

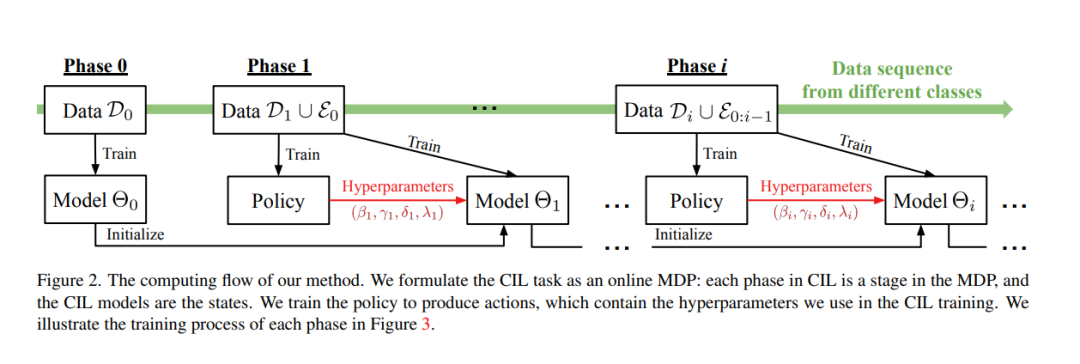
类增量学习(class incremental learning, CIL)旨在在类别数量逐步增加的情况下训练分类模型。CIL模型面临的一个内在挑战是稳定性与可塑性的权衡,即CIL模型既要保持稳定性以保留旧知识,又要保持可塑性以吸收新知识。然而,现有的CIL模型都不能在不同的数据接收设置中实现最佳权衡——通常,从一半开始训练(TFH)设置需要更大的稳定性,但从头开始训练(TFS)需要更大的可塑性**。设计了一种在线学习方法,可以在不知道先验设置的情况下自适应地优化权衡。**首先引入了影响权衡的关键超参数,例如知识蒸馏(KD)损失权重、学习率和分类器类型。然后,将超参数优化过程建模为一个在线马尔可夫决策过程(MDP)问题,并提出了一种具体的算法来求解该问题。本文采用局部估计奖励和经典bandit算法Exp3[4]来解决将在线MDP方法应用于CIL协议时存在的问题。所提出方法在TFH和TFS设置中不断改进表现最好的CIL方法,例如,与最先进的[23]相比,在ImageNet-Full上将TFH和TFS的平均精度提高了2.2个百分点。
https://www.zhuanzhi.ai/paper/1aa5db12a9fd06a275ad0b6e89be62bb
成为VIP会员查看完整内容
相关内容
Arxiv
14+阅读 · 2022年3月25日
相关VIP内容
相关资讯