能生成逼真图像的不只有 GAN
本文由机器之心编译
去年 9 月,BigGAN 横空出世,被誉为「史上最强 GAN 生成器」,其逼真程度众多研究者高呼「鹅妹子嘤」!相关论文也被 ICLR 2019 接收为 Oral 论文。
今年 2 月,BigGAN 的一作又发布了更新版论文,提出了新版 BigGAN——BigGAN-deep,其训练速度、FID 和 IS 都优于原版。
BigGAN 及其加强版的问世让我们看到了生成对抗网络在图像生成方面的巨大威力,但 GAN在生成图像方面真的无懈可击吗?它是生成图像的最佳方式吗?
近日,DeepMind 的研究人员发表论文表示,他们利用 VQ-VAE 生成了可以媲美当前最佳 GAN 模型(BigGAN-deep)的图像,而且图像多样性上要优于 BigGAN-deep。该模型借助图像压缩方面的概念,将像素空间映射到量化的离散空间,从而进一步借助自编码器的结构学习怎样生成高清大图。
此外,VQ-VAE 尤其适用于生成较大的图像。研究者表明,VQ-VAE 多尺度层级结构能从局部的纹理到全局的形状慢慢完善生成效果,生成的样本质量能够在 ImageNet 等多层面数据集上与当前最优的生成对抗网络媲美,同时不会出现生成对抗网络中模式崩塌和多样性缺失等已知的缺陷。
论文地址:https://arxiv.org/pdf/1906.00446.pdf
更多样本地址:https://drive.google.com/file/d/1H2nr_Cu7OK18tRemsWn_6o5DGMNYentM/view
生成效果
即使不采用生成对抗网络架构,只使用自编码器结构与 PixelCNN,VQ-VAE 也能分层地生成真正高清大图。也许它和 BigGAN的效果差不多,但生成样本的多样性肯定是更有优势的。

VQ-VAE 这种模型在生成真实高清样本时,它能捕捉数据集中展示的多样性。这种多样性可能体现在年龄、性别、肤色和发色等特征上,这些是 BigGAN 很难显式捕捉到的。如下展示了 VQ-VAE 在 FFHQ-1024 高清数据集上训练后的生成效果,细节都非常合理:


那么 VQ-VAE 和 BigGAN 的直观对比是什么样的?如下左边 16 张图为 VQ-VAE 的生成效果,右边 16 张为 BigGAN 的生成效果。它们都是根据 ImageNet 中的同一类别生成的,但我们会发现 VQ-VAE 不仅在多样性上非常强,在生成细节上也非常厉害。BigGAN 生成的人脸并不是太自然,五官错位有些严重。

深度生成模型都有什么问题
研究者将常见的生成模型分为两种:一种是基于似然的模型,包括 VAE 及其变体、基于流的模型、以及自回归(autoregressive)模型,另一种是隐式生成模型,如生成对抗网络(GAN)。这些模型都会存在某些方面的缺陷,如样本质量、多样性、生成速度等。
GAN 利用生成器和判别器来优化 minimax 目标函数,前者通过将随机噪声映射到图像空间来生成图像,后者通过分辨生成器生成的图像是否为真来定义生成器的损失函数。大规模的 GAN 模型已经可以生成高质量和高清晰度的图片。然而,众所周知,GAN 生成的样本并不能完全捕捉真实分布中的多样性。另一方面,针对生成对抗网络的评价非常困难,目前依然不存在一个较通用的度量标准,用于在测试集中判断模型是否过拟合。
与生成对抗网络不同的是,基于似然的模型在训练集上优化一个负对数似然函数(negative log-likelihood)。这一目标函数可以对模型进行对比并度量在未见数据上的泛化能力。此外,由于模型在训练集上对所有样本分配的概率都达到最大,理论上基于似然的模型可以覆盖数据的所有模式,不存在像生成对抗网络那样的模式崩塌(mode collapse)和多样性缺失(lack of diversity)问题。
但是在这些优点之外,直接最大化像素空间的似然是困难的。首先,像素空间上的负对数似然不一定是对生成样本质量的良好评估方式;其次对于这些模型而言,它们不一定会关注图像的全局结构,因此生成效果也不是很好。
「最强非 GAN 生成器」
在这篇论文中,研究者们利用了有损压缩的思想,令生成模型可以忽略对不重要信息的建模。事实上,JPEG 等图像压缩技术已经表明,在不对图像质量产生显著影响的情况下,我们可以移除超过 80% 以上的数据。正如以前研究所提出的,我们能将图像压缩到离散隐变量空间,这只需要通过自编码器的中间表征就能完成,即一种经量化的向量。
这些中间表征要比原始图像小三十多倍,但仍然能解码并重建为极其逼真的图像。这些离散表征的先验知识能利用当前最优的 PixelCNN(带自注意力机制)建模,其可以称为 PixelSnail。当模型从这些先验中采样时,解码的图像也会展现出高质量与重建的一致性。

图 1:带类别约束的图像生成样本(256x256),它们通过 ImageNet 上训练的两阶段模型可以生成逼真且一致的图像。
除了逼真以外,该生成模型在离散空间上的训练和采样也非常快,它比以前直接在像素空间运算要快 30 倍,这也就意味着能训练更高分辨率的图像。最后,该研究中的编码器和解码器都保留了原始 VQ-VAE 的简单性与速度,这意味着这种方法对于需要快速、低开销的大图编码、解码过程具有很大的吸引力。
生成图像两步走
具体而言,提出的方法遵循两阶段过程:首先我们需要训练一个分层的 VQ-VAE,我们需要用它将图像编码到离散的隐空间;其次我们需要在离散的隐空间拟合一个强大的 PixelCNN 先验,这个隐空间是通过所有图像数据构建的。

如上算法 1 和算法 2 为两阶段过程,其中在第一阶段学习层次化隐编码中,我们可以借助层次结构建模大图像。其主要思想即将局部信息(例如纹理)与目标的几何形状等全局信息分开建模。在第二阶段中,为了进一步压缩图像,并且能够从第一阶段学习到的模型中采样,我们需要在隐编码中学习一种先验知识。
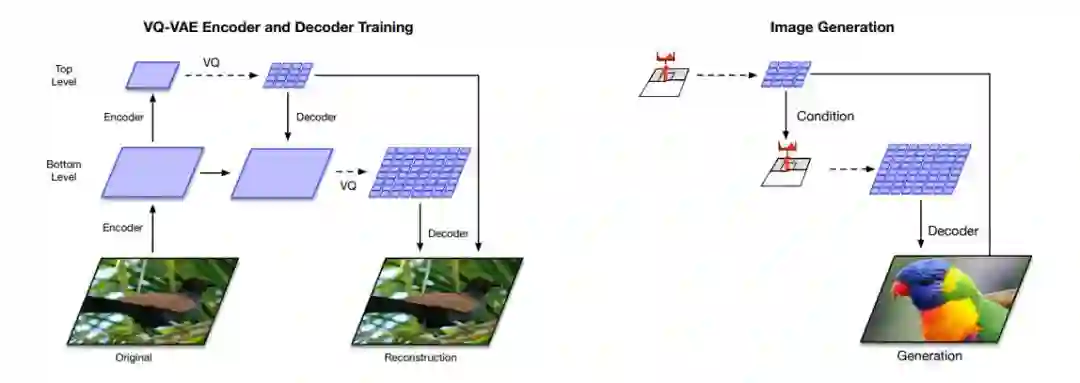
下图展示了该模型的训练和生成过程,它们的过程基本和自编码器类似。如下左图所示为分层 VQ-VAE 的整体架构,它是由编码器和解码器组成的深度神经网络。模型输入是一张 256×256 的图像,它会分别压缩为 64×64 的底层量化隐层和 32×32 的高层量化隐层。解码器从两个隐层中重建图像。
下图右侧为多阶段图像生成。高层 PixcelCNN 先验会通过类别标签进行约束,底层的 PixcelCNN 会以类别标签和第一级编码作为约束。由于前馈解码器的存在,隐层向像素的映射速度很快。(图 1 中的鹦鹉就是根据这个模型生成的)
当然我们也可以用更多的层级来生成更清晰的大图。如下所示为利用不同层级编码所生成的图像结果。

推荐阅读
不吹不擂,你想要的Python面试都在这里了【315+道题】
“IEEE事件”第 7 天,学术无国界从来就不是一句空话,解除对华为评审限制



