预训练与微调之间的差异能否缓解?来自北京邮电大学、腾讯、新加坡管理大学和鹏城实验室的研究者进行了分析研究,并提出了一种针对 GNN 的自监督预训练策略。
图神经网络(GNN)已经成为图表示学习的实际标准,它通过递归地聚集图邻域的信息来获得有效的节点表示。尽管 GNN 可以从头开始训练,但近来一些研究表明:对 GNN 进行预训练以学习可用于下游任务的可迁移知识能够提升 SOTA 性能。
但是,传统的 GNN 预训练方法遵循以下两个步骤:
1)在大量未标注数据上进行预训练;
2)在下游标注数据上进行模型微调。
由于这两个步骤的优化目标不同,因此二者存在很大的差距。
近日,
来自北京邮电大学和腾讯等机构的研究者进行了分析研究以显示预训练和微调之间的差异
。为了缓解这种差异,研究者提出了 L2PGNN,这是一种针对 GNN 的自监督预训练策略。
![]()
论文链接:https://yuanfulu.github.io/publication/AAAI-L2PGNN.pdf
该方法的关键点是 L2P-GNN 试图学习在预训练过程中以可迁移先验知识的形式进行微调。为了将局部信息和全局信息都编码为先验信息,研究者进一步为 L2P-GNN 设计了在节点和图级别双重适应(dual adaptation)的机制。最后研究者使用蛋白质图公开集合和书目图的新汇编进行预训练,对各种 GNN 模型的预训练进行了系统的实证研究。实验结果表明,L2P-GNN 能够学习有效且可迁移的先验知识,从而为下游任务提供强大的表示。
首次探索学习预训练 GNN,缓解了预训练与微调目标之间的差异,并且为预训练 GNN 提供了新视角。
针对节点与图级表示,该研究提出完全自监督的 GNN 预训练策略。
针对预训练 GNN,该研究建立了一个新型大规模书目图数据,并且在两个不同领域的数据集上进行了大量实验。实验表明,该研究提出的方法显著优于 SOTA 方法。
该研究首先提出了一个自监督 GNN 模型,在模型无关元学习(MAML)设置中学习图结构,然后是节点和图级双重适应,以模拟预训练过程中的微调。
L2P-GNN 的核心是学习预训练 GNN 以缓解预训练与微调过程之间的差距。具体来说,该方法可以表述为 MAML 的形式。为此,该研究将任务定义为从局部和全局角度捕获图中的结构和属性。然后,元学习先验就可以适应新的任务或图。
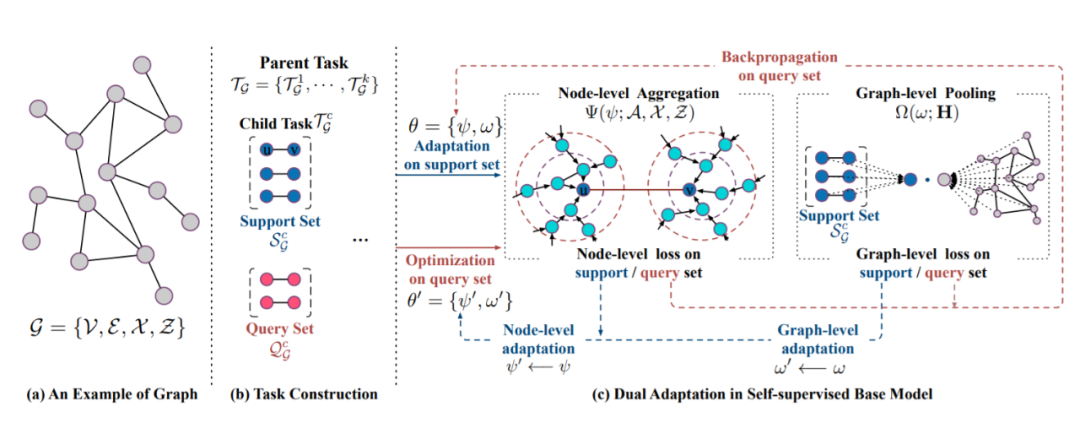
任务结构:将一组图作为预训练数据,
![]() ,任务
,任务
![]()
![]() 涉及的图
涉及的图
![]() 由支持集
由支持集
![]() 和查询集
和查询集
![]() 组成。
我们学习先验知识,通过梯度下降更新之后(与支持集上的损失有关),这可以优化查询集上的性能,从而模拟了微调步骤中的训练和测试。
组成。
我们学习先验知识,通过梯度下降更新之后(与支持集上的损失有关),这可以优化查询集上的性能,从而模拟了微调步骤中的训练和测试。
![]()
基础 GNN 模型:对于给出的父任务与子任务,该研究设计了一个具有节点级聚合和图级池化的自监督 GNN 模型,旨在将节点级和图级的无标签图数据的内在结构作为自监督信号。
为了缩小预训练和微调过程之间的差距,在预训练过程中优化模型快速适应新任务的能力是至关重要的。为此,该研究提出学习基础 GNN 模型的预训练,旨在学习可迁移的先验知识,提供可适应的初始化,以便快速针对具有新图数据的新型下游任务进行微调。具体而言,学习到的初始化不仅对节点对之间的局部连通性进行编码和调整,还能够泛化到图的不同子结构。相应地,该研究设计了节点和图级双重适应,如图 1(c) 所示。
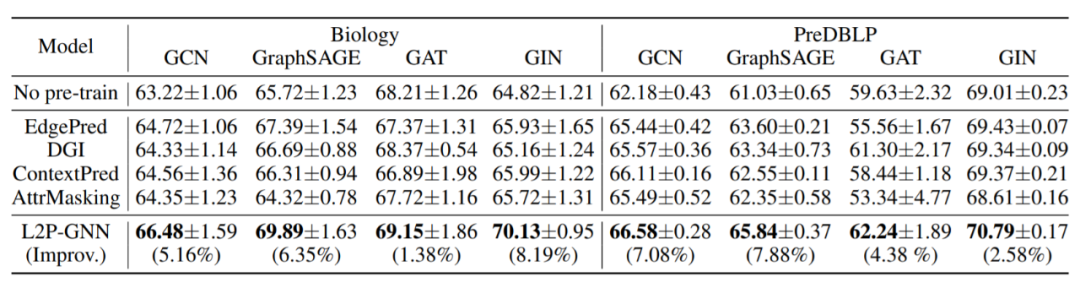
表 2 对比了 L2P-GNN 和 SOTA 预训练基线(4 种不同的 GNN 架构)的性能,得到了以下发现:
1. 总体而言,在跨架构的所有方法中,L2P-GNN 实现了 SOTA 性能。与每种架构的最佳基线相比,L2P-GNN 在两个数据集上分别实现了高达 6.27% 和 3.52% 的提升。研究者认为这么大的性能提升归功于预训练过程中的微调模拟,缩小了预训练和微调目标之间的差距。
2. 此外,使用大量未标注数据对 GNN 进行预训练显然对下游任务有所帮助。因为相比于在两个数据集上未经过预训练的模型,L2P-GNN 分别带来了 8.19% 和 7.88% 的增益。
3. 研究者还注意到,一些基线(即使用 EdgePred 和 AttrMasking 策略的 GAT 模型)在下游任务中的性能提升极为有限,并在下游任务上产生了负迁移。原因可能是这些策略学习的信息与下游任务无关,因而不利于预训练 GNN 的泛化。这一发现证实了先前的观察结果,即负迁移会限制预训练模型的使用性和可靠性。
![]()
表 2:在不同 GNN 架构下,不同预训练策略的实验结果。这些性能提升是相对于未经预训练的 GNN 而言的。
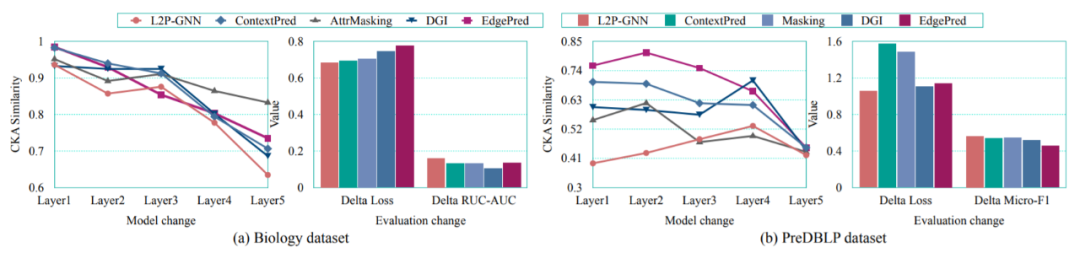
如图 2 所示,微调前后 L2P-GNN 参数的 CKA 相似性通常小于基线,这表明 L2P-GNN 经历了更大的变化,从而更加适应下游任务。
![]()
图 2:GIN 层 CKA 相似性和在两个数据集上的损失及性能变化。
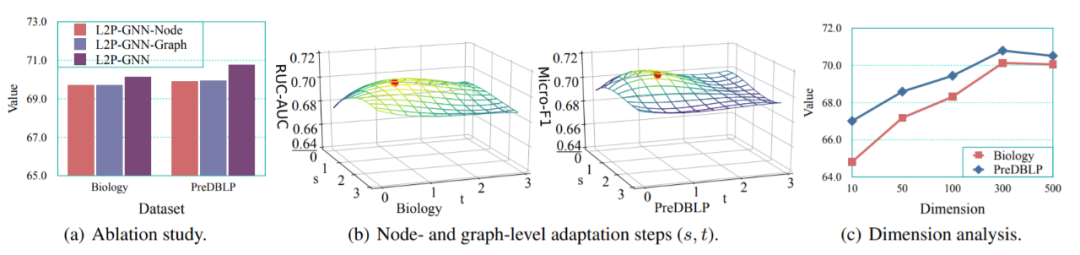
此外,由于节点、图级双重适应在 L2P-GNN 中非常重要,该研究比较了两种变体:L2P-GNN-Node(只有节点级适应)和 L2P-GNN-Graph(只有图级适应)。如图 3(a) 所示,在两个数据集上的结果表明 L2P-GNN 优于这两个变体。这说明,局部节点级结构和全局图级信息都是有用的,有利于进行联合建模。
![]()
该论文研究了节点、图级适应步幅数 (s, t) 和节点表示维度的影响。图 3(b) 绘制了 L2P-GNN 在 0 ≤ s ≤ 3 和 0 ≤ t ≤ 3 下的性能。
最后,该研究总结了维度的影响如图 3(c) 所示。当维度在 300 维时,L2P-GNN 性能达到最优,并且在最优设置附近基本稳定,这说明 L2P-GNN 在维度表示方面具有鲁棒性。
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
![]()
专知,专业可信的人工智能知识分发,让认知协作更快更好!欢迎注册登录专知www.zhuanzhi.ai,获取5000+AI主题干货知识资料!
欢迎微信扫一扫加入专知人工智能知识星球群,获取最新AI专业干货知识教程资料和与专家交流咨询!
点击“
阅读原文
”,了解使用
专知
,查看获取5000+AI主题知识资源

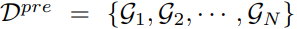 ,任务
,任务
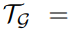
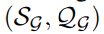 涉及的图
涉及的图
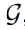 由支持集
由支持集
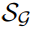 和查询集
和查询集
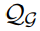 组成。
我们学习先验知识,通过梯度下降更新之后(与支持集上的损失有关),这可以优化查询集上的性能,从而模拟了微调步骤中的训练和测试。
组成。
我们学习先验知识,通过梯度下降更新之后(与支持集上的损失有关),这可以优化查询集上的性能,从而模拟了微调步骤中的训练和测试。