
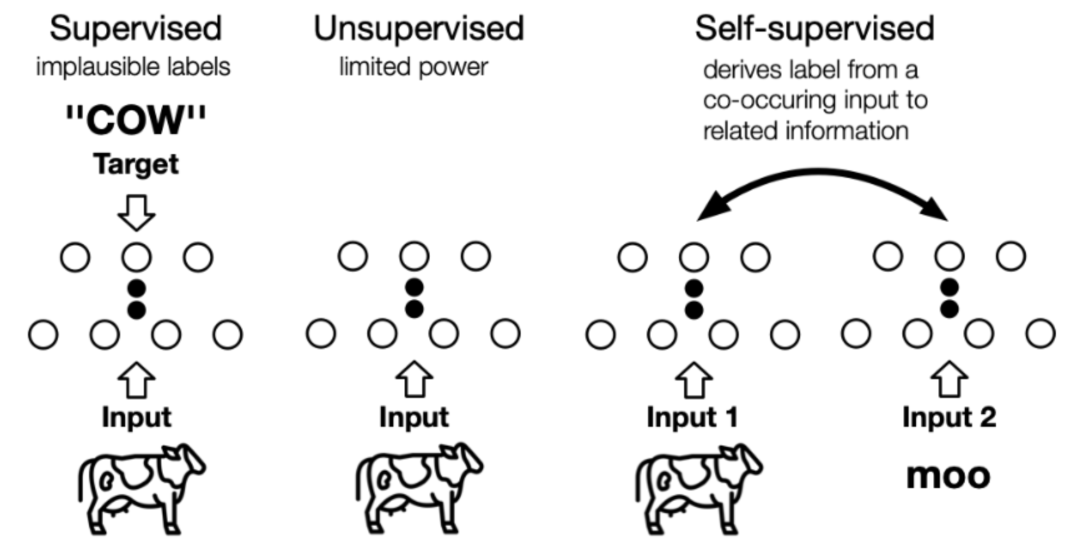
监督学习在过去取得了巨大的成功,然而监督学习的研究进入了瓶颈期,因其依赖于昂贵的人工标签,却饱受泛化错误(generalization error)、伪相关(spurious correlations)和对抗攻击(adversarial attacks)的困扰。自监督学习以其良好的数据利用效率和泛化能力引起了人们的广泛关注。本文将全面研究最新的自监督学习模型的发展,并讨论其理论上的合理性,包括预训练语言模型(Pretrained Language Model,PTM)、生成对抗网络(GAN)、自动编码器及其拓展、最大化互信息(Deep Infomax,DIM)以及对比编码(Contrastive Coding)。自监督学习与无监督学习的区别主要在于,无监督学习专注于检测特定的数据模式,如聚类、社区发现或异常检测,而自监督学习的目标是恢复(recovering),仍处于监督学习的范式中。下图展示了两者之间的区别,自监督中的“related information” 可以来自其他模态、输入的其他部分以及输入的不同形式。
成为VIP会员查看完整内容
相关内容




相关VIP内容
相关资讯
相关论文