从Seq2seq到Attention模型到Self Attention(二)

传送门:
从Seq2seq到Attention模型到Self Attention(一)
——作者:Bgg——
系列一介绍了Seq2seq和 Attention model。这篇文章将重点摆在Google於2017年发表论文“Attention is all you need”中提出的 “”The transformer模型。”The transformer”模型中主要的概念有2项:1. Self attention 2. Multi-head,此外,模型更解决了传统attention model中无法平行化的缺点,并带来优异的成效。
前言
系列一中,我们学到attention model是如何运作的,缺点就是不能平行化,且忽略了输入句中文字间和目标句中文字间的关係。
为了解决此问题,2017年,Self attention诞生了。
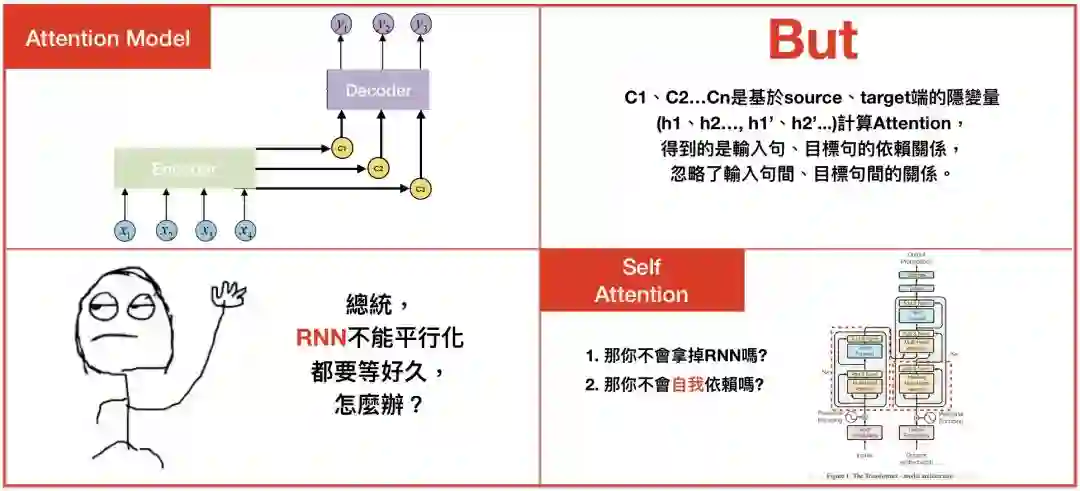
Self Attention
Self attention是Google在 “Attention is all you need”论文中提出的”The transformer”模型中主要的概念之一,我们可以把”The transformer”想成是个黑盒子,将输入句输入这个黑盒子,就会產生目标句。
最特别的地方是,”The transformer”完全捨弃了RNN、CNN的架构。

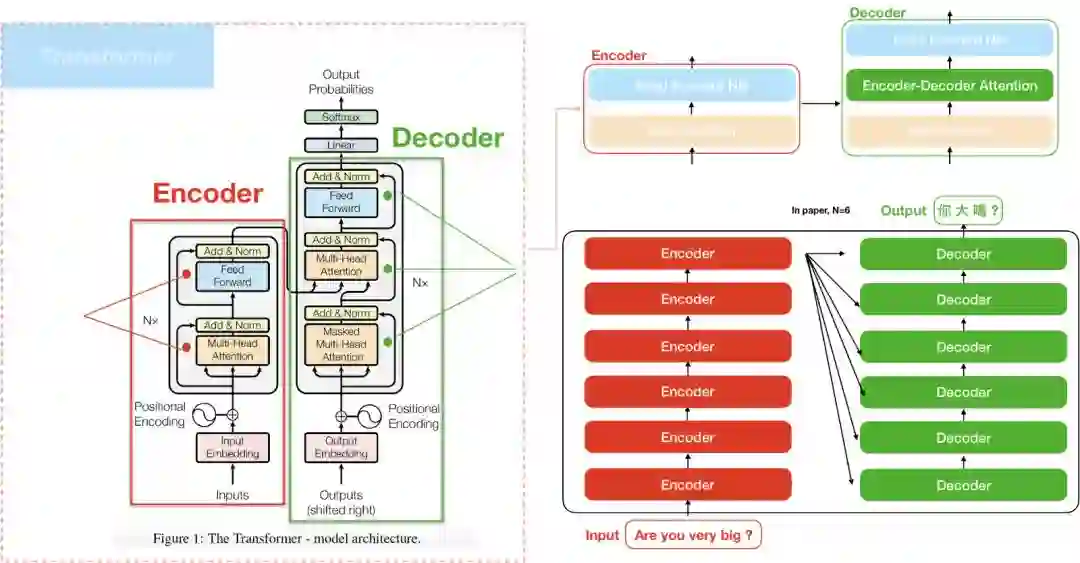
The transformer
“The transformer”和Seq2seq模型皆包含两部分:Encoder和Decoder。比较特别的是,”The transformer”中的Encoder是由6个Encoder堆积而成(paper当中N=6),Deocder亦然,这和过去的attention model只使用一个encoder/decoder是不同的。
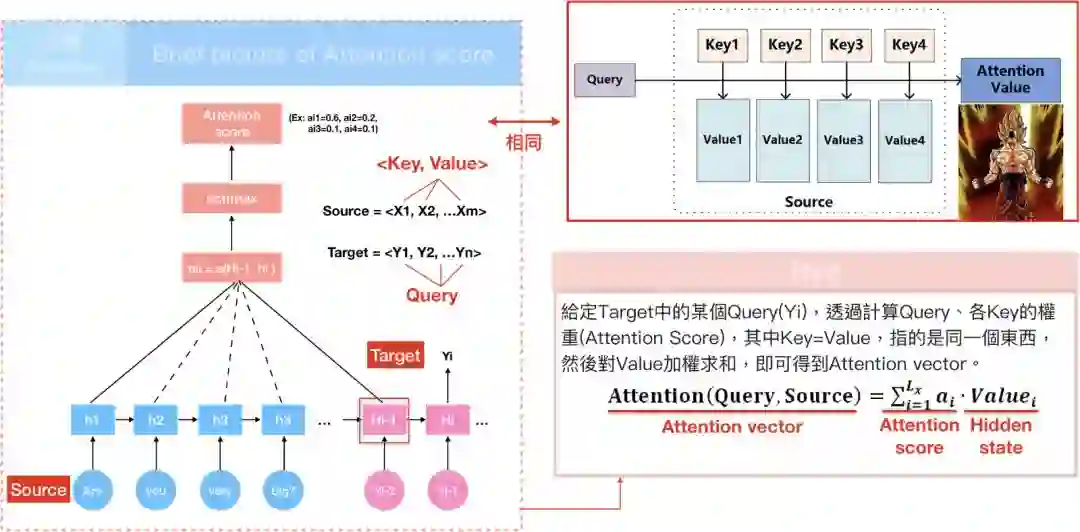
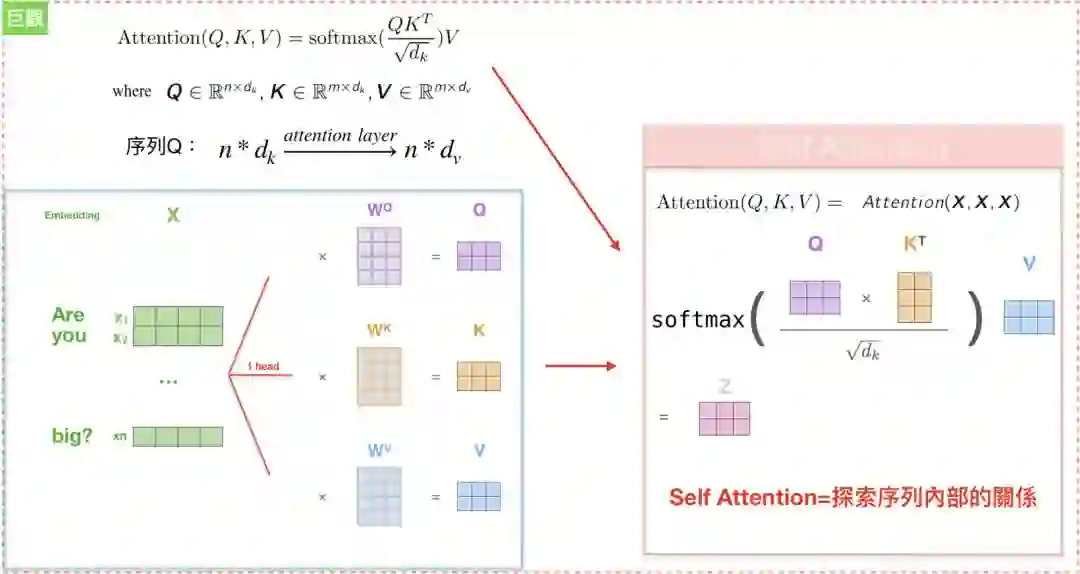
Query, Key, Value
进入”The transformer”前,我们重新复习attention model,attention model是从输入句<X1,X2,X3…Xm>產生h1,h2,h….hm的hidden state,透过attention score α 乘上input 的序列加权求和得到Context vector c_{i},有了context vector和hidden state vector,便可计算目标句<y1…yn>。换言之,就是将输入句作为input而目标句作为output。
如果用另一种说法重新詮释:
输入句中的每个文字是由一系列成对的 <地址Key, 元素Value>所构成,而目标中的每个文字是Query,那麼就可以用Key, Value, Query去重新解释如何计算context vector,透过计算Query和各个Key的相似性,得到每个Key对应Value的权重係数,权重係数代表讯息的重要性,亦即attention score;Value则是对应的讯息,再对Value进行加权求和,得到最终的Attention/context vector。
笔者认为这概念非常创新,特别是从attention model到”The transformer”间,鲜少有论文解释这种想法是如何连结的,间接导致”attention is all you need”这篇论文难以入门,有兴趣可以参考key、value的起源论文 Key-Value Memory Networks for Directly Reading Documents。
在NLP的领域中,Key, Value通常就是指向同一个文字隐向量(word embedding vector)。
有了Key, Value, Query的概念,我们可以将attention model中的Decoder公式重新改写。1. score e_{ij}= Similarity(Query, Key_{i}),上一篇有提到3种计算权重的方式,而我们选择用内积。2. 有了Similarity(Query, Key_{i}),便可以透过softmax算出Softmax(sim_{i})=a_{i},接著就可以透过attention score a_{i}乘上Value_{i}的序列和加总所得 = Attention(Query, Source),也就是context/attention vector。
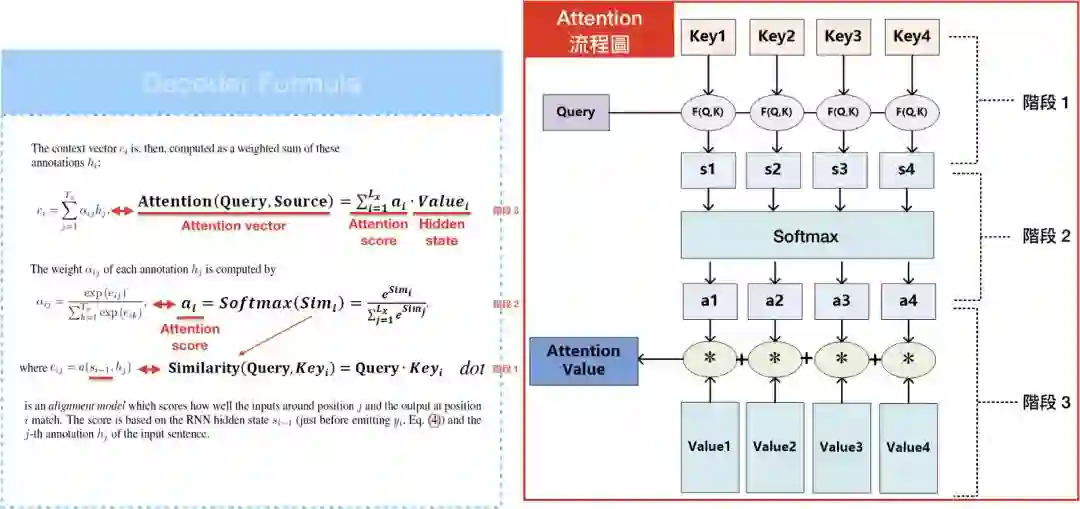
在了解Key, Value, Query的概念后,我们可以进入”the transformer”的世界了。
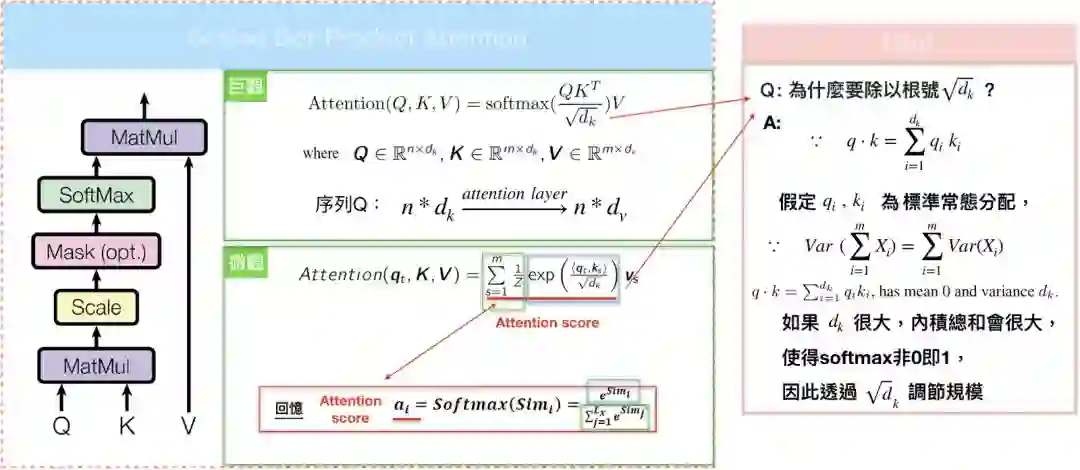
Scaled Dot-Product Attention
如果仔细观察,其实“The transformer”计算 attention score的方法和attention model如出一辙,但”The transformer”还要除上分母=根号d_{k},目的是避免内积过大时,softmax產出的结果非0即1。
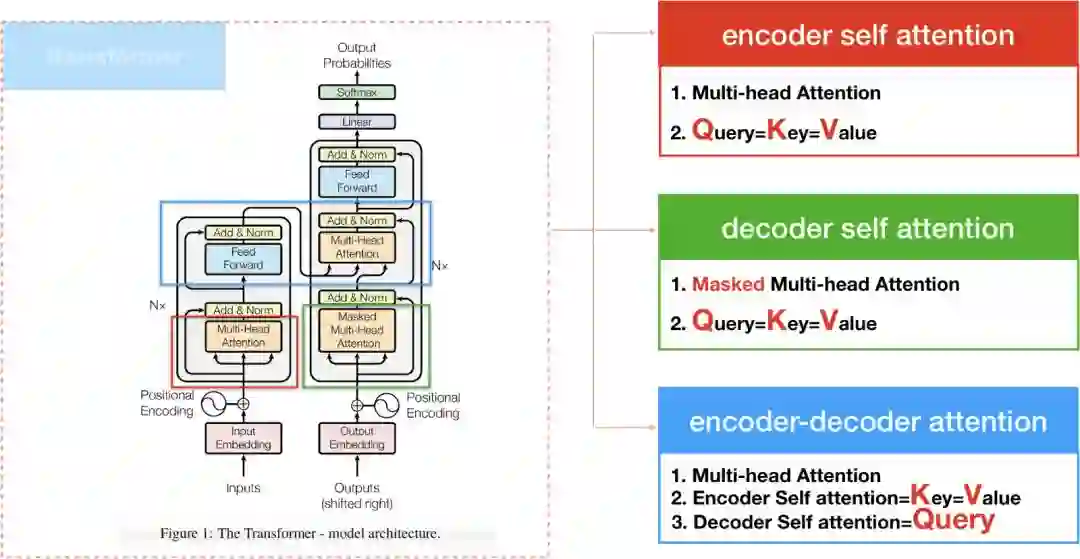
Three kinds of Attention
“The transformer”在计算attention的方式有三种,1. encoder self attention,存在於encoder间. 2. decoder self attention,存在於decoder间,3. encoder-decoder attention, 这种attention算法和过去的attention model相似。
接下来我们透过encoder和decoder两部份,来分别介绍encoder/decoder self attention。
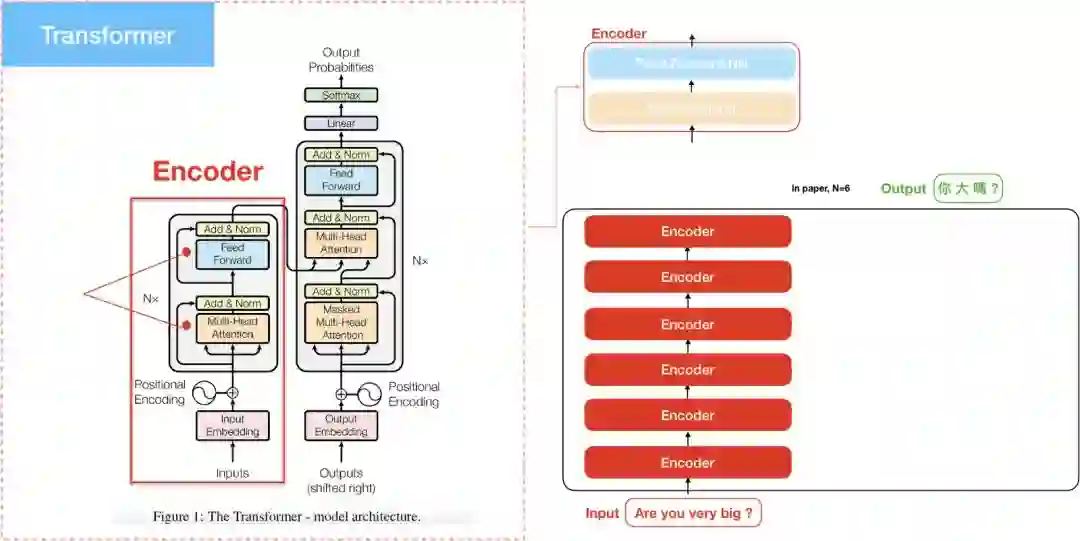
Encoder
我们将”The transformer”模型分为左右两部分,左边是Encoder,如前述,”Attention is all you need”当中N=6,代表Encoder部分是由6个encoder堆积而成的。其中在计算encoder self attention时,更透过multi-head的方式去学习不同空间的特徵,在后续内容会探讨multi-head的部分。
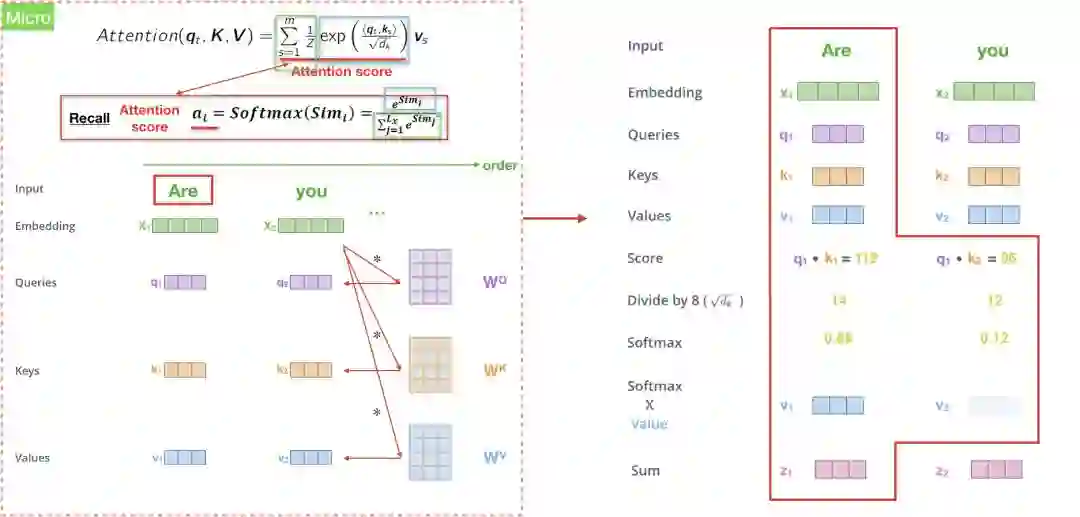
如何计算encoder self attention?
我们先用微观的角度来观察Attention(q_{t}, K, V),也就是输入句中的某个文字,再将所有输入句中的文字一次用矩阵Attention(Q,K,V)来解决。
第一步是创造三个encoder的输入向量Q,K,V,举例来说,“Are you very big?”中的每一个字的隐向量都有各自的Q,K,V,接著我们会乘上一个初始化矩阵,论文中输出维度d_{model}=512。
第二步是透过内积来计算score <q_{t}, k_{s}>,类似attention model 中的score e_{ij}。假设我们在计算第一个字”Are”的self-attention,我们可能会将输入句中的每个文字”Are”, ”you”, ‘very’, ‘big’分别和”Are”去做比较,这个分数决定了我们在encode某个特定位置的文字时,应该给予多少注意力(attention)。所以当我们在计算#位置1的self-attention,第一个分数是q1、k1的内积 (“Are vs Are”),第二个分数则是q1、k2 (“Are vs you”),以此类推。
第三步是将算出的分数除以根号d_{k},论文当中假定d_{k}=64,接著传递至exponential函数中并乘上1/Z,其实这结果就是attention/softmax score,我们可以把1/Z看成是softmax时,所除上的exponential总和,最终的总分数就是attention score,代表我们应该放多少注意力在这个位置上,也就是attention model的概念,有趣的是,怎麼算一定都会发现自己位置上的分数永远最高,但有时候可以发现和其他位置的文字是有关联的。
最后一步就是把attention score再乘上value,然后加总得到attention vector(z_{I}),这就是#位置1的attention vector z1,概念都和以往的attention model类似。
以上就是self-attention的计算,算出来的向量我们可以往前传递至feed-forward neural network,实际的运作上,是直接将每个文字同时处理,因此会变成一个矩阵,而非单一词向量,计算后的结果attention vector也会变成attention matrix Z。
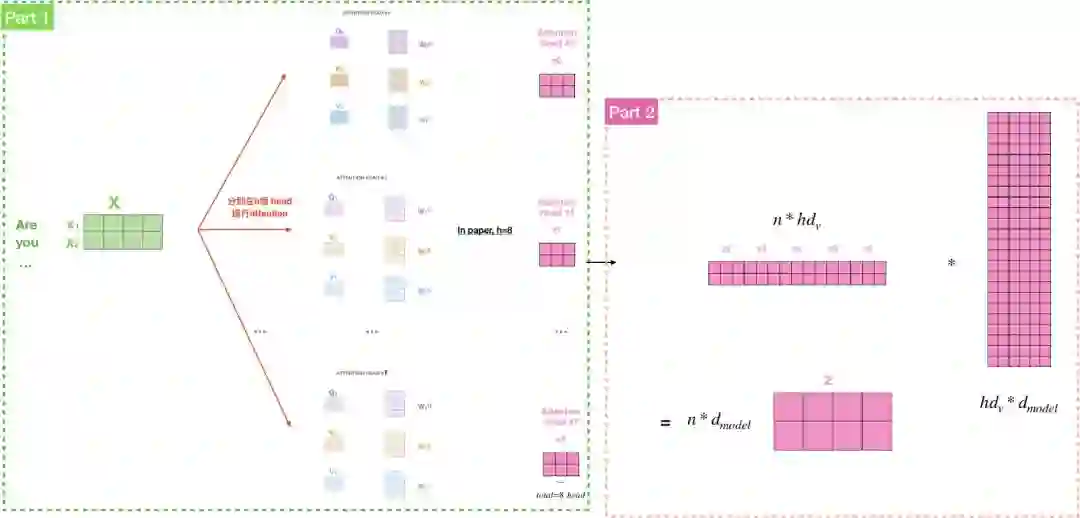
Multi-head attention
有趣的是,如果我们只计算一个attention,很难捕捉输入句中所有空间的讯息,为了优化模型,论文当中提出了一个新颖的做法:Multi-head attention,概念是不要只用d_{model}维度的key, value, query们做单一个attention,而是把key, value, query们线性投射到不同空间h次,分别变成维度d_{q}, d_{k} and d_{v},再各自做attention,其中,d_{k}=d_{v}=d_{model}/h=64,概念就是投射到h个head上。

此外,”The transformer”用了8个attention head,所以我们会產生8组encoder/decoder,每一组都代表将输入文字的隐向量投射到不同空间,如果我们重复计算刚刚所讲的self-attention,我们就会得到8个不同的矩阵Z,可是呢,feed-forward layer期望的是一个矩阵而非8个,所以我们要把这8个矩阵併在一起,透过乘上一个权重矩阵,还原成一个矩阵Z。
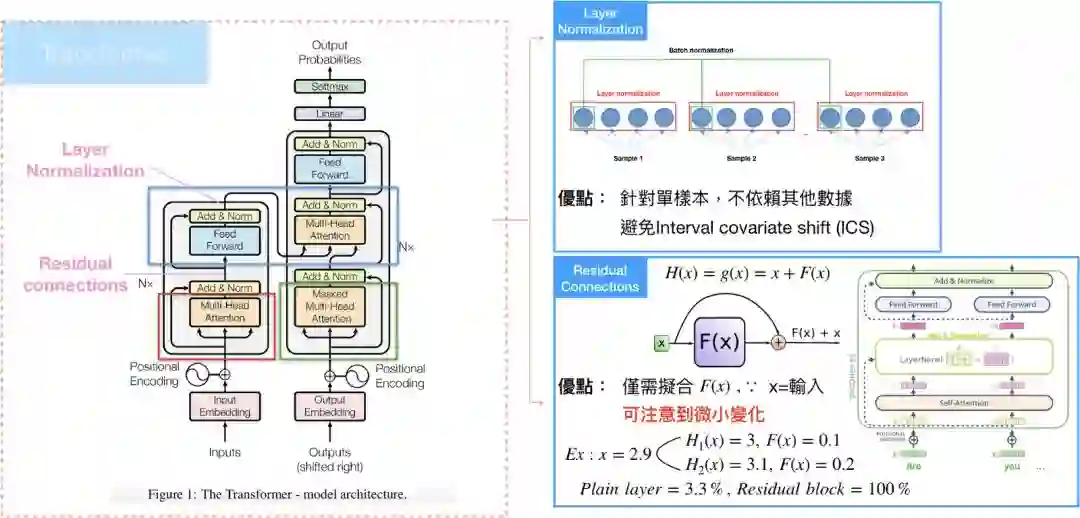
Residual Connections
Encoder还有一个特别的架构,Multihead-attention完再接到feed-forward layer中间,还有一个sub-layer,会需要经过residual connection和layer normalization。
Residual connection 就是构建一种新的残差结构,将输出改写成和输入的残差,使得模型在训练时,微小的变化可以被注意到,这种架构很常用在电脑视觉(computer vision),有兴趣可以参考神人Kaiming He的Deep Residual Learning for Image Recognition。
Layer normalization则是在深度学习领域中,其中一种正规化方法,最常和batch normalization进行比较,layer normalization的优点在於它是独立计算的,也就是针对单一样本进行正规化,batch normalization则是针对各维度,因此和batch size有所关联,可以参考layer normalization。
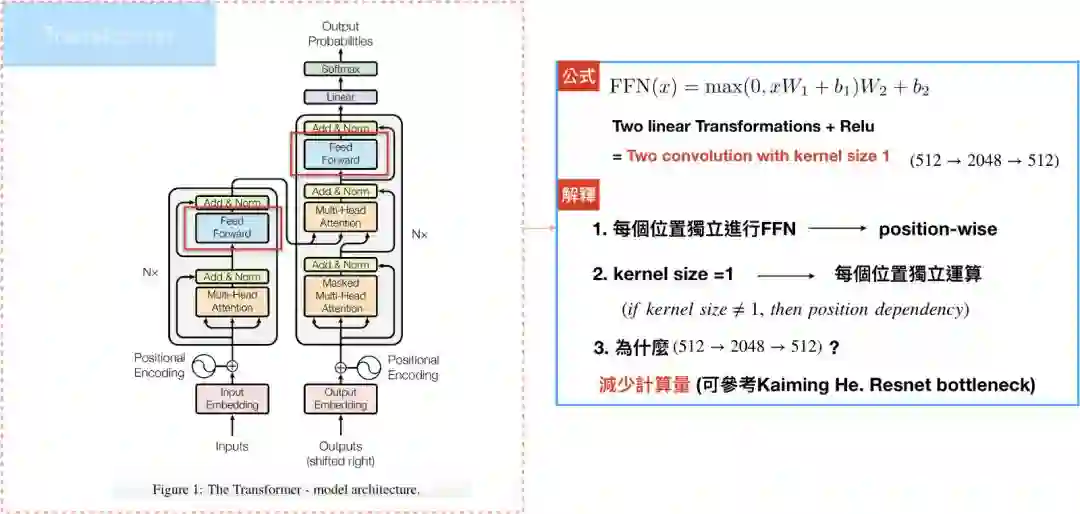
Position-wise Feed-Forward Networks
Encoder/Decoder中的attention sublayers都会接到一层feed-forward networks(FFN):两层线性转换和一个RELU,论文中是根据各个位置(输入句中的每个文字)分别做FFN,举例来说,如果输入文字是<x1,x2…xm>,代表文字共有m个。
其中,每个位置进行相同的线性转换,这边使用的是convolution1D,也就是kernel size=1,原因是convolution1D才能保持位置的完整性,可参考CNN,模型的输入/输出维度d_{model}=512,但中间层的维度是2048,目的是为了减少计算量,这部分一样参考神人Kaiming He的Deep Residual Learning for Image Recognition。
Positional Encoding
和RNN不同的是,multi-head attention不能学到输入句中每个文字的位置,举例来说,“Are you very big?” and “Are big very you?”,对multi-head而言,是一样的语句,因此,”The transformer”透过positional encoding,来学习每个文字的相对/绝对位置,最后再和输入句中文字的隐向量相加。
论文使用了方程式PE(pos, 2i)=sin(pos/10000^{2i/d_{model}})、PE(pos, 2i+1)=cos(pos/10000^{2i/d_{model}})来计算positional encoding,pos代表的是位置,i代表的是维度,偶数位置的文字会透过sin函数进行转换,奇数位置的文字则透过cos函数进行转换,藉由三角函数,可以发现positional encoding 是个有週期性的波长;举例来说,[pos+k]可以写成PE[pos]的线性转换,使得模型可以学到不同位置文字间的相对位置。
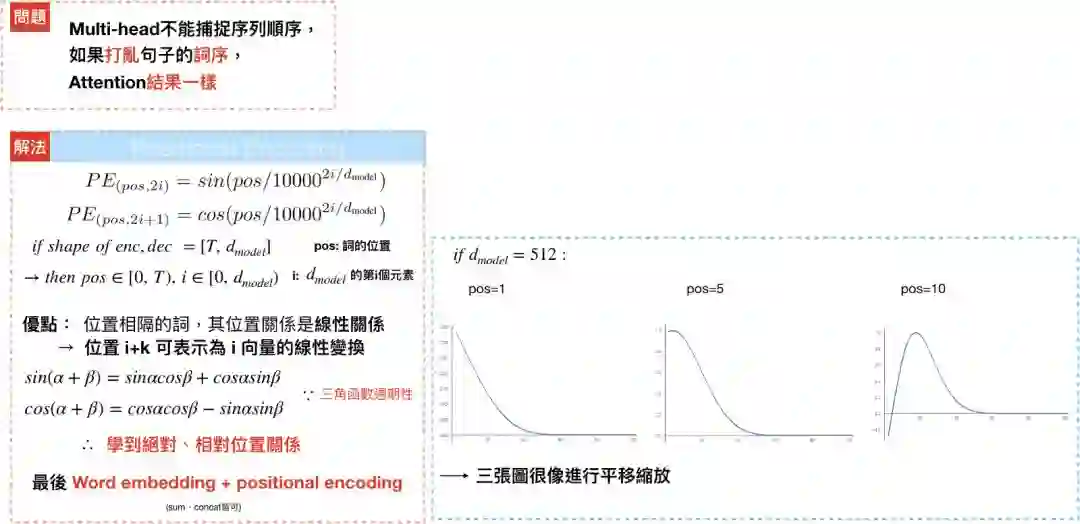
如下图,假设embedding 的维度为4:
每列对应的是经过positional encoding后的向量,以第一列而言,就是输入句中第一个文字隐向量和positioncal encoding后的向量和,所以每列维度都是d_{model},总共有pos列,也就是代表输入句中有几个文字。
下图为含有20字的输入句,文字向量维度为512,可以发现图层随著位置產生变化。
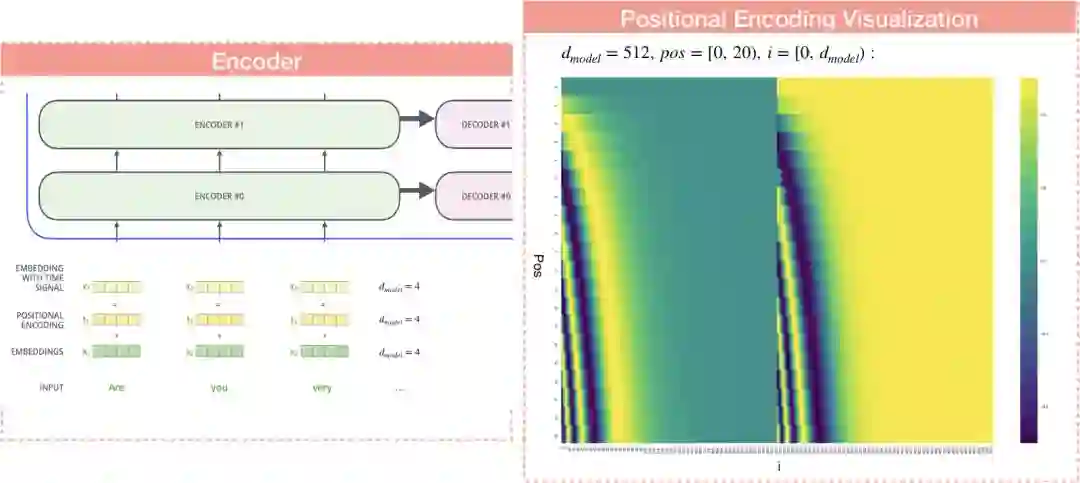
Encoder内容告一段落,接下来让我们看Decoder的运作模式。
Decoder
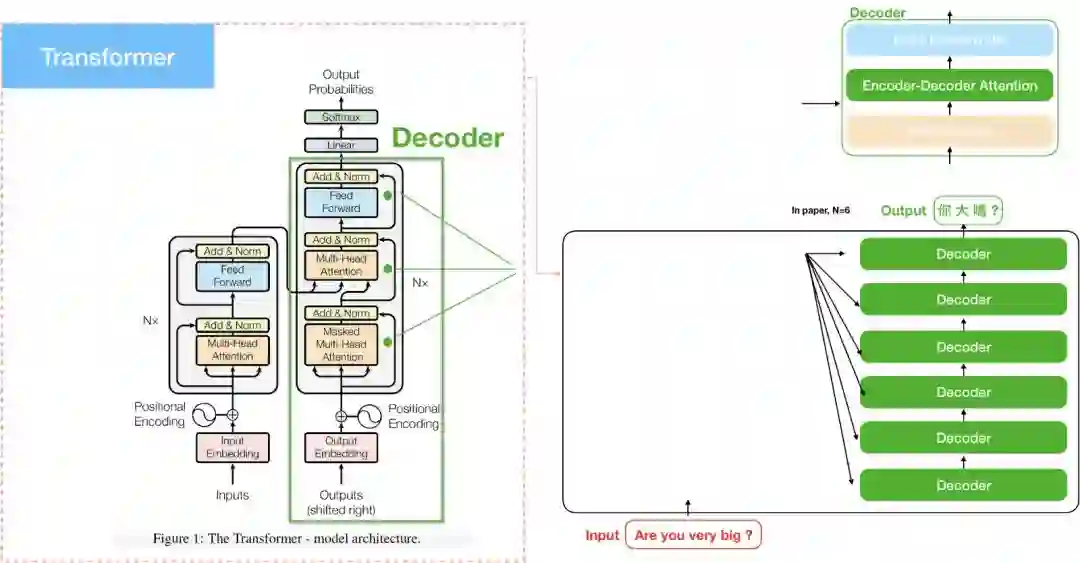
Masked multi-head attention
Decoder的运作模式和Encoder大同小异,也都是经过residual connections再到layer normalization。Encoder中的self attention在计算时,key, value, query都是来自encoder前一层的输出,Decoder亦然。
不同的地方是,为了避免在解码的时后,还在翻译前半段时,就突然翻译到后半段的句子,会在计算self-attention时的softmax前先mask掉未来的位置(设定成-∞)。这个步骤确保在预测位置i的时候只能根据i之前位置的输出,其实这个是因应Encoder-Decoder attention 的特性而做的配套措施,因为Encoder-Decoder attention可以看到encoder的整个句子,
Encoder-Decoder Attention
“Encoder-Decoder Attention”和Encoder/Decoder self attention不一样,它的Query来自於decoder self-attention,而Key、Value则是encoder的output。
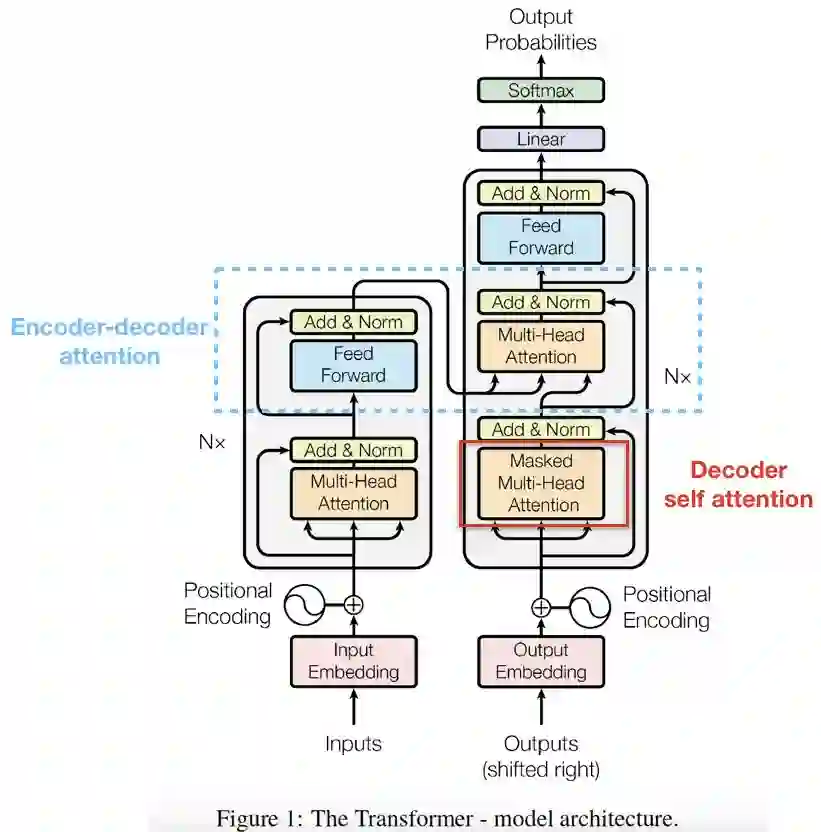
至此,我们讲完了三种attention,接著看整体运作模式。
从输入文字的序列给Encoder开始,Encoder的output会变成attention vectors的Key、Value,接著传送至encoder-decoder attention layer,帮助Decoder该将注意力摆在输入文字序列的哪个位置进行解码。
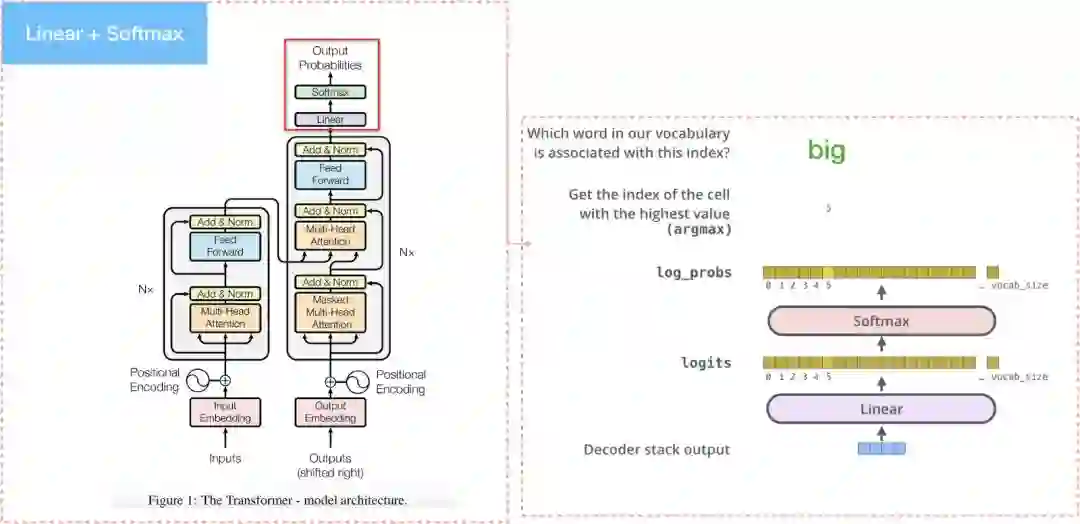
The Final Linear and Softmax Layer
Decoder最后会產出一个向量,传到最后一层linear layer后做softmax。Linear layer只是单纯的全连接层网络,并產生每个文字对应的分数,softmax layer会将分数转成机率值,最高机率的值就是在这个时间顺序时所要產生的文字。
Why self attention?
过去,Encoder和Decoder的核心架构都是RNN,RNN把输入句的文字序列 (x1…, xn)一个个有序地转成hidden encodings (h1…hn),接著在產出目标句的文字序列(y1…yn)。然而,RNN的序列性导致模型不可能平行计算,此外,也导致计算复杂度很高,而且,很难捕捉长序列中词语的依赖关係(long-range dependencies)。
透过 “the transformer”,我们可以用multi-head attention来解决平行化和计算复杂度过高的问题,依赖关係也能透过self-attention中词语与词语比较时,长度只有1的方式来克服。
Future
在金融业,企业可以透过客户歷程,深入了解客户行为企业,进而提供更好的商品与服务、提升客户满意度,藉此创造价值。然而,和以往的基本特徵不同,从序列化的客户歷程资料去萃取资讯是非常困难的,在有了self-attention的知识后,我们可以将这种处理序列资料的概念应用在复杂的客户歷程上,探索客户潜在行为背后无限的商机。
笔者也推荐有兴趣钻研self-attention概念的读者,可以参考阿里巴巴所提出的论文ATrank,此篇论文将self-attention应用在產品推荐上,并带来更好的成效。
参考
[1] Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translationr. arXiv:1406.1078v3 (2014).
[2] Sequence to Sequence Learning with Neural Networks. arXiv:1409.3215v3 (2014).
[3] Neural machine translation by joint learning to align and translate. arXiv:1409.0473v7 (2016).
[4] Effective Approaches to Attention-based Neural Machine Translation. arXiv:1508.0402v5 (2015).
[5] Convolutional Sequence to Sequence learning. arXiv:1705.03122v3(2017).
[6] Attention Is All You Need. arXiv:1706.03762v5 (2017).
[7] ATRank: An Attention-Based User Behavior Modeling Framework for Recommendation. arXiv:1711.06632v2 (2017).
[8] Key-Value Memory Networks for Directly Reading Documents. arXiv:1606.03126v2 (2016).
[9] Show, Attend and Tell: Neural Image Caption Generation with Visual Attention. arXiv:1502.03044v3 (2016).
[10] Deep Residual Learning for Image Recognition. arXiv:1512.03385v1 (2015).
[11] Layer Normalization. arXiv:1607.06450v1 (2016).
来源:
https://medium.com/@bgg/seq2seq-pay-attention-to-self-attention-part-1-d332e85e9aad
推荐阅读
知识在于分享
在量化投资的道路上
你不是一个人在战斗





