks)网络,将算法结构分为两个部分,先由RPN网络判断候选框是否为目标,再经分类定位的多任务损失判断目标类型,整个网络流程都能共享卷积神经网络提取的的特征信息,节约计算成本,且解决Fast R-CNN算法生成正负样本候选框速度慢的问题,同时避免候选框提取过多导致算法准确率下降。
但是由于RPN网络可在固定尺寸的卷积特征图中生成多尺寸的候选框,导致出现可变目标尺寸和固定感受野不一致的现象。
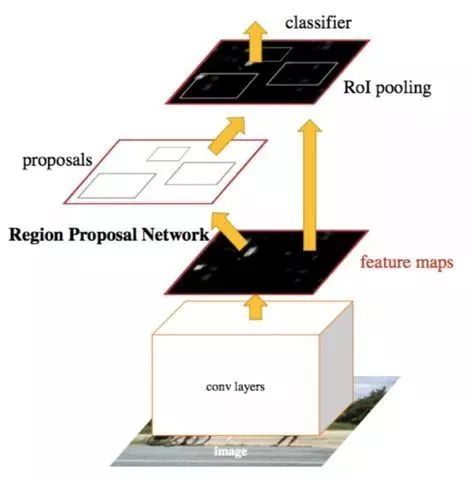
图1.4 Faster R-CNN
1.5 MR-CNN
2015年巴黎科技大学提出MR-CNN算法,结合样本区域本身的特征,利用样本区域周围采样的特征和图像分割的特征来提高识别率,可将检测问题分解为分类和定位问题。
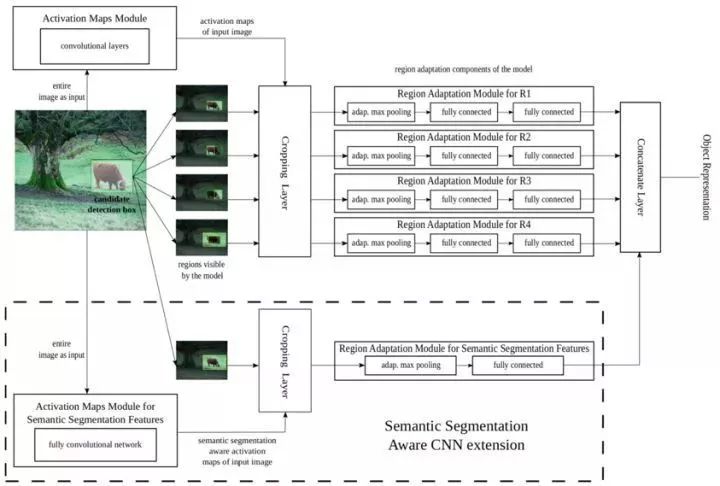
图1.5 MR-CNN
分类问题由Multi-Region CNN Model和Semantic Segmentation-Aware CNN Model组成。前者的候选框由Selective Search得到,对于每一个样本区域,取10个区域分别提取特征后拼接,这样可以强制网络捕捉物体的不同方面,同时可以增强网络对于定位不准确的敏感性,其中adaptive max pooling即ROI max pooling;后者使用FCN进行目标分割,将最后一层的feature map和前者产生的feature map拼接,作为最后的feature map。
为了较精确定位,采用三种样本边框修正方法,分别为Bbox regression、Iterative localization以及Bounding box voting。Bbox regression:在Multi-Region CNN Model中整幅图经过网路的最后一层卷积层后,接一个Bbox regression layer,与RPN不同,此处的regression layer是两层FC以及一层prediction layer,为了防止Selective Search得到的框过于贴近物体而导致无法很好的框定物体,将候选框扩大为原来的1.3倍再做。
Iterative localization:初始的框是Selective Search得到的框,然后用已有的分类模型对框做出估值,低于给定阈值的框被筛掉,剩下的框用Bbox regression的方法调整大小,并迭代筛选。Bounding box voting:首先对经过Iterative localization处理后的框应用NMS, IOU = 0.3,得到检测结果,然后对于每一个框,用每一个和其同一类的而且IOU >0.5的框加权坐标,得到最后的目标样本框。
1.6 HyperNet
2016年清华大学提出HyperNet算法,其利用网络多个层级提取的特征,且从较前层获取的精细特征可以减少对于小物体检测的缺陷。将提取到的不同层级feature map通过较大池化降维或逆卷积扩增操作使得所有feature map尺寸一致,并利用LRN正则化堆叠,形成Hyper
Feature maps,其具有多层次抽象、合适分辨率以及计算时效性的优点。接着通过region proposal generation module结构进行预测和定位,仅保留置信度较高的N个样本框进行判断。
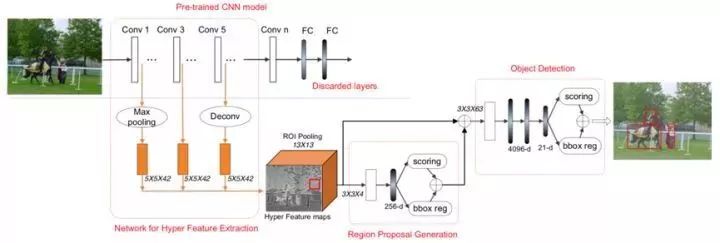
图1.6 HyperNet
1.7 CRAFT
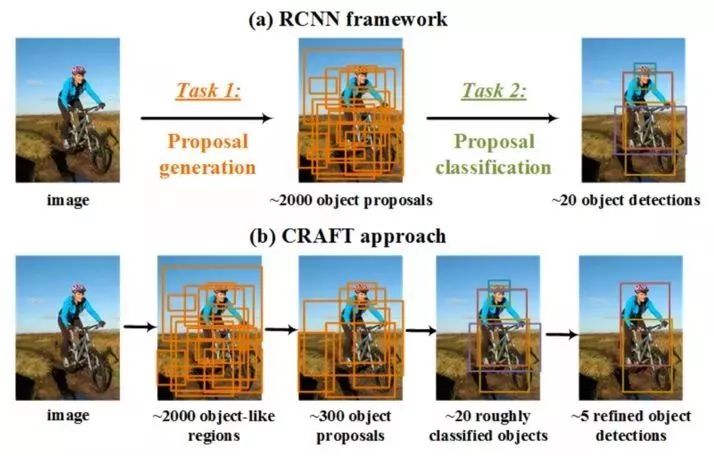
图1.7 CRAFT
R-CNN系列算法的第一阶段是生成目标proposals,第二阶段是对目标proposals进行分类,2016年中科院自动化所提出的CRAFT算法分别对Faster R-CNN中的这两个阶段进行了一定的改进。
对于生成目标proposals阶段,在RPN的后面加了一个二值的Fast R-CNN分类器来对RPN生成的proposals进行进一步的筛选,留下一些高质量的proposals;对于第二阶段的目标proposals分类,在原来的分类器后又级联了N个类别(不包含背景类)的二值分类器以进行更精细的目标检测。
1.8 R-FCN
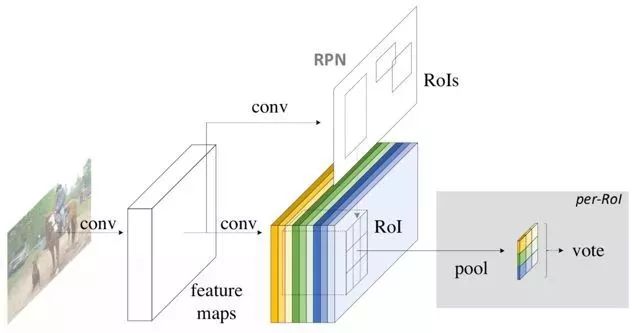
图1.8 R-FCN
随着全卷积网络的出现,2016年微软研究院的Jifeng Dai等提出R-FCN算法。相较于Faster R-CNN算法只能计算ROI pooling层之前的卷积网络特征参数,R-FCN算法提出一种位置敏感分布的卷积网络代替ROI pooling层之后的全连接网络,解决了Faster R-CNN由于ROI
Pooling层后面的结构需要对每一个样本区域跑一次而耗时比较大的问题,使得特征共享在整个网络内得以实现,解决物体分类要求有平移不变性和物体检测要求有平移变化的矛盾,但是没有考虑到region proposal的全局信息和语义信息。
1.9 MS-CNN
针对Faster R-CNN算法的遗留问题,2016年加州大学圣地亚哥分校的Z Cai提出了MS-CNN算法,通过利用Faster R-CNN算法结构的多个不同层级输出的特征结果来检测目标,将不同层级的检测器互补形成多尺度的强检测器,应用浅层特征检测小尺寸目标,应用深层特征检测大尺寸目标。并且利用去卷积层代替图像上采样来增加图像分辨率,减少内存占用,提高运行速度。
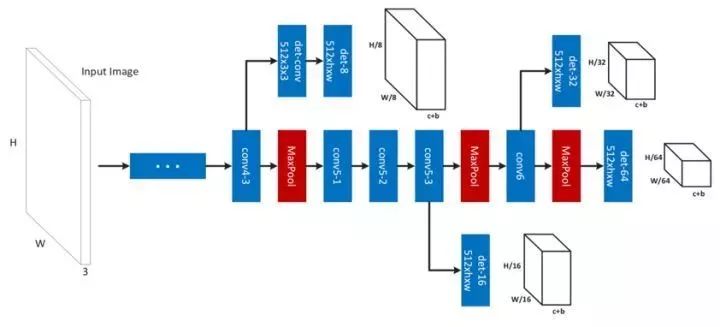
图1.9 MS-CNN的特征网络
1.10 PVANet
针对的就是算法的运算速度提升问题,2016年底Intel图像技术团队提出了一个轻量级的网络,取得了state-of-the-art的效果。PVANet主要分为特征抽取网络和检测网络,基于多层少通道的基本原则,在网络浅层采用C.ReLU结构,在网络深层采用Inception模块,其中前者是将K×K卷积结构表示1×1 - K×K - 1×1的卷积层的堆叠,后者设计原则是由于为了检测图像中的大目标,需要足够大的感受野,可通过堆叠3×3的卷积核实现,但是为了捕获小目标,则需要小一点的感受野,可通过1×1的卷积核实现,且可以避免大卷积核造成的参数冗余问题。
PVANet应用多尺度特征级联较大化目标检测任务的多尺度性质,权重衰减策略采用一定迭代次数内loss不再下降,则将学习速率降低常数倍的方式,通过batch normalization和residual连接实现高效的训练。
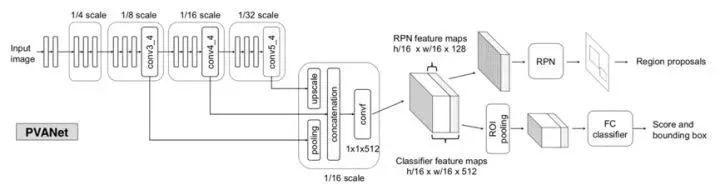
图1.10 PVANet
1.11 FPN
2017年Facebook的Tsung-Yi Lin等提出了FPN算法,利用不同层的特征图进行不同尺寸的目标预测。原来多数的目标检测算法都是只采用深层特征做预测,低层的特征语义信息比较少,但是目标位置准确;高层的特征语义信息比较丰富,但是目标位置比较粗略。
另外虽然也有些算法采用多尺度特征融合的方式,但是一般是采用融合后的特征做预测,而FPN算法不一样的地方在于预测是在不同特征层独立进行的,利用深层特征通过上采样和低层特征做融合。
FPN算法主网络是ResNet,结构主要是一个自底向上的线路横向连接一个自顶向下的线路。自底向上其实就是网络的前向过程,在前向过程中,feature map的大小在经过某些层后会改变,而在经过其他一些层的时候不会改变,FPN算法将不改变feature map大小的层归为一个stage,因此每次抽取的特征都是每个stage的最后一个层输出,这样就能构成特征金字塔。
自顶向下的过程采用上采样进行,而横向连接则是将上采样的结果和自底向上生成的相同大小的feature map并一一对应进行融合,在融合之后还会再采用3×3的卷积核对每个融合结果进行卷积,目的是消除上采样的混叠效应。
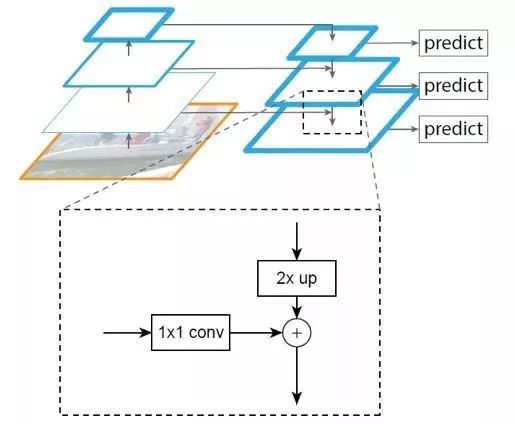
图1.11 FPN
1.12 Mask R-CNN
为了解决R-CNN算法为代表的two stage的方法问题,2017年Facebook的何恺明等提出了Mask R-CNN算法,取得了很好的识别效果。
Mask R-CNN算法将ROI_Pooling层替换成了ROI_Align,并且在边框识别的基础上添加分支FCN层(mask层),用于语义Mask识别,通过RPN网络生成目标候选框,再对每个目标候选框分类判断和边框回归,同时利用全卷积网络对每个目标候选框预测分割掩膜。
加入的掩膜预测结构解决了特征图像和原始图像上的ROI不对准问题,避免对ROI边界做任何量化,而用双线性插值到对准特征,再用池化操作融合。掩膜编码了输入图像的空间布局,用全卷积网络预测每个目标候选框的掩膜能完整的保留空间结构信息,实现目标像素级分割定位。
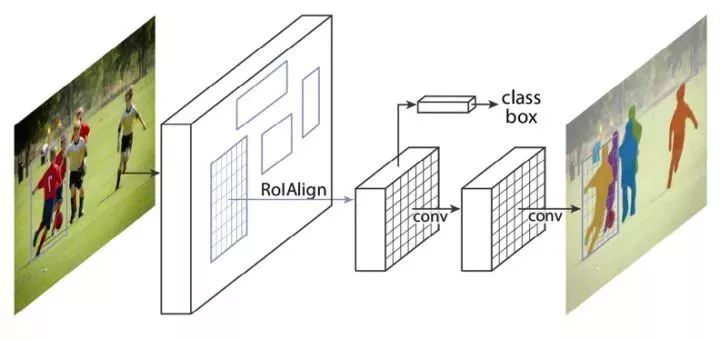
图1.12 Mask R-CNN
1.13 A-Fast-RCNN
A-Fast-RCNN算法是2017年卡内基梅隆大学提出的,其将对抗学习引入到目标检测问题中,通过对抗网络生成一下遮挡和变形的训练样本来训练检测网络,从而使得网络能够对遮挡和变形问题更加的鲁棒。使用对抗网络生成有遮挡和有形变的两种特征,两种网络分别为ASDN和ASTN。
ASDN利用Fast R-CNN中ROI池化层之后的每个目标proposal卷积特征作为对抗网络的输入,给定一个目标的特征,ASDN尝试生成特征某些部分被dropout的掩码,导致检测器无法识别该物体。
在前向传播过程中,首先使用ASDN在ROI池化层之后生成特征掩码,然后使用重要性采样法生成二值掩码,使用该掩码将特征对应部位值清零,修改后的特征继续前向传播计算损失,这个过程生成了困难的特征,用于训练检测器。
ASTN主要关注特征旋转,定位网络包含三层全连接层,前两层是ImageNet预训练的FC6和FC7,训练过程与ASDN类似,ASTN对特征进行形变,将特征图划分为4个block,每个block估计四个方向的旋转,增加了任务的复杂度。两种对抗网络可以相结合,使得检测器更鲁棒,ROI池化层提取的特征首先传入ASDN丢弃一些激活,之后使用ASTN对特征进行形变。
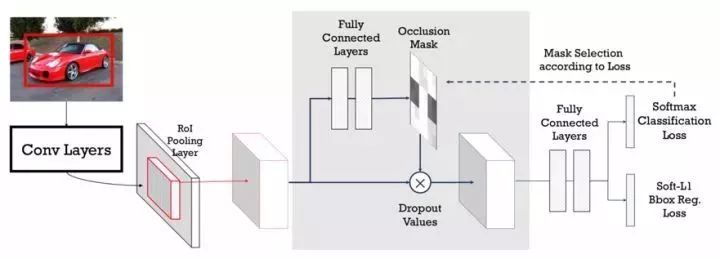
图1.13 A-Fast-RCNN
1.14 CoupleNet
针对R-FCN算法没有考虑到region proposal的全局信息和语义信息的问题,2017年中科院自动化所提出CoupleNet算法,其在原来R-FCN的基础上引入了proposal的全局和语义信息,通过结合局部、全局以及语义的信息,提高了检测的精度。
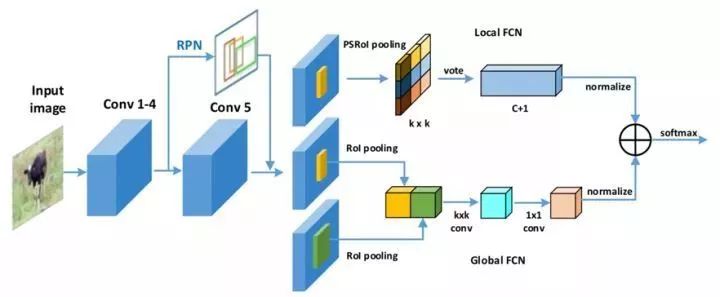
图1.14 CoupleNet
CoupleNet结构利用三支并行网络实现检测,上面的支路网络使用原本的R-FCN结构的位置敏感分布图提取目标的局部信息;中间的支路网络用于提取目标的全局信息,对于一个region proposal,依次通过K×K的ROI Pooling,K×K的conv以及1×1的conv;下面的支路网络用于提取目标的语义信息,对于一个region proposal,首先选择以这个proposal为中心,面积是原来2倍的proposal,同样依次通过K×K的ROI Pooling,K×K的conv以及1×1的conv。最后先各自通过1×1的conv调整激活值的尺寸,然后把Local FCN和Global FCN结果对应位置元素相加,再通过一个softmax实现分类。
1.15 MegDet
基于CNN的物体检测研究一直在不断进步,从R-CNN到Fast/Faster R-CNN,再Mask R-CNN,主要的改进点都在于新的网络架构、新的范式、或者新的损失函数设计,然而mini-batch大小,这个训练中的关键因素并没有得到完善的研究。
由于输入图片尺寸的增长,图像检测所需显存量也会同比例增长,这也使得已有的深度学习框架无法训练大mini-batch的图像检测模型,而小mini-batch的物体检测算法又常常会引入不稳定的梯度、BN层统计不准确、正负样本比例失调以及超长训练时间的问题。因此,2017年12月Face++提出一种大mini-batch的目标检测算法MegDet。
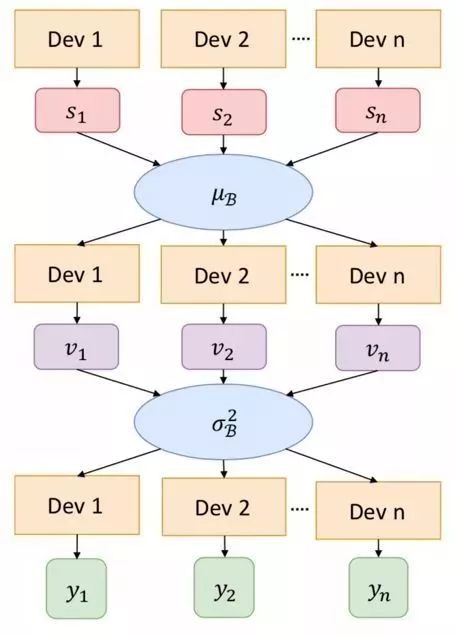
图1.15 多GPU的Batch Normalization
MegDet算法可以使用远大于以往的mini-batch大小训练网络(比如从16增大到256),这样同时也可以高效地利用多块GPU联合训练(在论文的实验中最多使用了128块GPU),大大缩短训练时间。
同时,解决了BN统计不准确的问题,也提出了一种学习率选择策略以及跨GPU的Batch Normalization方法,两者共同使用就得以大幅度减少大mini-batch物体检测器的训练时间(比如从33小时减少到仅仅4个小时),同时还可以达到更高的准确率。
1.16 Light-Head R-CNN
2017年12月Face++提出了一种为了使two stage的检测算法Light-Head R-CNN,主要探讨了R-CNN如何在物体检测中平衡较精确度和速度。Light-Head R-CNN提出了一种更好的two-stage detector设计结构,使用一个大内核可分卷积和少量通道生成稀疏的特征图。
该设计的计算量使随后的ROI子网络计算量大幅降低,检测系统所需内存减少。将一个廉价的全连接层附加到池化层上,充分利用分类和回归的特征表示。因其轻量级头部结构,该检测器能够实现速度和准确率之间的最优权衡,不管使用的是大主干网络还是小主干网络。
基于ResNet101网络达到了新的state-of-the-art的结果40.6,超过了Mask R-CNN和RetinaNet。同时如果是用一个更小的网络,比如类似Xception的小模型,达到了100+FPS,30.7mmap,效率上超过了SSD和YOLO。
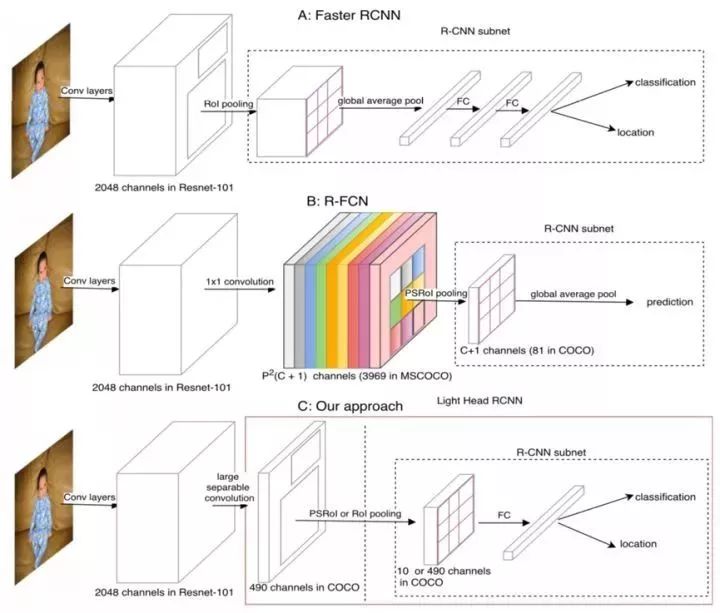
图1.16 Light-Head R-CNN
2. one stage的方法
以R-CNN算法为代表的two stage的方法由于RPN结构的存在,虽然检测精度越来越高,但是其速度却遇到瓶颈,比较难于满足部分场景实时性的需求。因此出现一种基于回归方法的one stage的目标检测算法,不同于two stage的方法的分步训练共享检测结果,one stage的方法能实现完整单次训练共享特征,且在保证一定准确率的前提下,速度得到极大提升。
2.1 OverFeat
2013年Yann Lecun在纽约大学的团队提出了著名的OverFeat算法,其利用滑动窗口和规则块生成候选框,再利用多尺度滑动窗口增加检测结果,解决图像目标形状复杂、尺寸不一问题,最后利用卷积神经网络和回归模型分类、定位目标。该算法首次将分类、定位以及检测三个计算机视觉任务放在一起解决,获得同年ILSVRC 2013任务3(分类+定位)的冠军,但其很快就被同期的R-CNN算法取代。
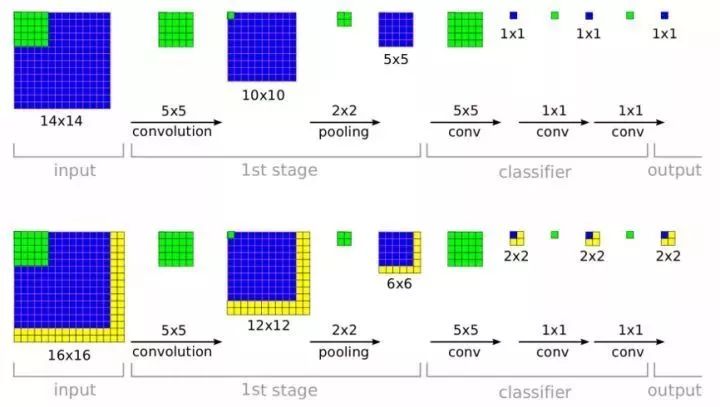
图2.1 用于检测的高效卷积
2.2 YOLO
2015年华盛顿大学的Joseph Redmon等提出的YOLO算法继承了OverFeat算法这种基于回归的one stage方法,速度能达到每秒45帧,由于其速度优势迅速成为端到端方法的领先者。YOLO算法是基于图像的全局信息进行预测的,整体结构简单,通过将输入图像重整到448×448像素固定尺寸大小,并划分图像为7×7网格区域,通过卷积神经网络提取特征训练,直接预测每个网格内的边框坐标和每个类别置信度,训练时采用P-Relu激活函数。但是存在定位不准以及召回率不如基于区域提名方法的问题,且对距离很近的物体和很小的物体检测效果不好,泛化能力相对较弱。
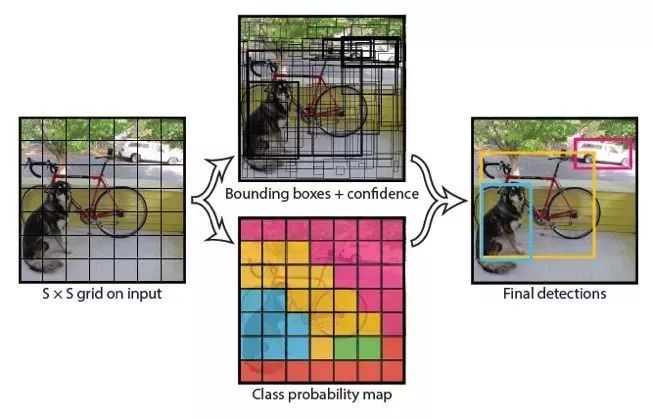
图2.2 YOLO
2.3 YOLOv2 & YOLO9000
经过Joseph Redmon等的改进,YOLOv2和YOLO9000算法在2017年CVPR上被提出,并获得较佳论文提名,重点解决召回率和定位精度方面的误差。采用Darknet-19作为特征提取网络,增加了批量归一化(Batch Normalization)的预处理,并使用224×224和448×448两阶段训练ImageNet预训练模型后fine-tuning。
相比于原来的YOLO是利用全连接层直接预测bounding box的坐标,YOLOv2借鉴了Faster R-CNN的思想,引入anchor机制,利用K-Means聚类的方式在训练集中聚类计算出更好的anchor模板,在卷积层使用anchorboxes操作,增加候选框的预测,同时采用较强约束的定位方法,大大提高算法召回率。结合图像细粒度特征,将浅层特征与深层特征相连,有助于对小尺寸目标的检测。
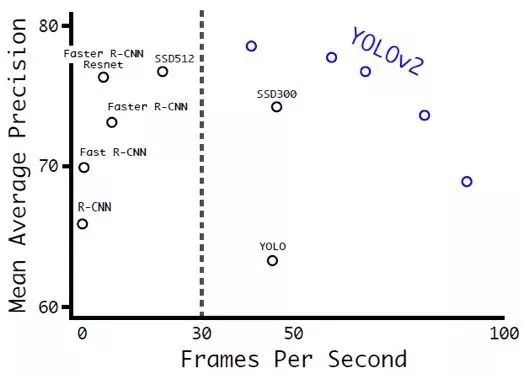
图2.3 YOLOv2在VOC2007上的速度和精度
2.4 G-CNN
由于巨大的proposal数量使得后续检测效率降低,2016年马里兰大学的M Najibi等提出一种起始于网格迭代的G-CNN算法。通过初始化对图像划分回归后得到更加接近物体的候选框,再利用回归框作为原始窗口进行回归调整,解决了以往的基于区域提名方法通过海量潜在候选框直接进行目标搜索,抑制负样本的缺陷。
在训练阶段,首先在图像中获取叠加的多尺度的规则网格(实际网格相互叠加),然后通过ground truth与每一个网格的IOU进行每一个网格ground truth的分配,并完成训练过程,使得网格在回归过程中渐渐接近ground truth。在检测阶段,对于每一个样本框针对每一类获得置信分数,用最可能类别的回归器来更新样本框的位置。
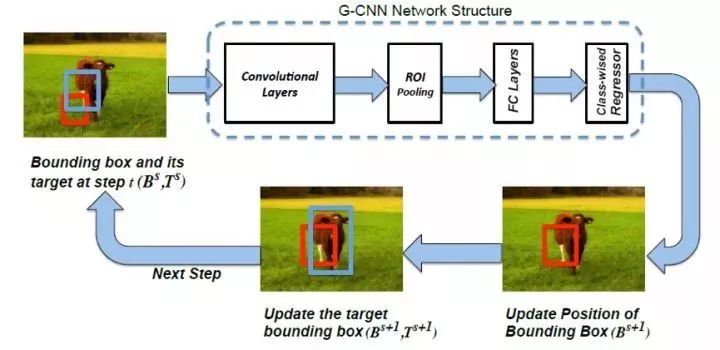
图2.4 G-CNN
2.5 SSD
针对YOLO类算法的定位精度问题,2016年12月北卡大学教堂山分校的Wei Liu等提出SSD算法,将YOLO的回归思想和Faster R-CNN的anchor box机制结合。通过在不同卷积层的特征图上预测物体区域,输出离散化的多尺度、多比例的default boxes坐标,同时利用小卷积核预测一系列候选框的边框坐标补偿和每个类别的置信度。
在整幅图像上各个位置用多尺度区域的局部特征图边框回归,保持YOLO算法快速特性的同时,也保证了边框定位效果和Faster R-CNN类似。但因其利用多层次特征分类,导致其对于小目标检测困难,最后一个卷积层的感受野范围很大,使得小目标特征不明显。
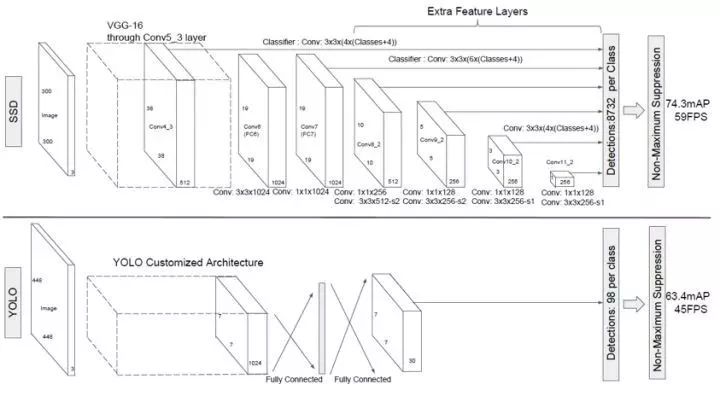
图2.5 SSD和YOLO网络结构对比
2.6 R-SSD
2017年首尔大学提出了R-SSD算法,解决了SSD算法中不同层feature map都是独立作为分类网络的输入,容易出现相同物体被不同大小的框同时检测出来的情况,还有对小尺寸物体的检测效果比较差的情况。R-SSD算法一方面利用分类网络增加不同层之间的feature map联系,减少重复框的出现;另一方面增加feature pyramid中feature map的个数,使其可以检测更多的小尺寸物体。
特征融合方式采用同时利用pooling和deconvolution进行特征融合,这种特征融合方式使得融合后每一层的feature map个数都相同,因此可以共用部分参数,具体来讲就是default boxes的参数共享。
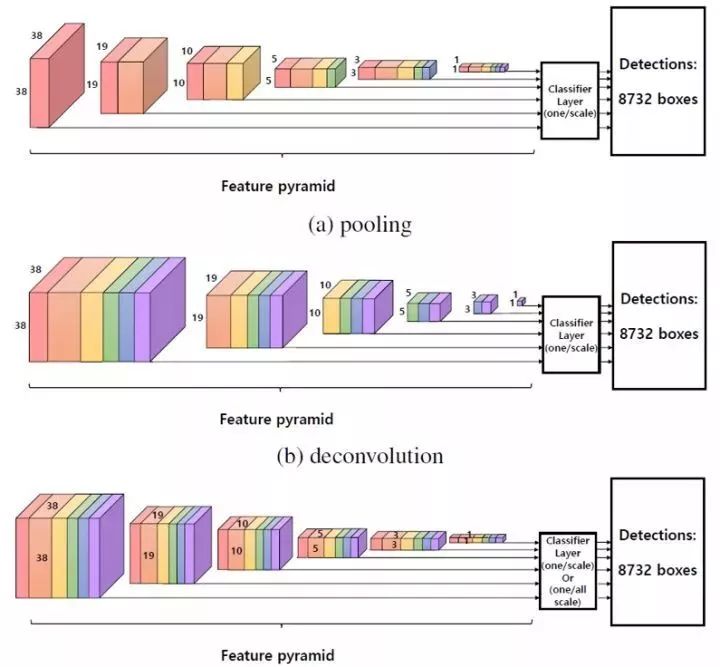
图2.6 三种特征融合方式
2.7 DSSD
为了解决SSD算法检测小目标困难的问题,2017年北卡大学教堂山分校的Cheng-Yang Fu等提出DSSD算法,将SSD算法基础网络从VGG-16更改为ResNet-101,增强网络特征提取能力,其次参考FPN算法思路利用去卷积结构将图像深层特征从高维空间传递出来,与浅层信息融合,联系不同层级之间的图像语义关系,设计预测模块结构,通过不同层级特征之间融合特征输出预测物体类别信息。
DSSD算法中有两个特殊的结构:Prediction模块;Deconvolution模块。前者利用提升每个子任务的表现来提高准确性,并且防止梯度直接流入ResNet主网络。后者则增加了三个Batch Normalization层和三个3×3卷积层,其中卷积层起到了缓冲的作用,防止梯度对主网络影响太剧烈,保证网络的稳定性。
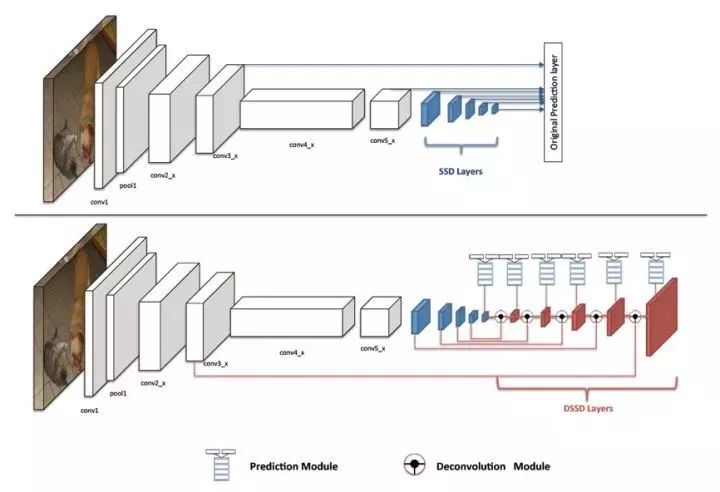
图2.7 SSD和DSSD网络结构对比
2.8 DSOD
2017年复旦大学提出DSOD算法,其并不是在mAP上和其他检测算法做比较,看谁的算法更有效或者速度更快,而是从另一个角度切入说明fine-tune和直接训练检测模型的差异其实是可以减小的,也就是说训练一个检测模型可以不需要大量的数据和预训练好的模型。
这是由于预训练模型的限制导致:迁移模型结构灵活性差,难以改变网络结构;分类任务预训练模型和检测任务训练会有学习偏差;虽然微调会减少不同目标类别分布的差异性,但深度图等特殊图像迁移效果差异较大。
SSD算法是在六个尺度的特征图上进行检测,将这六个检测结果综合起来,DSOD算法则则根据DenseNet的设计原理,将相邻的检测结果一半一半的结合起来。DSOD算法是基于SSD算法基础上做的修改,采用的特征提取网络是DenseNet。
采用Dense Block结构,能避免梯度消失的情况。同时利用Dense Prediction结构,也能大大减少模型的参数量,特征包含更多信息。设计stem结构能减少输入图片信息的丢失,stem结构由3×3卷积和2×2的max pool层组成,其还可以提高算法检测的mAP。
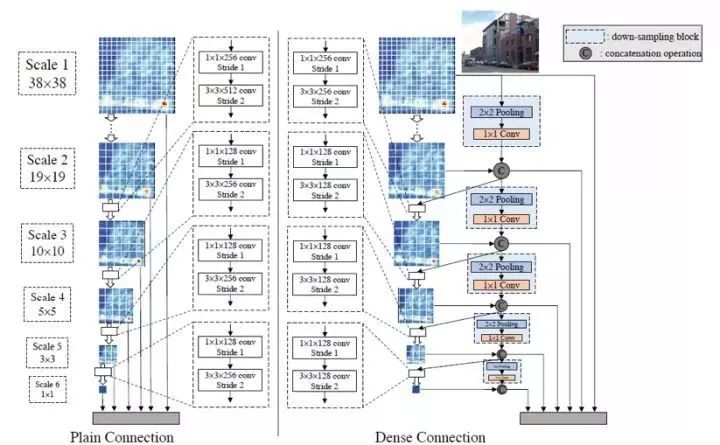
图2.8 DSOD预测层
2.9 RON
2017年清华大学提出了RON算法,结合two stage名的方法和one stage方法的优势,更加关注多尺度对象定位和负空间样本挖掘问题。
多尺度对象定位——各种尺度的物体可能出现在图像的任何位置,因此应考虑成千上万个具有不同位置/尺度/方位的区域。多尺度表征将显著改善各种尺度的物体检测,但是这些方法总是在网络的一层检测到各种尺度的对象;
负空间挖掘——对象和非对象样本之间的比例严重不平衡。因此,对象检测器应该具有有效的负挖掘策略。
RON算法通过设计方向连接结构,利用多尺度表征显著改善各种多尺度物体检测,同时为了减少对象搜索空间,在卷积特征图创建objectness prior引导目标对象搜索,训练时将检测器进行联合优化。并通过多任务损失函数联合优化了反向连接、objectness prior和对象检测,因此可直接预测各种特征图所有位置的最终检测结果。
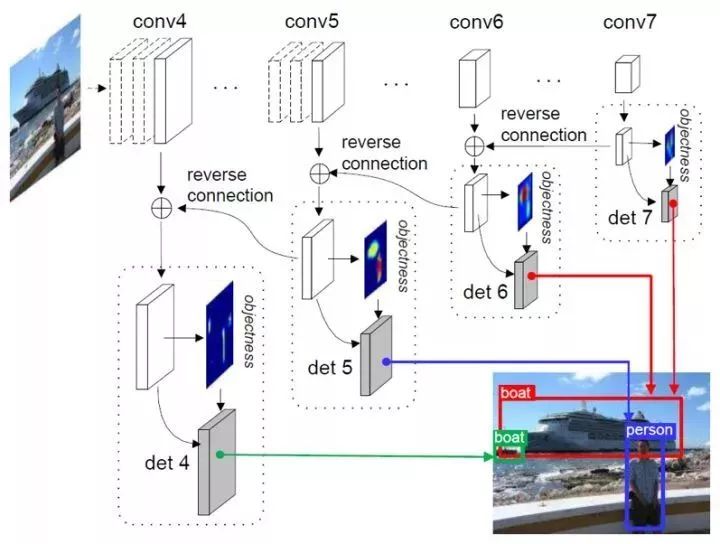
图2.9 RON
3. 总结
随着深度学习技术在图像各领域的研究深入,出现越来越多的新理论、新方法。two stage的方法和基于回归思想的one stage方法两者相互借鉴,不断融合,取得了很好的效果,也为我们展示了一些未来发展趋势:
参考上下文特征的多特征融合;
多尺度的对象定位;
结合循环神经网络(RNN)的图像语义分析。
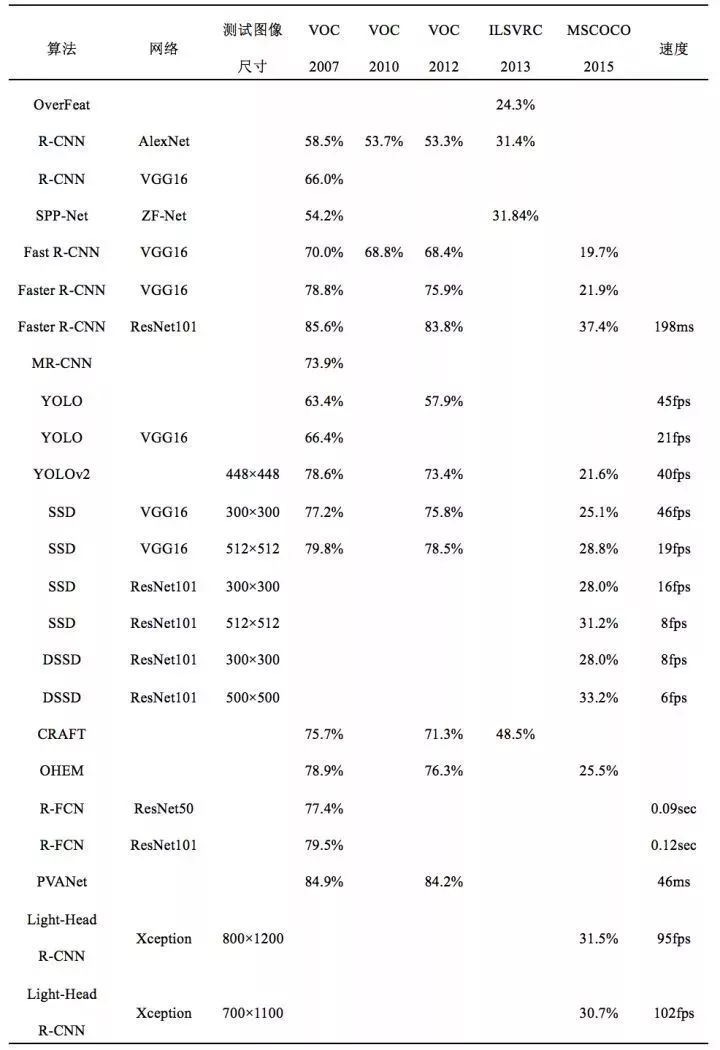
部分目标检测算法精度和速度对比
文章来源:知乎

《机器读心术之迁移学习》通过学习对于怎样在现实(一般不会是很理想)的数据状况下,实现人工智能产品和展开数据分析,具有清晰的思路和熟练技巧,从入门级的数据分析师,人工智能算法设计师,解决方案提供者迈向高阶,晋身数据科学家和企业人工智能技术带头人级别的专业人才队伍。点击下方二维码报名课程


