来自KAIST的关于《自监督学习掩码自编码器》综述,通过讨论其历史发展、最近的进展以及对各种应用的影响,重点讨论了它在视觉上的应用

掩码自编码器是可扩展的视觉学习器,正如MAE[1],这表明视觉中的自监督学习(SSL)可能会经历与NLP类似的发展轨迹。具体来说,带有掩码预测的生成前置任务(例如BERT)已经成为NLP中事实上的标准SSL实践。相比之下,视觉生成方法的早期尝试已经被它们的判别性同行所掩盖(如对比学习); 然而,掩模图像建模的成功复兴了掩模自编码器(过去常被称为去噪自编码器)。作为弥合与BERT在NLP中的差距的里程碑,掩码自动编码器在视觉和视觉上引起了SSL前所未有的关注。这项工作对掩码自编码器进行了全面的综述,以洞察SSL的一个有前途的方向。作为第一个回顾带掩码自编码器的SSL的作者,本文通过讨论其历史发展、最近的进展以及对各种应用的影响,重点讨论了它在视觉上的应用。
https://www.zhuanzhi.ai/paper/503c1465e6e64706b872ff3061005911
在过去的十年里,深度学习[2]彻底改变了人工智能。早期的开发集中于可扩展的架构设计,如增加模型深度,从AlexNet[3]到VGG[4]和ResNet[5]。近年来,人们的注意力逐渐从设计更好的模型转移到解决深度学习中的数据饥渴问题。例如,ImageNet[6]拥有超过100万张带标签的图像,它已经成为视觉模型的典型基准数据集,而视觉transformer(ViT)[7]据称需要的带标签的图像要多出数百倍。要对一个相对较小的标记数据集进行令人满意的性能,一种常见的方法是在另一个较大的数据集上预训练模型,这被广泛称为迁移学习。自监督学习(SSL)[8],[9]在视觉预训练中表现优于监督学习,引起了广泛关注。
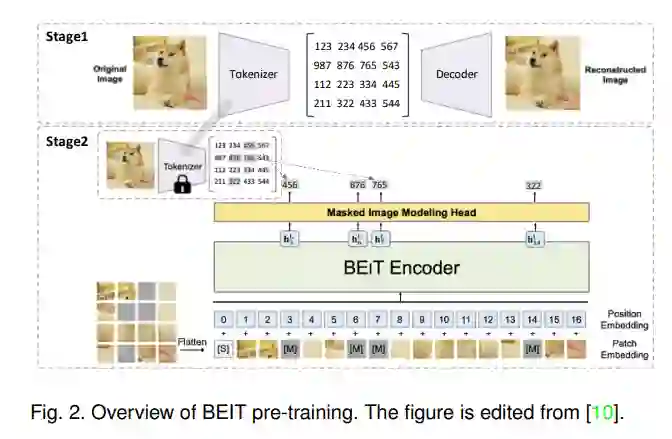
随着2018年对比SSL的出现,联合嵌入方法已成为视觉训练前框架的主导; 然而,这一现状最近受到了一种称为掩码图像建模(MIM)[10]的生成方法的成功的挑战。BEiT[10]采用先屏蔽后预测的策略,利用现成的标记赋予器生成的目标视觉标记来训练模型。通过离散变分自编码器(dVAE)[11]对标记化器进行预训练,因此BEiT可以看作是自编码器[12]去噪的两阶段训练。此外,在MAE[1]中提出了一种视觉中的端到端掩码自编码器,引起了前所未有的关注。
顾名思义,掩码自动编码器是一种带有掩码预测的自动编码器,即从未掩码输入内容预测掩码输入的属性。值得一提的是,掩码自编码器在无监督视觉预训练中并不是什么新东西。追溯到2008年,早期工作[12]预测未掩码的掩码像素,但被称为去噪自编码器[12],[13]。2016年再次进行了类似的调查,任务是图像修复[14]。它在最近的MAE[1]中复兴的成功,超越了联合嵌入方法,启发了许多工作来理解它在视觉上的成功,并将其应用于各种应用,如视频、点云和图形。
掩码自编码器在视觉预训练中非常流行的原因是一个类似的生成式SSL框架,称为掩码语言建模(如BERT[15]),在NLP中得到了广泛的应用。换句话说,视觉中的掩码自动编码器的成功为视觉中的SSL通过带有掩码预测的生成前置任务“可能现在正走上与NLP类似的轨迹”[1]铺平了道路。此外,由于NLP和计算机视觉是现代人工智能的两个主要分支,许多研究人员认为,掩码自编码器可能是SSL的未来。
为此,这项工作对SSL中的掩码自动编码器进行了全面的综述。这项综述涵盖了它在各种数据类型中的应用; 然而,它专注于理解其复兴成功的愿景。请注意,2018/2019年,基于自编码器的掩码预测开始成为语言理解的事实上的标准实践[15]; 因此,在21世纪20年代讨论这个问题就不那么重要了。此外,视觉掩码自编码器的成功表明,视觉SSL可以走上与语言相同的道路,这在一定程度上改变了视觉SSL,并启发了对广泛应用的掩码自编码器的研究。本研究以视觉中的蒙版自编码器为重点,主要包括三个部分。(1) 第三节总结了掩码语言建模的历史发展及其与掩码语言建模的关系; (2) 第四节讨论了视觉中的掩码建模原理,以及从不同角度对其成功的理解。(3)第5节总结了其在自然图像之外的各种应用的预训练的影响。为了便于讨论,我们加入了术语部分(即第2节)来讨论本调研中的基本术语。
视觉自监督学习
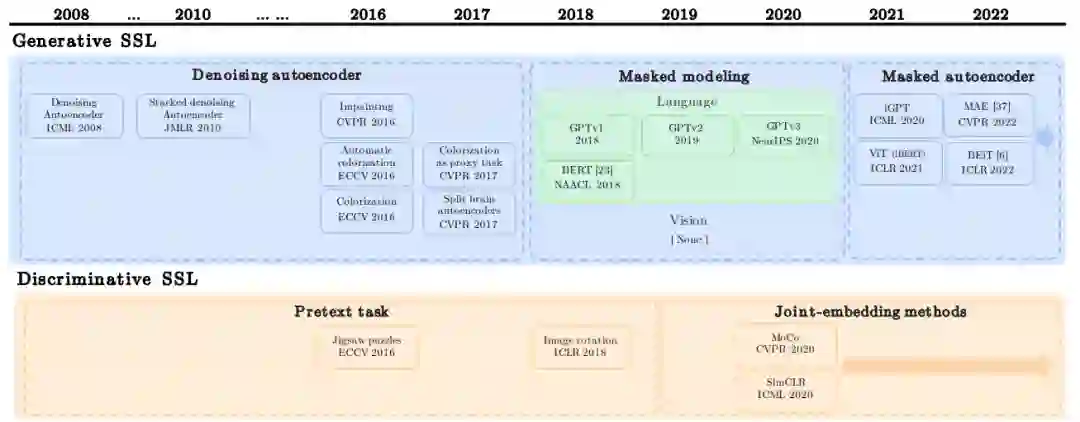
图1显示了无监督视觉预训练(包括NLP的GPT和BERT)发展的总体时间表。有趣的是,无监督视觉预训练始于2008年的生成SSL。它在2016年和2017年的复兴尝试随后被区分性SSL所掩盖,特别是在联合嵌入方法出现之后。然而,在NLP的启发下,带掩码预测的生成式SSL再次出现。