生成逼真3D人偶,居然不用3D形状建模,还能学会你的舞步 | 三星CVPR Oral
3D栗子 发自 凹非寺
量子位 出品 | 公众号 QbitAI

当你站在空旷的屋子里,眼神坚定地望向远方。
有只AI已经获得了你的影像,并合成了一座3D全身像。
后来,你开始解放天性,自在舞动,却惊讶地发现:
那个虚拟的自己,也在用同样的姿势起舞,并且几乎和你同步。

一切仿佛与生俱来,像是你的灵魂注入了它的身体。
这是一项中选了CVPR 2019 Oral的研究,但不止是因为效果逼真:
更重要的是,它没有用到3D形状建模 (Explicit 3D Shape Modeling) ,而是依靠2D纹理映射 (2D Texture Map) ,来完成渲染的。
而在这样的情况下,渲染依然逼真。就算是渲染没见过的新姿势,也不在话下。
到底是怎么做到的?
优秀的脑回路

论文写到,这是介于经典图形学方法与深度学习方法之间的一条路。
其中,图形学的思路就是,把几何 (Geometry) 跟纹理 (Texture) 分开处理。
几何是3D的,好比白色的人体雕塑,纹理是2D的,好比外面的皮肤。
而神经网络的任务,只限于预测从纹理到输出图之间,需要怎样的图像形变/扭曲 (Warping) 。换句话说,把2D“皮肤”贴到3D人类的身上。
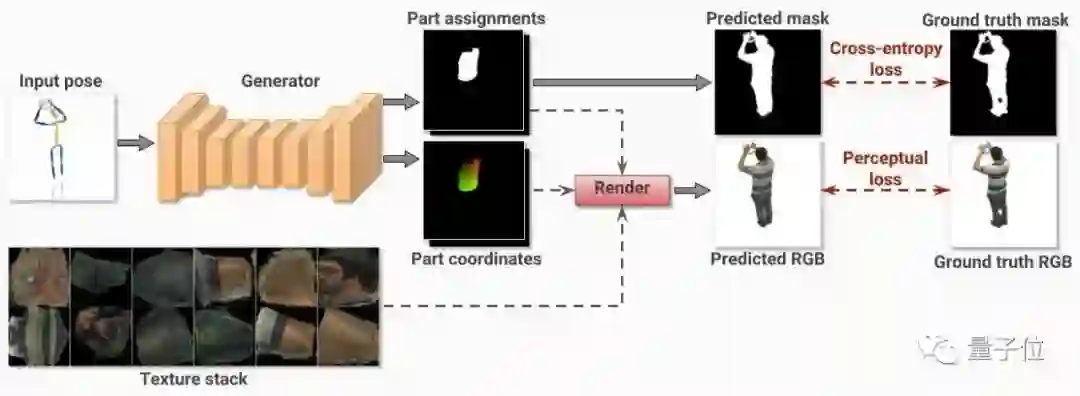
具体来讲,那是一个全卷积网络,角色是生成器 (上图黄色部分) 。它要根据输入的人类姿态,以及摄像头参数,为人体的各个特征点,生成2D纹理坐标。
用这些纹理坐标,可以预测出2D的RGB图像。
反正,最终显现的效果,也是一帧接一帧的2D图。每一帧的角度有所不同,看去便是3D人像了:

就这样,完美避开了3D形状建模。
而训练过程中,网络会把每一次预测出的2D图,和Ground Truth做对比,再把损失 (Losses) 反向传播回到生成器里,增强预测能力。模型是用多视角视频数据来训练的。
训练完成后,就算你摆出AI没见过的新姿势,它也能做出成功的渲染。
团队说那是因为,保留显式的纹理表征 (Explicit Texture Representation) ,有助于提升泛化能力。

当然,没做3D形状建模,也不代表全程都在2D中度过。
别忘了,和2D纹理搭配食用的,是3D人体几何。也就是说,人类的姿态估计,是3D姿态估计。
这一部分,团队从大前辈DensePose那里,借用了精髓:把摄像头拍下的2D图中,人类的每个像素点,都映射到3D人体表面的特定位置上。

于是就有了3D姿态。还记得么,上面的2D纹理预测网络,输入就是姿态。
不用3D形状建模的3D人像合成方法,达成。
引用一句俗语:意料之外,情理之中。
来自俄罗斯
这个思路清新流畅的研究,来自莫斯科的三星AI中心,以及斯科尔科沃科技研究院。团队成员有12人之多。
如果你想要更深刻地感受这个模型的魅力,请从传送门前往观赏。
论文传送门:
https://arxiv.org/abs/1905.08776
主页传送门:
https://saic-violet.github.io/texturedavatar/
前辈DensePose传送门:
http://densepose.org/
— 完 —
小程序|全类别AI学习教程

AI社群|与优秀的人交流


量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态
喜欢就点「在看」吧 !




