7 Papers & Radios | YOLO v4它来了;北航MangaGAN生成久保带人Style漫画形象
参与:杜伟、楚航、罗若天
本周的重要论文有最新推出的 YOLO v4,以及北航团队使用 MangaGAN 新方法生成久保带人 Style 的漫画形象。
Unpaired Photo-to-manga Translation Based on The Methodology of Manga Drawing
Generalizing from a Few Examples: A Survey on Few-Shot Learning
CLEVRER: COLLISION EVENTS FOR VIDEO REPRESENTATION AND REASONING
Detection in Crowded Scenes: One Proposal, Multiple Predictions
YOLOv4: Optimal Speed and Accuracy of Object Detection
NBDT: Neural-Backed Decision Trees
Chip Placement with Deep Reinforcement Learning
论文 1:Unpaired Photo-to-manga Translation Based on The Methodology of Manga Drawing
作者:Hao Su、Jianwei Niu、 Ji Wan 等
论文链接:https://arxiv.org/pdf/2004.10634v1.pdf
摘要:漫画是很多人的童年回忆,除了经典的《银魂》、《海贼王》、《火影》,久保带人的作品《死神》也很有人气。最近,六位来自北航的研究者推出了一款漫画脸转换模型「MangaGAN」,实现了真人照片到漫画脸的完美转换。
这篇论文中提出了「MangaGAN」,这是一种基于生成对抗网络(GAN)的非成对照片到漫画转换方法。用来训练 MangaGAN 的数据集也来源于一部非常受欢迎的漫画作品——久保带人的《死神(Bleach)》,包含漫画人脸的面部特征、特征点、身体等元素,所以生成结果也带有强烈的久保带人风格。总体来说,MangaGAN 包含两个分支:一个分支通过几何转换网络(Geometric Transformation Network,GTN)学习几何映射;另一个分支通过外观转换网络(Appearance Transformation Network,ATN)学习外观映射。
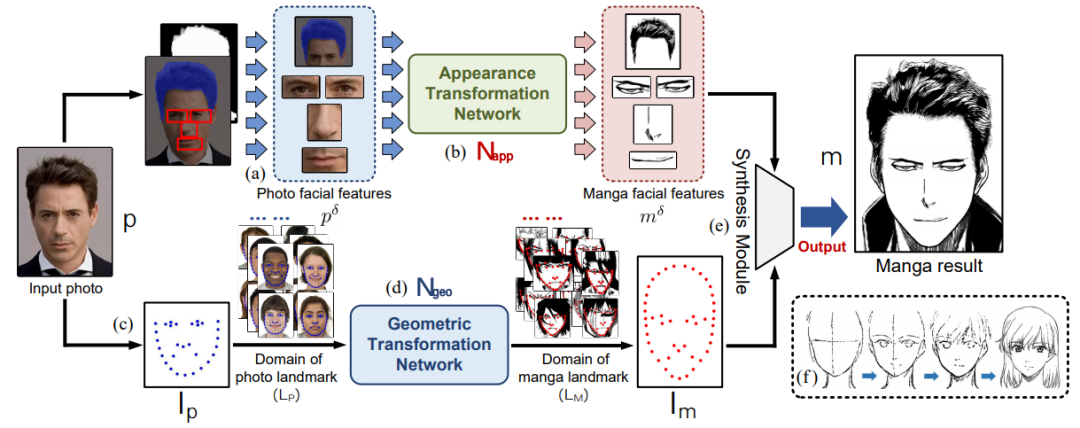
MangaGAN 生成漫画脸的整体流程。
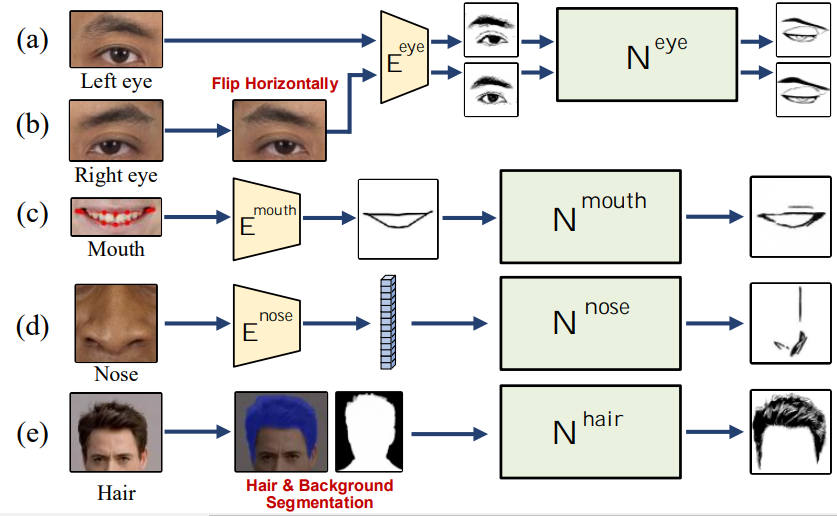
外观转换 ATN 是 multi-GAN 结构的网络,包含四个局部 GAN,分别用来转换眼、口、鼻和头发这四个面部位置。针对每个部位的 GAN,会有专属的训练策略和编码器以改善其性能。
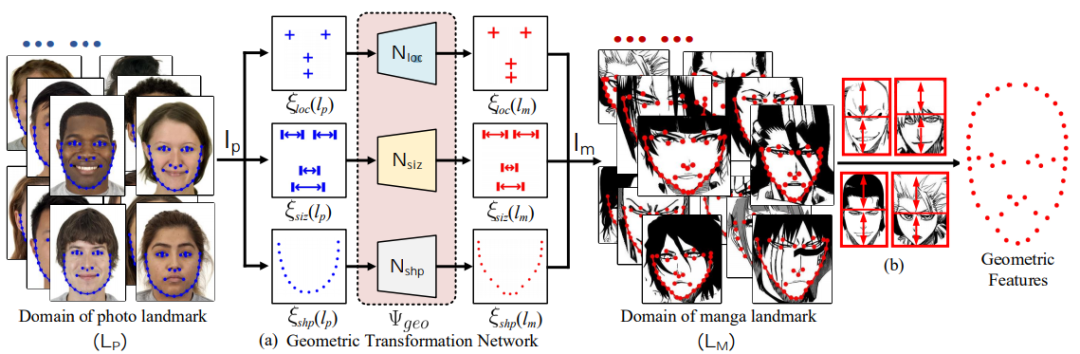
几何转换 GTN 的 pipeline。几何信息被分为三种独立属性:位置、大小和脸型,然后使用 N_loc、N_siz、N_sha 三个 sub-GAN 分别进行转换。
推荐:有了这个模型,你也能拥有冷峻严酷的漫画形象——并且是独树一帜的久保带人 Style!
论文 2:Generalizing from a Few Examples: A Survey on Few-Shot Learning
作者:YAQING WANG、QUANMING YAO、JAMES T. KWOK、LIONEL M. NI
论文链接:https://arxiv.org/pdf/1904.05046.pdf
摘要:机器学习在数据密集型应用中取得了很大成功,但在面临小数据集的情况下往往捉襟见肘。近期出现的小样本学习方法(Few-Shot Learning,FSL)旨在解决该问题。FSL 利用先验知识,能够快速泛化至仅包含少量具备监督信息的样本的新任务中。
在这篇论文中,来自香港科技大学和第四范式的研究者对 FSL 方法进行了综述。首先该论文给出了 FSL 的正式定义,并厘清了它与相关机器学习问题的关联和差异(弱监督学习、不平衡学习、迁移学习和元学习);然后指出 FSL 的核心问题,即经验风险最小化方法不可靠;最后,根据各个方法利用先验知识处理该核心问题的方式,该研究将 FSL 方法分为三大类:数据:利用先验知识增强监督信号;模型:利用先验知识缩小假设空间的大小;算法:利用先验知识更改给定假设空间中对最优假设的搜索。

充足和少训练样本学习的对比。
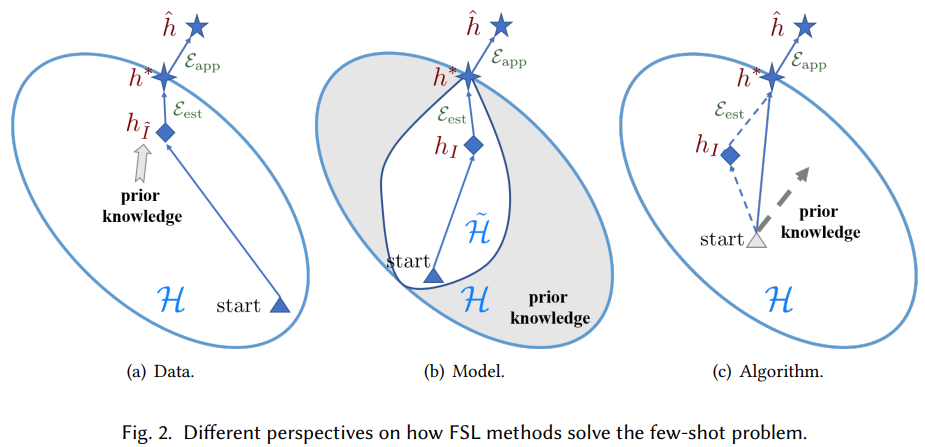
从数据、模型和算法三种不同视角来观察 FSL 方法如何解决小样本问题。
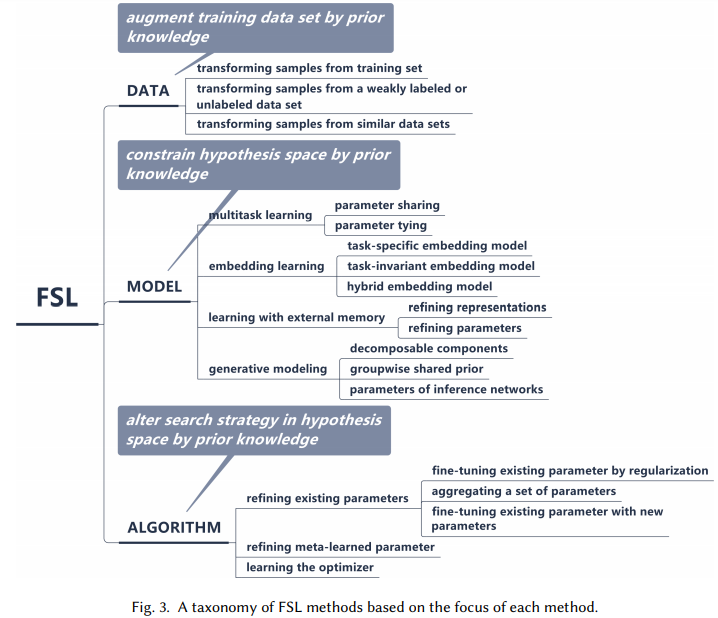
FSL 方法分类。
推荐:该研究提出了 FSL 的未来研究方向:FSL 问题设置、技术、应用和理论。
论文 3:CLEVRER: COLLISION EVENTS FOR VIDEO REPRESENTATION AND REASONING
作者:Kexin Yi、Chuang Gan、Joshua B. Tenenbaum 等
论文链接:https://arxiv.org/pdf/1910.01442.pdf
摘要:在静态图像和视频上提出的各种数据集的推动下,复杂视觉推理问题已经在人工智能和计算机视觉领域得到了广泛研究。然而,大多数视频推理数据集的侧重点是从复杂的视觉和语言输入中进行模式识别,而不是基于因果结构。尽管这些数据集涵盖了视觉的复杂性和多样性,但推理过程背后的基本逻辑、时间和因果结构却很少被探索。
在这篇论文中,麻省理工和 DeepMind 的研究者从互补的角度研究了视频中的时间和因果推理问题。受视觉推理数据集 CLEVR 的启发,他们简化了视觉识别问题,但增强了交互对象背后的时间和因果结构的复杂度。结合从发展心理学中汲取的灵感,他们提出了一种针对时间和因果推理问题的数据集。
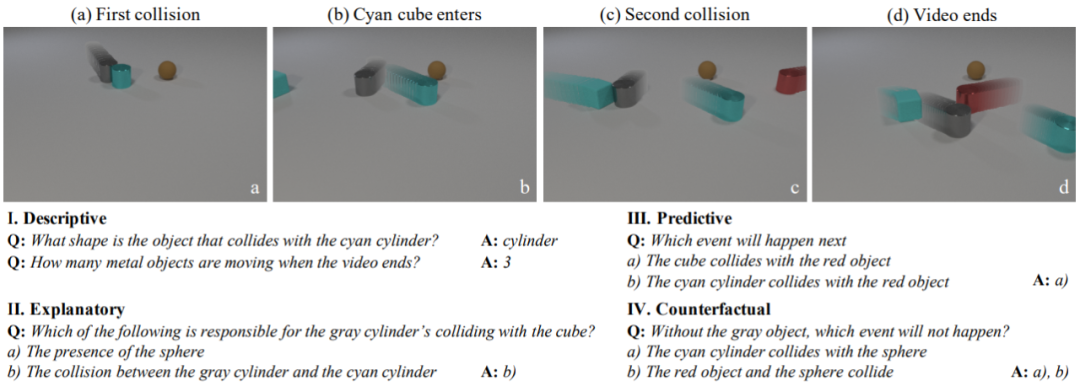
CLEVRER 包含 20,000 个关于碰撞物体的合成视频以及 300,000 多个问题和答案。问题的类型包括以下四种,即描述性(「什么颜色」)、解释性(「什么原因」)、预测性(「将发生什么」)和反事实(「如果…会发生什么」)。
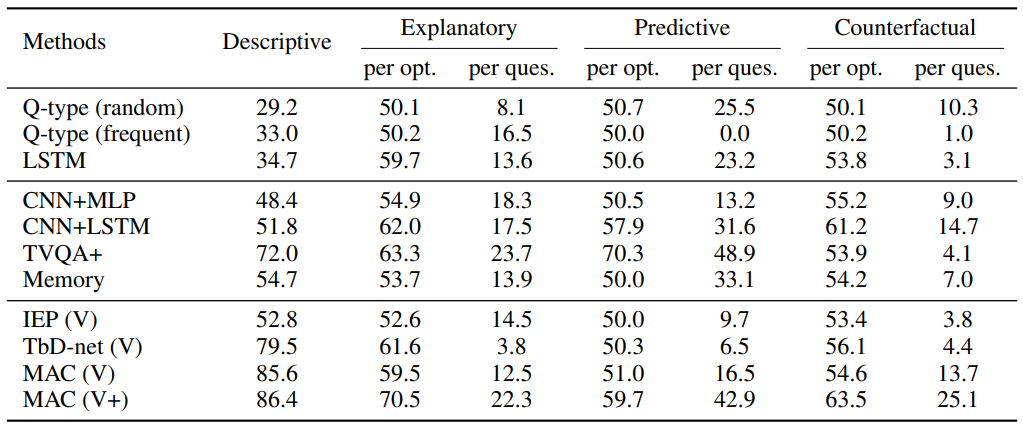
研究者对各种最新的视觉推理模型在 CLEVRER 上进行了评估,结果显示,尽管这些模型在描述性问题上表现良好,但它们缺乏因果推理的能力,并且在解释性、预测性和反事实问题上表现不佳。
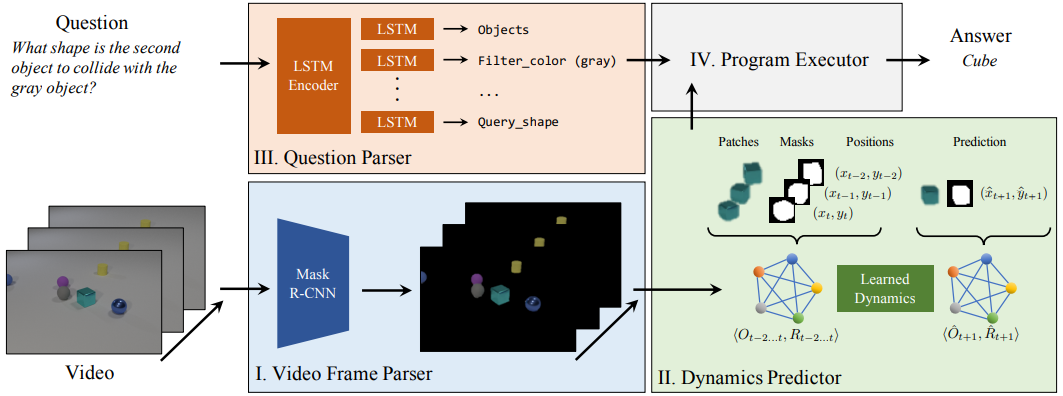
NS-DR 模型结合了用于模式识别和动力学预测的神经网络,以及用于因果推理的符号逻辑,包含四个组件:视频解析器、动态预测器、问题解析器和程序执行器。
推荐:数据集的亮点在于,它包含 20,000 个关于碰撞物体的合成视频以及 300,000 多个问题和答案,从互补的角度研究了视频中的时间和因果推理问题。
论文 4:Detection in Crowded Scenes: One Proposal, Multiple Predictions
作者:Xuangeng Chu、 Anlin Zheng、Jian Sun 等
论文链接:https://arxiv.org/pdf/2003.09163.pdf
摘要:在传统的目标检测框架中,一个候选框往往仅输出一个预测框,这为处理遮挡目标增添了很多困难。旷视研究院提出了一种一个候选框可以预测多个目标的检测方法,更加适用于密集物体的检测。为了适应一个候选框预测多个结果的方法,还设计了 EMD Loss 和 Set NMS,前者确保了在网络训练过程中结果的排列不变性,后者让检测器能够在后处理阶段中保留来自同一个候选框的多个预测框。
相对于经典的 FPN 检测器,该方法在存在大量遮挡的 CrowdHuman 数据集上可以取得明显涨点,在较为稀疏的数据集例如 COCO 上,也会有少量的性能提升。
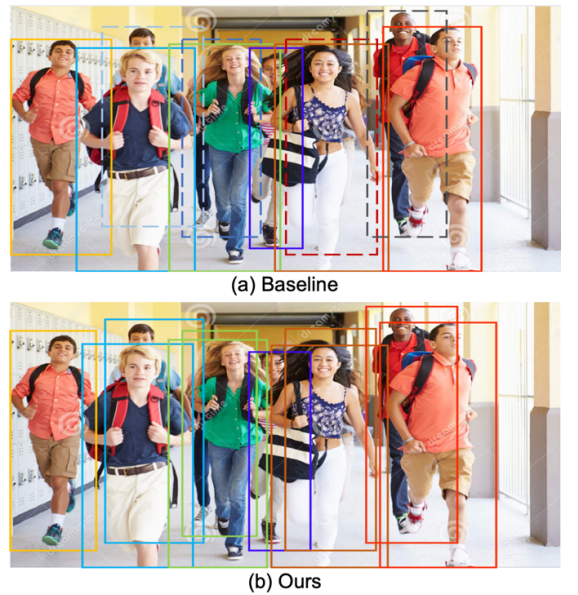
密集场景中的人体检测,本研究提出的检测方法与 FPN 基线方法的检测效果对比。
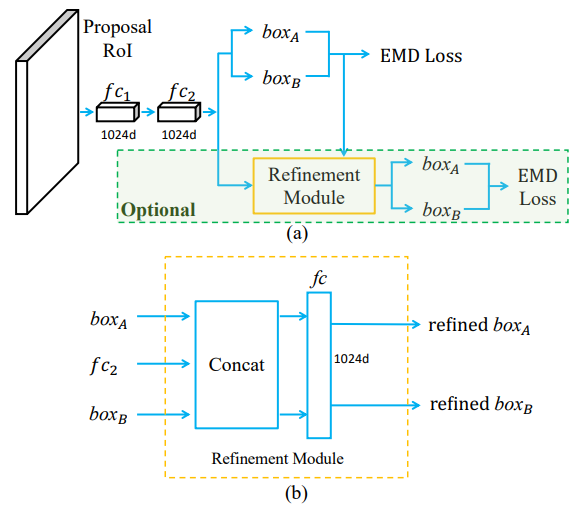
整体架构流程图。
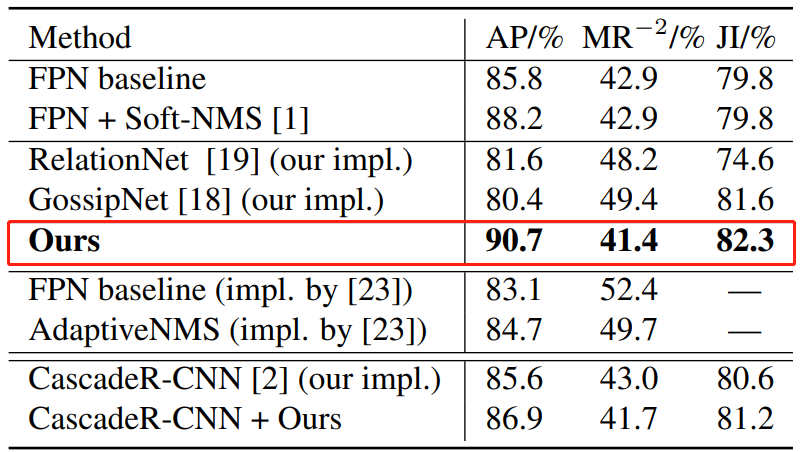
在 CrowdHuman 验证集上,各种密集场景检测方法的效果比较,其中 AP 和 JI 值越高、MR_-2 值越低代表性能更佳。
推荐:本文已入选 CVPR 2020 Oral。
论文 5:YOLOv4: Optimal Speed and Accuracy of Object Detection
作者:Alexey Bochkovskiy、Chien-Yao Wang、Hong-Yuan Mark Liao
论文链接:https://arxiv.org/pdf/2004.10934.pdf
项目地址:https://github.com/AlexeyAB/darknet
摘要:两个月前,YOLO 之父 Joseph Redmon 表示,由于无法忍受自己工作所带来的的负面影响,决定退出计算机视觉领域。此事引发了极大的热议,其中一个悬念就是:我们还能等到 YOLO v4 面世吗?
近日,YOLO 的官方 Github 账号更新了 YOLO v4 的 arXiv 链接与开源代码链接,迅速引起了 CV 社区的关注。在相关论文中,研究者对比了 YOLOv4 和当前最优目标检测器,发现 YOLOv4 在取得与 EfficientDet 同等性能的情况下,速度是 EfficientDet 的二倍!此外,与 YOLOv3 相比,新版本的 AP 和 FPS 分别提高了 10% 和 12%。
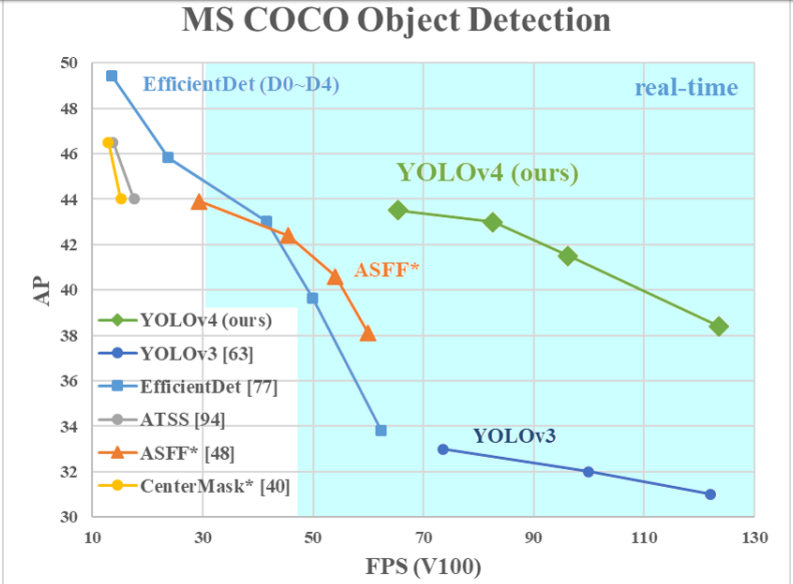
本研究提出的 YOLO v4 与其他 SOTA 目标检测器的对比。
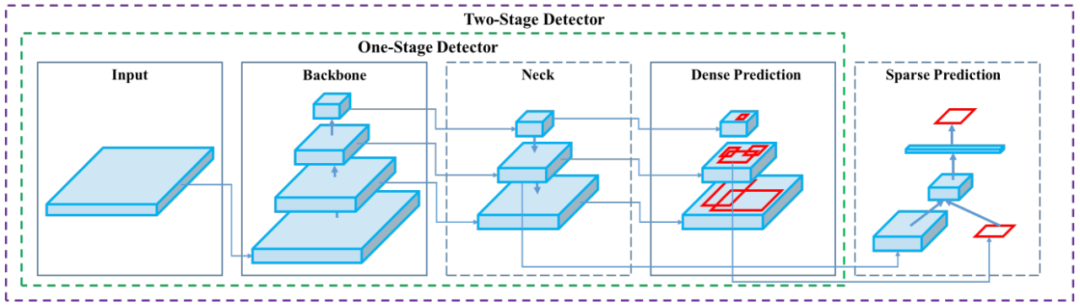
单阶段(One-Stage)与双阶段(Two-Stage)检测器图示。
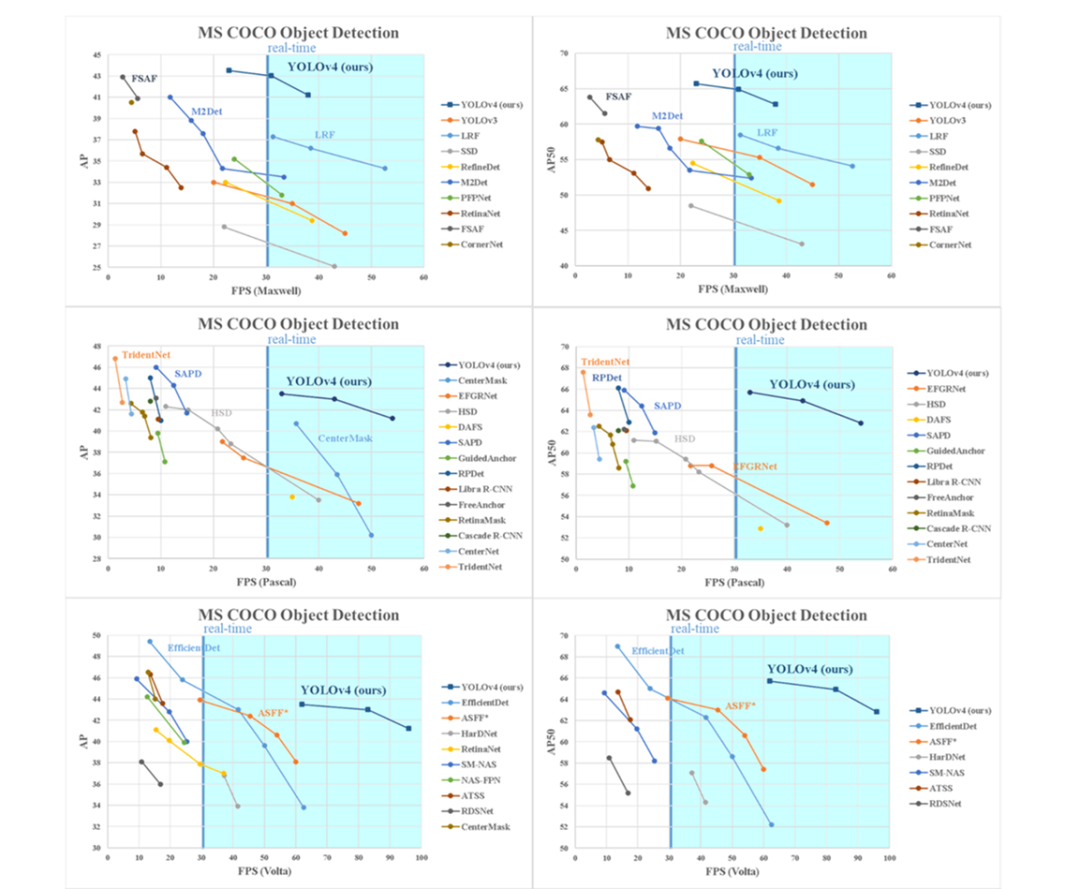
不同目标检测器的速度和准确度对比。
推荐:继 YOLO 之父 Joseph Redmon 宣布其推出计算机视觉领域两个月后,YOLO v4 它悄无声息地来了。
论文 6:NBDT: Neural-Backed Decision Trees
作者:Alvin Wan、Lisa Dunlap、Joseph E. Gonzalez 等
论文链接:https://arxiv.org/pdf/2004.00221.pdf
项目地址:https://github.com/alvinwan/neural-backed-decision-trees
摘要:决策树是一种用于分类的经典机器学习方法,它易于理解且可解释性强,能够在中等规模数据上以低难度获得较好的模型。尽管决策树有诸多优点,但历史经验告诉我们,如果遇上 ImageNet 这一级别的数据,其性能还是远远比不上神经网络。「准确率」和「可解释性」,「鱼」与「熊掌」要如何兼得?把二者结合会怎样?最近,来自加州大学伯克利分校和波士顿大学的研究者就实践了这种想法。
他们提出了一种神经支持决策树「Neural-backed decision trees」,在 ImageNet 上取得了 75.30% 的 top-1 分类准确率,在保留决策树可解释性的同时取得了当前神经网络才能达到的准确率,比其他基于决策树的图像分类方法高出了大约 14%。
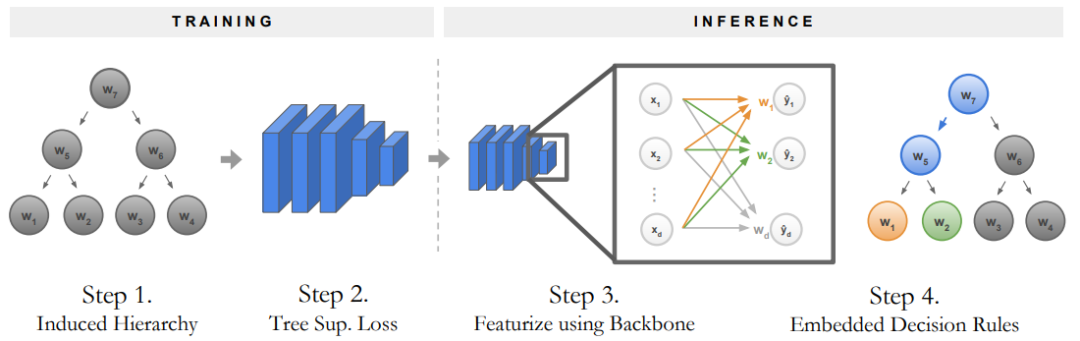
神经支持决策树的训练和推理流程。
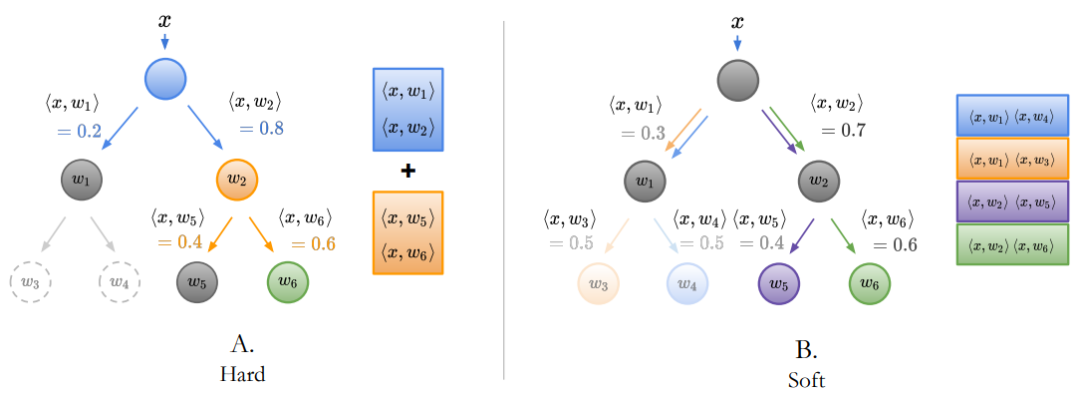
树监督损失有两个变体,分别是定义每个节点交叉熵项的 Hard 树监督损失,和定义所有节点概率交叉熵损失的 Soft 数监督损失。
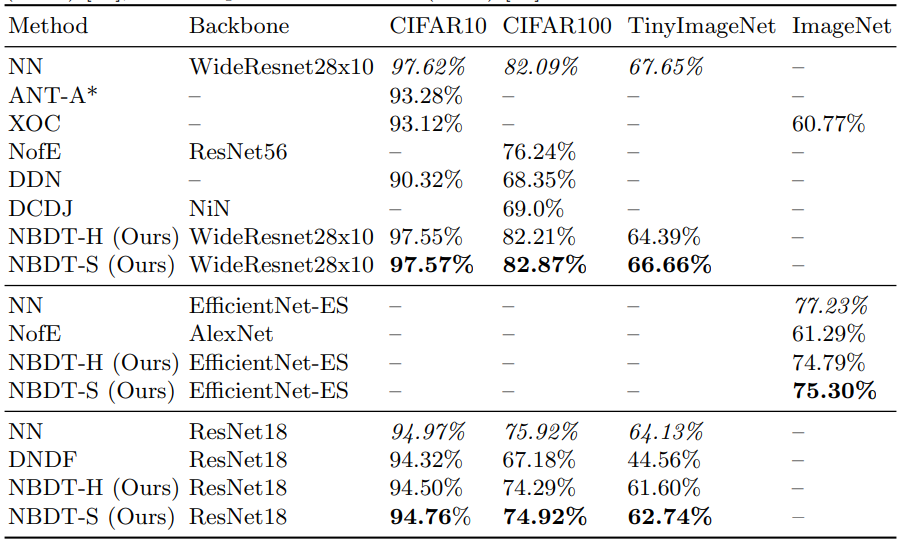
在 CIFAR10、CIFAR100、TinyImageNet 和 ImageNet 数据集上的结果对比,其中神经支持决策树(NBDT)优于所有其他基于决策树的方法。
推荐:这种神经支持决策树新研究兼顾了准确率与可解释性!
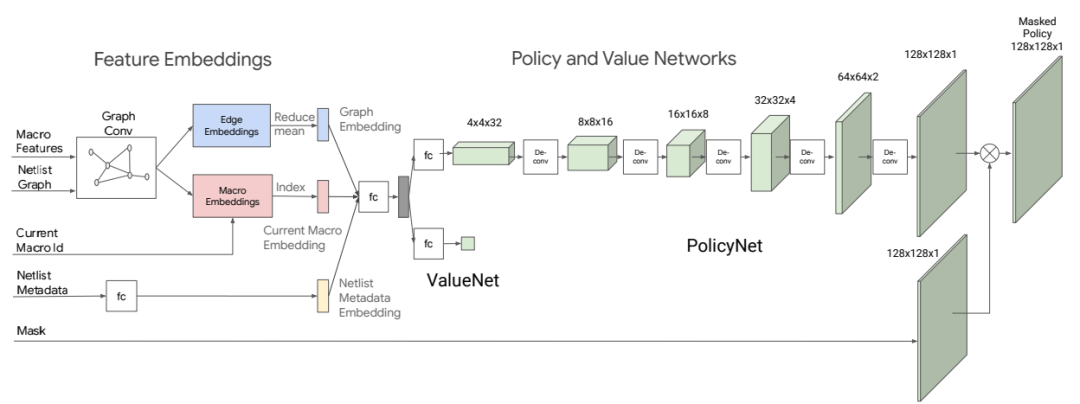
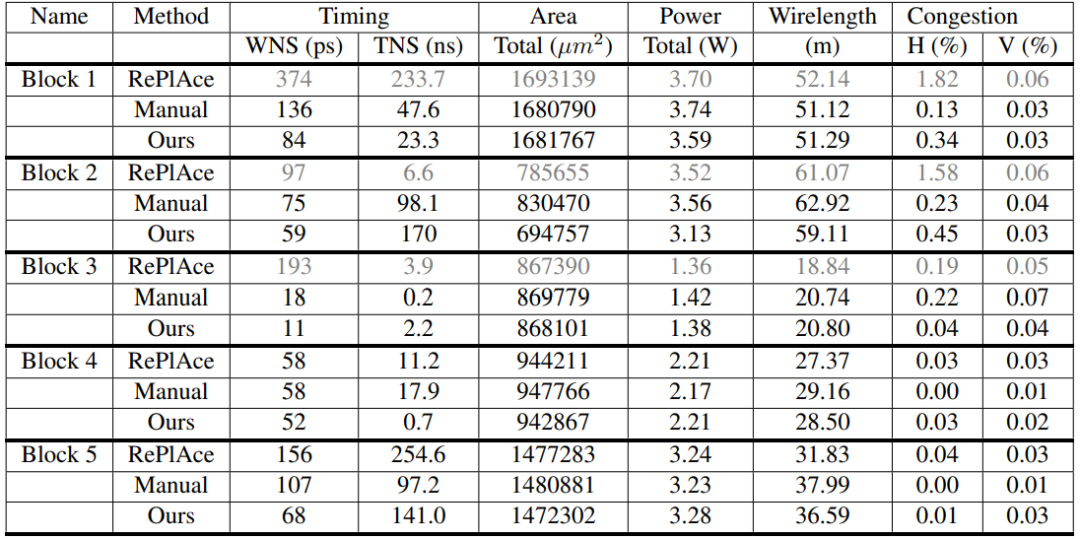
论文 7:Chip Placement with Deep Reinforcement Learning
作者:Azalia Mirhoseini、Anna Goldie、Jeff Dean 等
论文链接:https://arxiv.org/pdf/2004.10746.pdf
摘要:在芯片设计过程中,芯片布局(chip placement)可以说是其中最复杂和耗时的步骤了。芯片设计周期的缩短有助于硬件设备适应机器学习领域的快速发展,那么,机器学习能否助力芯片设计呢?最近,谷歌提出了一种基于强化学习的芯片布局方法。

本周 10 篇 NLP 精选论文是:





