百度PaddlePaddle开源视频分类模型Attention Cluster,曾夺挑战赛冠军
机器之心发布
百度PaddlePaddle
百度深度学习框架 PaddlePaddle 最近开源了用于视频分类的 Attention Cluster 模型。由于拥有卓越的分类能力,它曾助力百度计算机视觉团队夺取了 ActivityNet Kinetis Challenge 2017 挑战赛的冠军。该模型通过带 Shifting operation 的 Attention clusters,处理经过 CNN 模型抽取特征的视频的 RGB、光流、音频等数据,实现视频分类。
Attention Cluster 模型
视频分类问题在视频标签、监控、自动驾驶等领域有着广泛的应用,但它同时也是计算机视觉领域面临的一项重要挑战之一。
目前的视频分类问题大多是基于 CNN 或者 RNN 网络实现的。众所周知,CNN 在图像领域已经发挥了重大作用。它具有很好的特征提取能力,通过卷积层和池化层,可以在图像的不同区域提取特征。RNN 则在获取时间相关的特征方面有很强的能力。
Attention Cluster 在设计上仅利用了 CNN 模型,而没有使用 RNN,主要是基于视频的以下几个特点考虑:

图 1 视频帧的分析
首先,一段视频的连续帧常常有一定的相似性。在图 1(上)可以看到,除了击球的动作以外,不同帧几乎是一样的。因此,对于分类,可能从整体上关注这些相似的特征就足够了,而没有必要去特意观察它们随着时间的细节变化。
其次,视频帧中的局部特征有时就足够表达出视频的类别。比如图 1(中),通过一些局部特征,如牙刷、水池,就能够分辨出『刷牙』这个动作。因此,对于分类问题,关键在于找到帧中的关键的局部特征,而非去找时间上的线索。
最后,在一些视频的分类中,帧的时间顺序对于分类不一定是重要的。比如图 1(下),可以看到,虽然帧顺序被打乱,依然能够看出这属于『撑杆跳』这个类别。
基于以上考虑,该模型没有考虑时间相关的线索,而是使用了 Attention 机制。它有以下几点好处:
1. Attention 的输出本质上是加权平均,这可以避免一些重复特征造成的冗余。
2. 对于一些局部的关键特征,Attention 能够赋予其更高的权重。这样就能够通过这些关键的特征,提高分类能力。
3. Attention 的输入是任意大小的无序集合。无序这点满足我们上面的观察,而任意大小的输入又能够提高模型的泛化能力。
当然,一些视频的局部特征还有一个特点,那就是它可能会由多个部分组成。比如图 1(下)的『撑杆跳』,跳、跑和着陆同时对这个分类起到作用。因此,如果只用单一的 Attention 单元,只能获取视频的单一关键信息。而如果使用多个 Attention 单元,就能够提取更多的有用信息。于是,Attention Cluster 就应运而生了!在实现过程中,百度计算机视觉团队还发现,将不同的 Attention 单元进行一次简单有效的『位移操作』(shifting operation),可以增加不同单元的多样性,从而提高准确率。
接下来我们看一下整个 Attention Cluster 的结构。
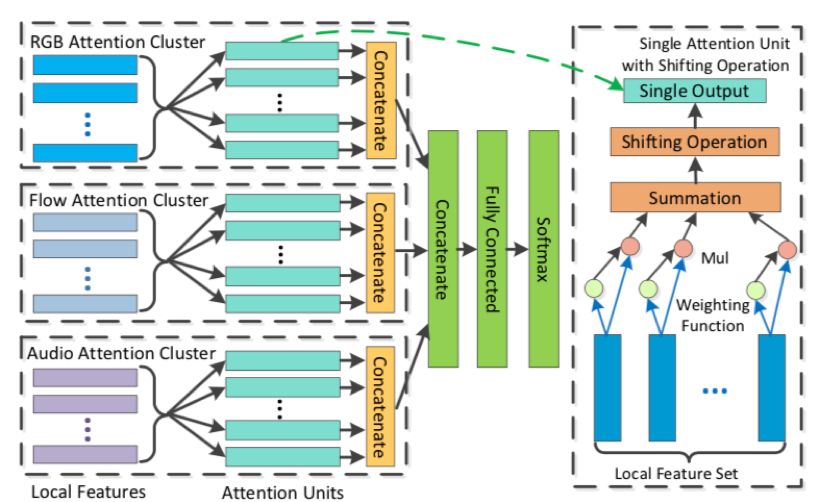
图 2 Attention Cluster 的模型结构
整个模型可以分为三个部分:
1. 局部特征提取。通过 CNN 模型抽取视频的特征。提取后的特征用 X 表示,如公式(1)所示: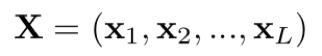
2. 局部特征集成。基于 Attention 来获取全局特征。Attention 的输出本质上相当于做了加权平均。如公式(2)所示,v 是一个 Attention 单元输出的全局特征,a 是权重向量,由两层全连接层组成,如公式(3)所示。实际实现中,v 的产生使用了 Shifting operation,如公式(4)所示,其中α和β是可学习的标量。它通过对每一个 Attention 单元的输出添加一个独立可学习的线性变换处理后进行 L2-normalization,使得各 Attention 单元倾向于学习特征的不同成分,从而让 Attention Cluster 能更好地学习不同分布的数据,提高整个网络的学习表征能力。由于采用了 Attention clusters,这里会将各个 Attention 单元的输出组合起来,得到多个全局特征 g,如公式(5)所示。N 代表的是 clusters 的数量。
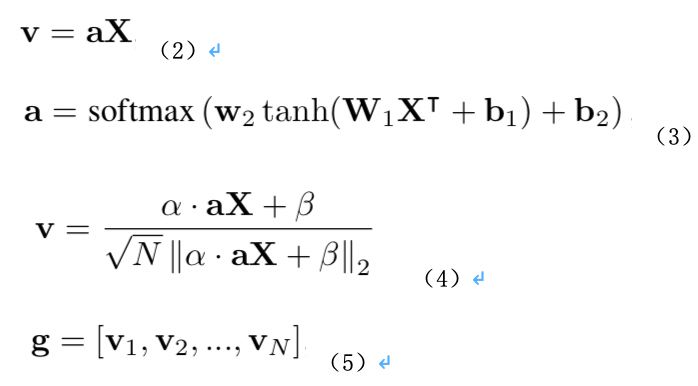
3. 全局特征分类。将多个全局特征拼接以后,再通过常规的全连接层和 Softmax 或 Sigmoid 进行最后的单标签或多标签分类。
用 PaddlePaddle 训练 Attention Cluster
PaddlePaddle 开源的 Attention Cluster 模型,使用了 2nd-Youtube-8M 数据集。该数据集已经使用了在 ImageNet 训练集上 InceptionV3 模型对特征进行了抽取。
如果运行该模型的样例代码,要求使用 PaddlePaddle Fluid V1.2.0 或以上的版本。
数据准备:首先请使用 Youtube-8M 官方提供的链接下载训练集和测试集,或者使用官方脚本下载。数据下载完成后,将会得到 3844 个训练数据文件和 3844 个验证数据文件(TFRecord 格式)。为了适用于 PaddlePaddle 训练,需要将下载好的 TFRecord 文件格式转成了 pickle 格式,转换脚本请使用 PaddlePaddle 提供的脚本 dataset/youtube8m/tf2pkl.py。
训练集:http://us.data.yt8m.org/2/frame/train/index.html
测试集:http://us.data.yt8m.org/2/frame/validate/index.html
官方脚本:https://research.google.com/youtube8m/download.html
模型训练:数据准备完毕后,通过以下方式启动训练(方法 1),同时我们也提供快速启动脚本 (方法 2)
# 方法 1
python train.py --model-name=AttentionCluster
--config=./configs/attention_cluster.txt
--save-dir=checkpoints
--log-interval=10
--valid-interval=1
# 方法 2
bash scripts/train/train_attention_cluster.sh
用户也可下载 Paddle Github 上已发布模型通过--resume 指定权重存放路径进行 finetune 等开发。
数据预处理说明: 模型读取 Youtube-8M 数据集中已抽取好的 rgb 和 audio 数据,对于每个视频的数据,均匀采样 100 帧,该值由配置文件中的 seg_num 参数指定。
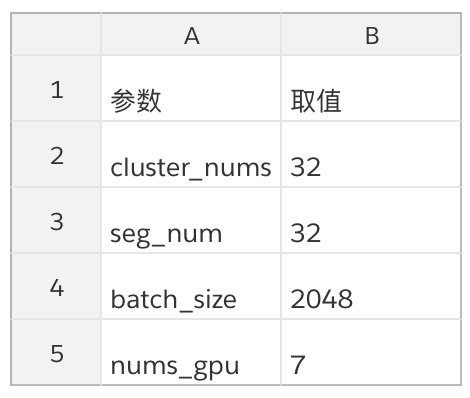
模型设置: 模型主要可配置参数为 cluster_nums 和 seg_num 参数。其中 cluster_nums 是 attention 单元的数量。当配置 cluster_nums 为 32, seg_num 为 100 时,在 Nvidia Tesla P40 上单卡可跑 batch_size=256。
训练策略:
采用 Adam 优化器,初始 learning_rate=0.001
训练过程中不使用权重衰减
参数主要使用 MSRA 初始化
模型评估:可通过以下方式(方法 1)进行模型评估,同样我们也提供了快速启动的脚本(方法 2):
# 方法 1
python test.py --model-name=AttentionCluster
--config=configs/attention_cluster.txt
--log-interval=1
--weights=$PATH_TO_WEIGHTS
# 方法 2
bash scripts/test/test_attention_cluster.sh
使用 scripts/test/test_attention_cluster.sh 进行评估时,需要修改脚本中的--weights 参数指定需要评估的权重。
若未指定--weights 参数,脚本会下载已发布模型进行评估
模型推断:可通过如下命令进行模型推断:
python infer.py --model-name=attention_cluster
--config=configs/attention_cluster.txt
--log-interval=1
--weights=$PATH_TO_WEIGHTS
--filelist=$FILELIST
模型推断结果存储于 AttentionCluster_infer_result 中,通过 pickle 格式存储。
若未指定--weights 参数,脚本会下载已发布模型 model 进行推断
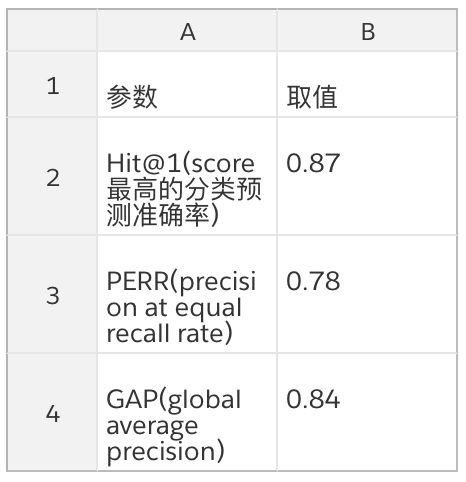
模型精度:当模型取如下参数时,在 Youtube-8M 数据集上的指标为:
参数取值:
评估精度:
传送门:
PaddlePaddle Github: https://github.com/PaddlePaddle
Attention Cluster in PaddlePaddle Github:https://github.com/PaddlePaddle/models/tree/develop/fluid/PaddleCV/video/models/attention_cluster
Reference:Xiang Long, Chuang Gan, Gerard de Melo, Jiajun Wu, Xiao Liu, Shilei Wen, Attention Clusters: Purely Attention Based Local Feature Integration for Video Classification
https://arxiv.org/abs/1711.09550
本文为机器之心发布,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com




