
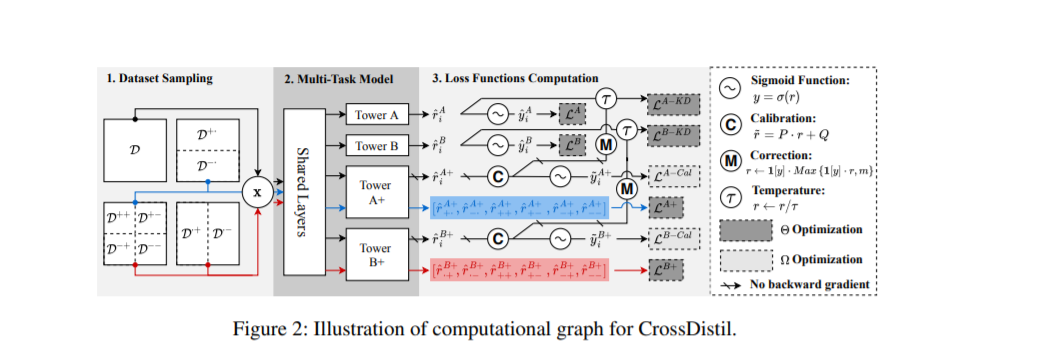
多任务学习已广泛应用于现实世界的推荐者,以预测不同类型的用户反馈。之前的大多数工作都集中在为底层设计网络架构,作为一种共享输入特征表示知识的手段。然而,由于它们采用特定于任务的二进制标签作为训练的监督信号,关于如何准确地对物品进行排序的知识并没有在任务之间完全共享。本文旨在增强多任务个性化推荐优化目标的知识迁移。我们提出了一个跨任务知识蒸馏(Cross-Task Knowledge精馏)的推荐框架,该框架由三个步骤组成。1) 任务增强: 引入具有四元损失函数的辅助任务来捕获跨任务的细粒度排序信息,通过保留跨任务一致性知识来避免任务冲突; 2) 知识蒸馏: 我们设计了一种基于增强任务的知识蒸馏方法来共享排序知识,其中任务预测与校准过程相结合; 3) 模型训练: 对教师和学生模型进行端到端训练,采用新颖的纠错机制,加快模型训练速度,提高知识质量。在公共数据集和我们的生产数据集上进行了综合实验,验证了CrossDistil的有效性和关键组件的必要性。
https://arxiv.org/abs/2202.09852
成为VIP会员查看完整内容
相关内容
Arxiv
0+阅读 · 2022年4月19日
Arxiv
0+阅读 · 2022年4月18日
Arxiv
10+阅读 · 2021年10月4日

相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2022年4月19日
Arxiv
0+阅读 · 2022年4月18日
Arxiv
10+阅读 · 2021年10月4日