人工神经网络在解决特定刚性任务的分类问题时,通过不同训练阶段的广义学习行为获取知识。由此产生的网络类似于一个静态的知识实体,努力扩展这种知识而不针对最初的任务,从而导致灾难性的遗忘。
持续学习将这种范式转变为可以在不同任务上持续积累知识的网络,而不需要从头开始再训练。我们关注任务增量分类,即任务按顺序到达,并由清晰的边界划分。我们的主要贡献包括:
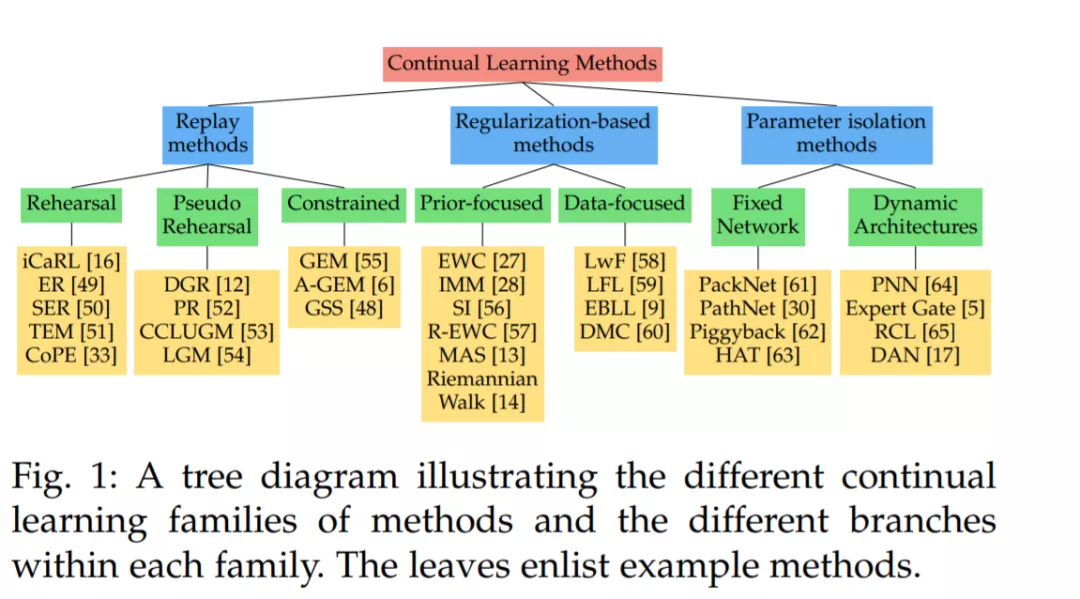
(1) 对持续学习技术的分类和广泛的概述;
(2) 一个持续学习器稳定性-可塑性权衡的新框架;
(3) 对11种最先进的持续学习方法和4条基准进行综合实验比较。
考虑到微型Imagenet和大规模不平衡的非自然主义者以及一系列识别数据集,我们以经验的方式在三个基准上仔细检查方法的优缺点。我们研究了模型容量、权重衰减和衰减正则化的影响,以及任务呈现的顺序,并从所需内存、计算时间和存储空间等方面定性比较了各种方法。
https://www.zhuanzhi.ai/paper/c90f25024b2c2364ce63299b4dc4677f
引言
近年来,据报道,机器学习模型在个人任务上表现出甚至超过人类水平的表现,如雅达利游戏[1]或物体识别[2]。虽然这些结果令人印象深刻,但它们是在静态模型无法适应其行为的情况下获得的。因此,这需要在每次有新数据可用时重新启动训练过程。在我们的动态世界中,这种做法对于数据流来说很快就变得难以处理,或者可能由于存储限制或隐私问题而只能暂时可用。这就需要不断适应和不断学习的系统。人类的认知就是这样一个系统的例证,它具有顺序学习概念的倾向。通过观察例子来重新审视旧的概念可能会发生,但对保存这些知识来说并不是必要的,而且尽管人类可能会逐渐忘记旧的信息,但完全丢失以前的知识很少被证明是[3]。相比之下,人工神经网络则不能以这种方式学习:在学习新概念时,它们会遭遇对旧概念的灾难性遗忘。为了规避这一问题,人工神经网络的研究主要集中在静态任务上,通常通过重组数据来确保i.i.d.条件,并通过在多个时期重新访问训练数据来大幅提高性能。
持续学习研究从无穷无尽的数据流中学习的问题,其目标是逐步扩展已获得的知识,并将其用于未来[4]的学习。数据可以来自于变化的输入域(例如,不同的成像条件),也可以与不同的任务相关联(例如,细粒度的分类问题)。持续学习也被称为终身学习[18]0,[18]1,[18]2,[18]3,[18]5,[18]4,顺序学习[10],[11],[12]或增量学习[13],[14],[15],[16],[17],[18],[19]。主要的标准是学习过程的顺序性质,只有一小部分输入数据来自一个或几个任务,一次可用。主要的挑战是在不发生灾难性遗忘的情况下进行学习:当添加新的任务或域时,之前学习的任务或域的性能不会随着时间的推移而显著下降。这是神经网络中一个更普遍的问题[20]的直接结果,即稳定性-可塑性困境,可塑性指的是整合新知识的能力,以及在编码时保持原有知识的稳定性。这是一个具有挑战性的问题,不断学习的进展使得现实世界的应用开始出现[21]、[22]、[23]。
为了集中注意力,我们用两种方式限制了我们的研究范围。首先,我们只考虑任务增量设置,其中数据按顺序分批到达,一个批对应一个任务,例如要学习的一组新类别。换句话说,我们假设对于一个给定的任务,所有的数据都可以同时用于离线训练。这使得对所有训练数据进行多个时期的学习成为可能,反复洗刷以确保i.i.d.的条件。重要的是,无法访问以前或将来任务的数据。在此设置中优化新任务将导致灾难性的遗忘,旧任务的性能将显著下降,除非采取特殊措施。这些措施在不同情况下的有效性,正是本文所要探讨的。此外,任务增量学习将范围限制为一个多头配置,每个任务都有一个独占的输出层或头。这与所有任务共享一个头的更有挑战性的类增量设置相反。这在学习中引入了额外的干扰,增加了可供选择的输出节点的数量。相反,我们假设已知一个给定的样本属于哪个任务。
其次,我们只关注分类问题,因为分类可以说是人工神经网络最既定的任务之一,使用相对简单、标准和易于理解的网络体系结构具有良好的性能。第2节对设置进行了更详细的描述,第7节讨论了处理更一般设置的开放问题。