论文笔记之Meta-Tracker(ECCV2018)
作者1:Eunbyung Park
Alexander C. Berg的博士生
主页: http://www.cs.unc.edu/~eunbyung/
作者2:Alexander C. Berg
北卡罗来纳大学教堂山分校的副教授
主页: http://acberg.com/
SSD的作者之一
该论文发表于ECCV2018
The code, raw results and pretrained models are available at
https://github.com/silverbottlep/meta_trackers
论文地址:
https://arxiv.org/pdf/1801.03049.pdf
本文通过一个离线的meta-learning-based method来改善采用在线适应的先进跟踪器,从而能够对未来帧中特定的目标进行快速稳健建模。作者在两个先进跟踪器(MDNet、CREST)上验证了所提出方法的有效性。
理想情况下,要实现对未来帧中的特定目标进行快速稳健建模,那么所构建的模型应该关注对未来帧有用的特征,并避免对背景杂乱、目标的局部或者噪声过拟合。
关于meta-learning的介绍可以查看博客:
https://blog.csdn.net/qq_33778339/article/details/80835914
PS:作者标注转载,但是没有原文链接,我找到的原文也只是其中一部分,应该该博客是其他两篇的和?总之觉得这个还不错,若有不当之处,请联系,可删除。
介绍
跟踪是这样一个任务,在第一帧用边界框给出要跟踪的目标,跟踪算法能够在随后的帧中准确定位目标。
相比于检测和分类任务,在跟踪任务中,实例级别的判别是一个很重要的因素,什么意思呢?在检测或者分类中要检测/分类一个人,只要把人检测/分类出来就好了,不需要区分是不是同一个人;而在跟踪中,假设要跟踪一个人,在随后帧中不仅要准确的定位到一个人,并且这个人还必须是在第一帧边界框框出来的那个人。
并且跟踪模型还应该考虑由于视角变化、遮挡、形变造成的目标表观的变化。
解决这些挑战的一个方法就是采用在线适应。比如说DCF类算法,或者说基于二值分类器的算法,这些算法除了在序列的第一帧对模型进行初始化以外,在随后的帧中也对模型进行更新,以适应目标表观的变化。深度表示出现以后,现在顶级的跟踪器利用深度特征和在线更新方法进行跟踪。虽然使用深度方法的离线跟踪器速度快性能好,但是与在线适应跟踪器的精确度相比还是有一定差距的,这可能是因为离线跟踪器很难很好的区分视频中特定的实例。
联合深度特征和在线适应的普遍做法是在深度特征之上训练一个目标模型。深度特征是在一个大规模数据集上预训练得到的,被证明其表示能力很强且表示范围也很广,因此能够识别许多普通目标,使得关注特定实例的目标模型的有效训练成为可能。虽然这类方法到目前为止展现出了很好的跟踪结果,但是仍旧存在几个重要的问题需要被解决:
1. 仅能够得到很少的训练样本。虽然后续帧中也会收集样本,但是会有很多冗余,因为本质上来讲还是相同的目标和背景。另外,最近的趋势是为目标表观构建深度模型,众所周知,深度模型在小数据集上极易过拟合,因此为目标表观构建深度模型非常具有挑战性。这会导致训练得到的深度模型很容易对背景杂乱,目标特征的一小部分或者噪声过拟合。
2. 许多先进跟踪器在初始训练阶段需要花费大量的时间,而对许多实际应用而言,实时性是很重要的。另一方面,初始目标模型如果不充分的进行训练也可能影响模型的性能,最坏的情况就是模型不起作用。因此,高度希望在初始帧快速的获得稳健的目标模型。
本文从学习如何获得目标模型的角度来解决这个问题,关键的想法就是以一种可以很好的概括未来帧的方式训练一个目标模型。
之前的工作都是在当前帧最小化损失函数来训练网络。即便网络达到一个最优解,也不意味着其可以很好的适用于未来帧。作者建议使用来自未来帧的错误信号。在meta-learning 阶段,试图找到一种通用的初始表示和梯度方向,使得目标模型关注对未来有用的特征;meta-learning帮助目标模型避免过拟合于当前帧中的干扰者;通过强制模型在meta-training中更新,可以让得到的模型能够明显快速初始化。
Meta-learning for Visual Object Trackers
动机
一个典型的tracking episode为:跟踪模型适用于一个序列初始帧中目标的特定边界框。
而跟踪器的最终目标是在未来帧预测目标的位置,因此应该希望根据最终目标来学习跟踪器。
比如,如果我们能够看到未来帧中的变量,就可以构建更稳健的目标模型,并防止他们对当前目标的表观或者背景杂乱过拟合,或者可以后退一步,观察跟踪器在视频上的运行,看跟踪器是否能够很好的泛化,并找到他们跟踪失败的原因,并相应的调整程序。
一般的在线跟踪器


Meta-learning algorithm
作者提出的meta-learning方法有两个目标:
1. 一个序列上跟踪器的初始化从\theta_0开始,并应用参数为\alpha的更新函数M的一次或者非常少量次的迭代来完成。
2. 得到的跟踪器在后续的帧中准确且稳定。

将初始模型应用于稍前面的帧有两个目的,1. 模型应该足够鲁棒的去处理不仅仅是帧间的变化,2. 如果没有太多需要修复的话,应该在跟踪期间快速更新。

Update rules for subsequent frames

虽然可以通过这种方式解决不稳定收敛行为,但是,都不如简单的选择一个单一的学习率效果好。因此作者在后续帧中选择一个单一的学习率。
Meta-trackers
Meta-training of correlation based tracker


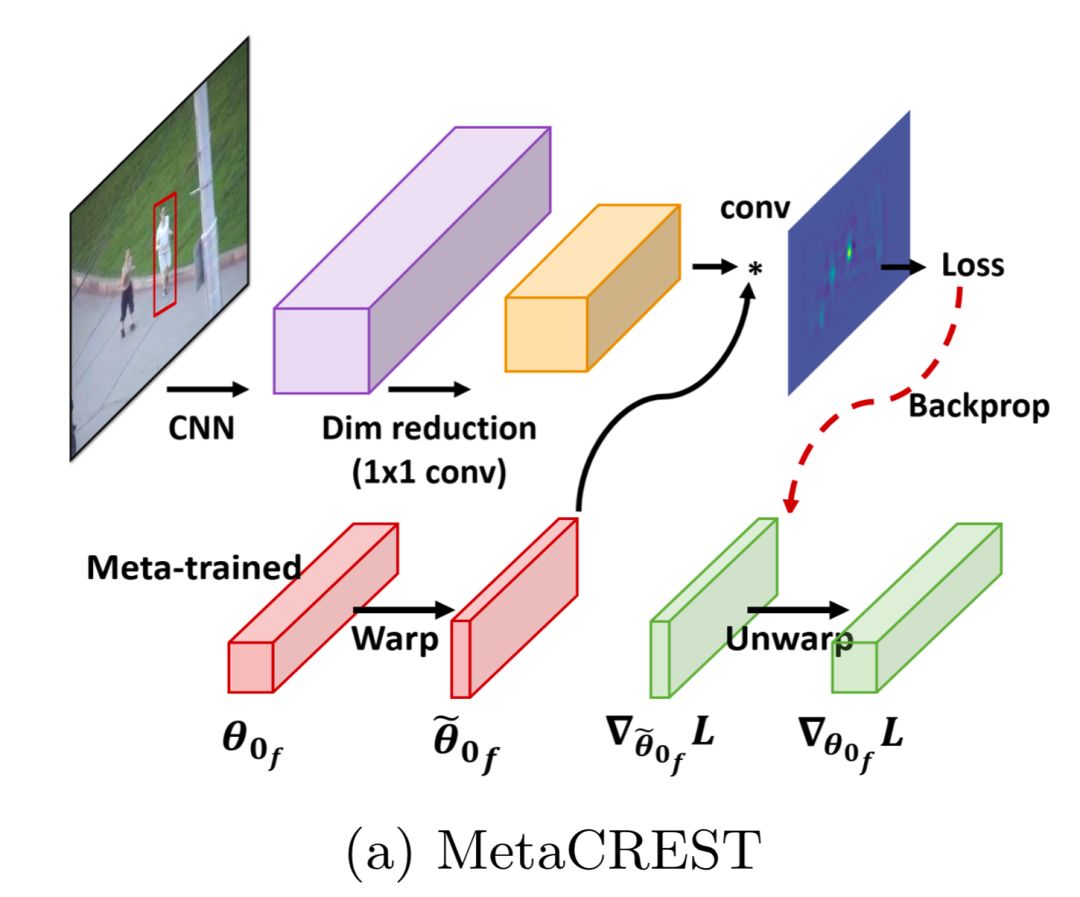
这鼓励模型关注那些远离groundtruth的部分。通过用卷积层来重新表示卷积滤波,卷积滤波可以有效的整合进CNN框架中,更容易添加新的模块。原作者通过添加spatio-temporal residual modules来避免目标模型在遇到大的表观变化的时候退化,并且设计复杂的初始化,学习率,权重衰减规律。不使用这些花里胡哨的东西,作者试图通过meta-learning过程学习一个鲁棒的单层的相关滤波器,将CRSET整合进meta-learning框架中需要解决两个重要的问题:
1. Meta-leanring dimensionality reduction
CREST使用PCA对提取的CNN特征进行降维,从512降到64,这不仅会降低计算量,而且有助于增加相关滤波的鲁棒性。在第一帧学习PCA的映射矩阵用于随后的所有帧,在meta-training相关滤波器的时候有个问题,作者想寻求找到能够应用于所有样本的一个相关滤波器的全局初始化,但是每个序列的PCA的映射矩阵都不一致,这使得不可能在映射空间得到一个全局初始化,

2. Canonicalsize initialization
相关滤波器的大小依赖于目标的大小,不同大小的目标所学习到的滤波器也不一样大,为了meta-train一个固定大小的初始滤波器,应该将所有的目标变换到同样的大小,但是,这会引入目标的变形,以致降低识别性能。为了充分利用相关滤波器的能力,作者提出使用规范大小初始化,并且其大小和表观比应该根据训练集中的目标的均值计算得到。具体应用时,根据规范大小初始化,将其扭曲到一个跟踪episode的目标的特定大小,
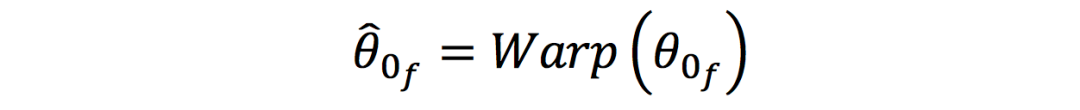
Meta-training of tracking-by-detection tracker
MDNet基于二值CNN分类器,包括一些卷积层和全连阶层,在离线阶段,MDNet使用多域训练技术来预训练分类器,在初始帧,MDNet随机初始化最后的全连接层,使用大量的正负样本训练大约30次,随后帧的目标位置通过最高得分的正patch的边界框的回归的平均值决定。
多域预训练其实是实现鲁棒性的关键因素,作者使用aggressive dropout regularizer以及在不同层上定义不同的学习率进一步避免模型过拟合于当前目标的表观。作者试图不利用这些技术(多域训练和regularizers),只利用提出的meta-learning,来获得鲁棒的能够快速适应的分类器。
Meta-training
MDNet很容易嵌入到提出的meta-learning框架中,在初始帧得到输入图像块
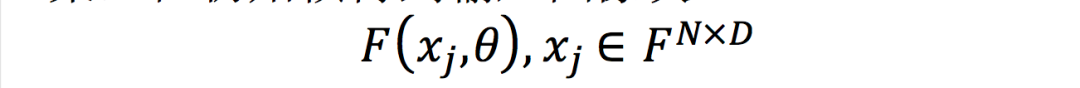
其中D为图像块的大小,N为图像块的个数,图像块通过CNN分类器,损失函数为一个简单的交叉熵损失:
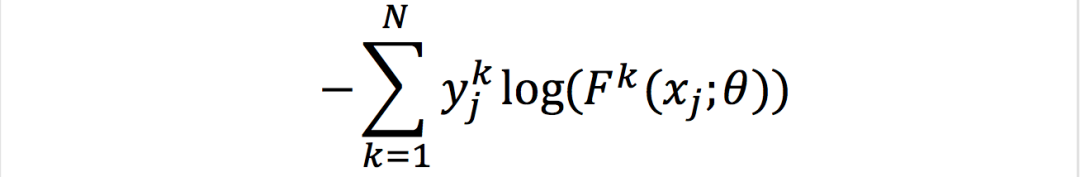
Label shuffling
虽然大规模视频检测数据集包含丰富的目标,但是其数量和种类相比于其他数据集尤其是图像数据集还是有限的,这可能导致深度CNN分类器记住数据库中的所有目标实例,从而将新看到的目标作为背景,为了避免这种情况,采用label shuffling trick,也就是每次在运行tracking episode时,将标签重新洗牌,也就是原来标签为0的样本的标签全部改为1,原来标签为1的样本的标签全部改为0。这个技巧能让分类器学习如何区分目标和背景,而不是记住特定的目标表观。
实验
量化评价
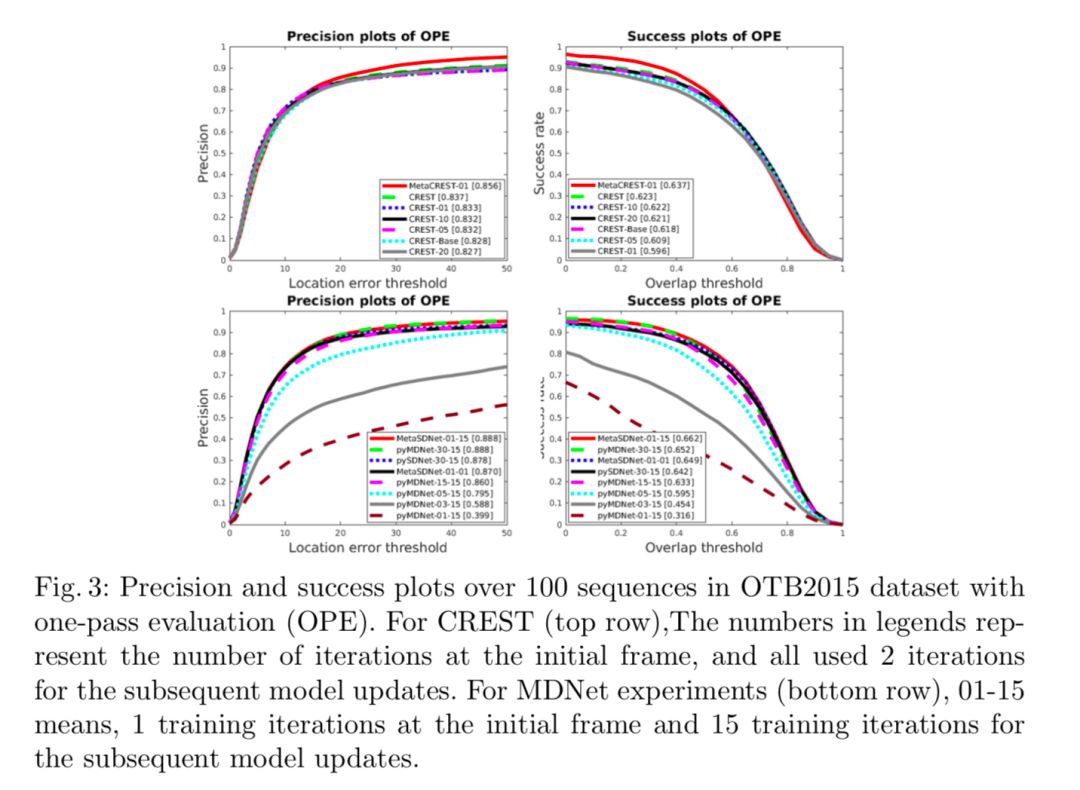
pyMDNet使用了多域训练;
CREST使用spatio-temporal residual modules;
MetaCREST和metaSDNet只在初始帧更新了一次,其功能就超过对比的CREST和MDNet,MDNet在初始帧迭代了30次,较少的迭代次数会导致严重的性能退化,这表明在初始帧得到一个鲁棒的目标模型对于后续帧的跟踪来讲是非常重要的,CREST在初始帧迭代了10多次才能达到最好的性能。
初始化的速度和性能评价
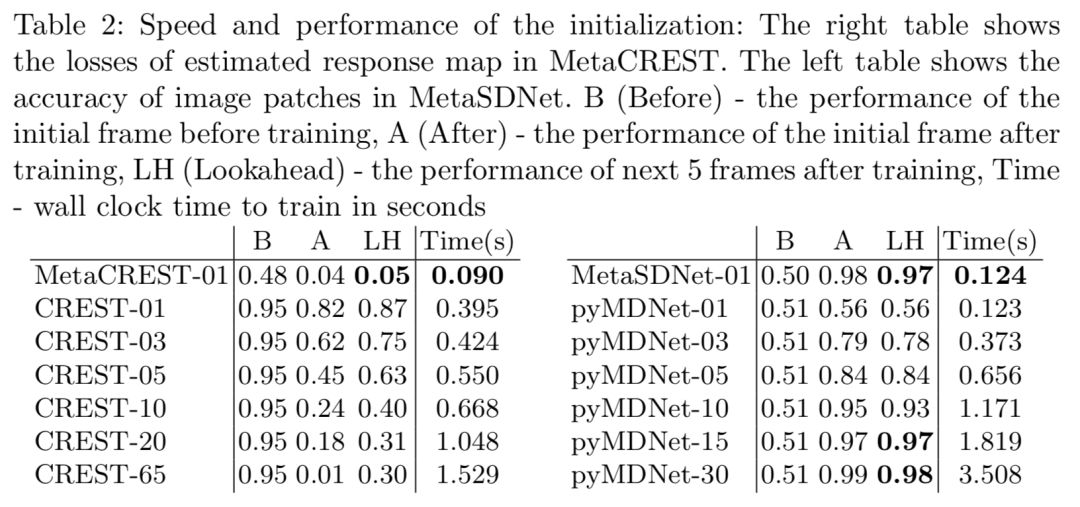
在CREST中,除了特征提取,相关滤波卷积和PCA降维都会花费大量的时间。
MDNet需要大量的正负样本,以及许多次的模型更新,相比MDNet,MetaSDNet只需少量样本,就能在改善性能的同时,达到30x的加速,在随后的更新中,更新时间就比较少了,因为只更新最后的3个全连阶层。而且之前帧中取得的样本的特征已经存储在一个数据库中,所以更新花费的实际计算量就很好的分布在每帧中了。
作者也通过初始化来测试meta-learning框架的性能。模型初始化以后,作者评价了第一帧和第五帧的性能,以展示跟踪器的泛化性能。MetaSDNet经过一次迭代就实现了很高的精确度,但是pyMDNet经过一次迭代以后其准确率仅比猜测高一点,在MetaCREST中有效性更为明显,MetaCREST-01没有任何更新的时候就达到了CREST-05更新5次以后的性能,在原始CREST跟踪器中,他们训练模型直到模型达到0.02的损失,这相当于平均65次迭代,但是其泛化能力却不如metaCREST(0.05 vs 0.30)。
虽然这与最终的性能不成比例,但是这可以反映作者提出的meta-learning算法确实有效。
响应图的可视化
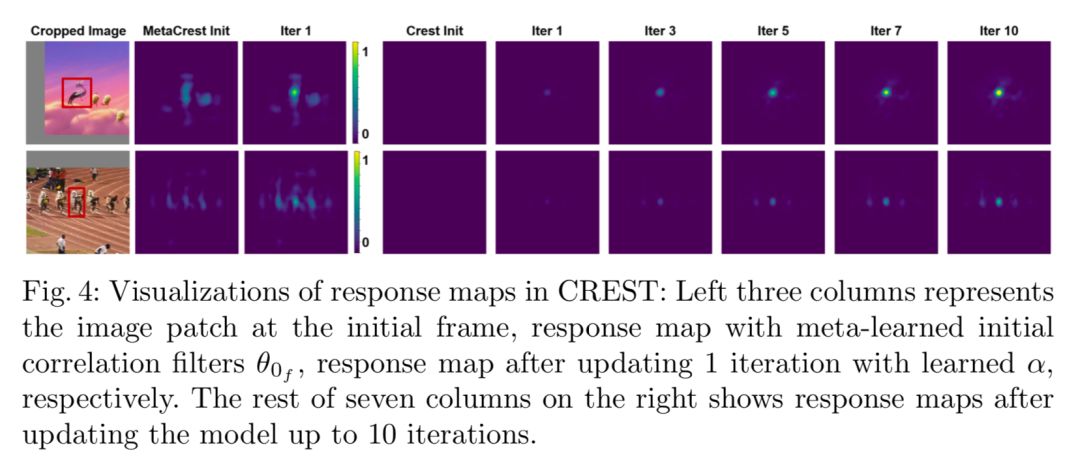
作者将MetaCREST的滤波器进行了可视化,可以看到,metaCREST在没有经过更新时已经能够在目标位置产生较高的值,但是没有明显的最大值,经过一次迭代以后,最大值变得特别明显,可以清楚的用于定位,而CREST需要消耗更多的迭代次数才能在目标位置达到较高的响应。
稳健初始化的定性示例
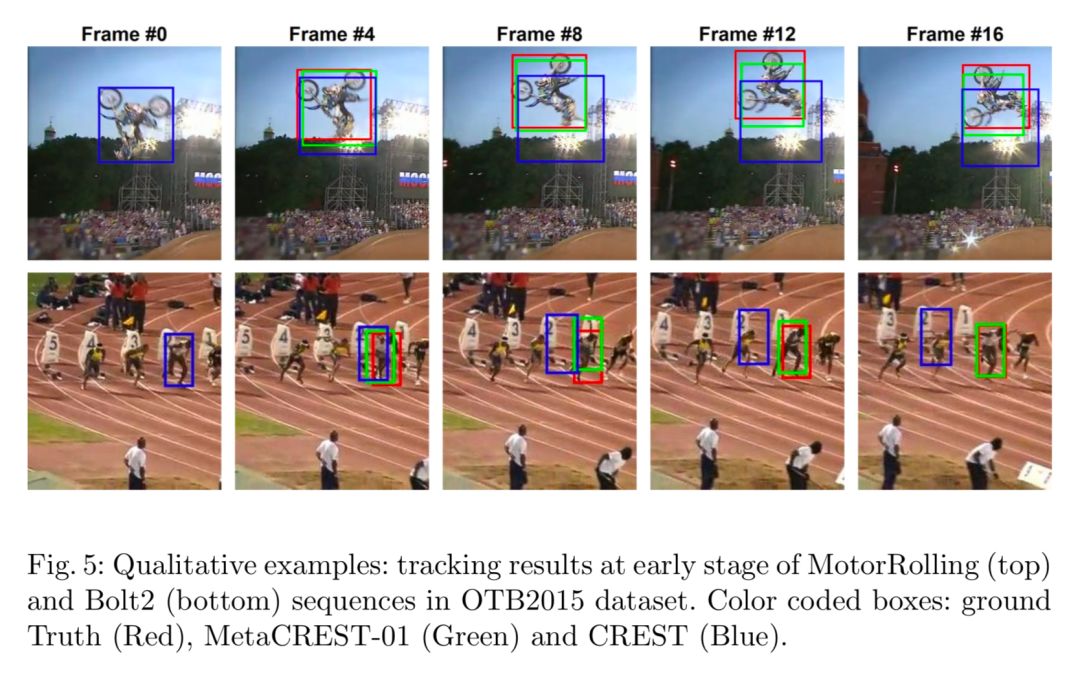
可以看到在MotorRolling序列中,CREST被森林和背景之间的水平线所干扰,此时SREST的损失为0,metaSREST的损失为0.1255,这是个强有力的证据证明最优解不一定意味着在未来帧也有好的泛化能力。而metaSREST虽然没有在当前帧找到最优解,但是在未来帧中的泛化能力还是不错的。在Bolt2序列中,边界框左上角的部分为干扰物,干扰了CREST跟踪器,metaCREST可以很容易的忽略背景杂乱,并关注边界框中心的物体。




