深度模型,如CNN和视觉transformer,在封闭世界的许多视觉任务中取得了令人印象深刻的成就。然而,在瞬息万变的世界中,新颖的类别不断涌现,这就要求学习系统不断获取新知识。例如,机器人需要理解新的指令,而意见监测系统应该每天分析新出现的主题。**类增量学习(class incremental Learning, CIL)使学习者能够增量地吸收新类别的知识,并在所有见过的类别中构建通用分类器。**相应地,当直接用新的类实例训练模型时,一个致命的问题发生了——模型倾向于灾难性地忘记以前的特征,其性能急剧下降。在机器学习社区中,已经为解决灾难性遗忘做出了许多努力。**文中全面综述了深度类增量学习的最新进展,并从以数据为中心、以模型为中心和以算法为中心3个方面对这些方法进行了总结。**对基准图像分类任务中的16种方法进行了严格统一的评估,从经验上总结了不同算法的特点。此外,我们注意到目前的比较协议忽略了模型存储中内存预算的影响,可能会导致不公平的比较和有偏差的结果。因此,本文主张通过在评估中调整内存预算,以及几个与内存无关的性能度量,来进行公平比较。可以在https://github.com/zhoudw-zdw/CIL_Survey/获得重现这些评估的源代码。
https://www.zhuanzhi.ai/paper/38445358d39783cbab35043f719adf53
1, 引言
近年来,深度学习取得了快速的进步,深度神经网络在许多领域取得了甚至超过人类水平的表现[1],[2],[3]。深度网络的典型训练过程需要预先收集数据集,例如大规模图像[4]或文本[5]——网络对预收集的数据集进行多个epoch的训练过程。然而,在开放世界中,训练数据往往是带有流格式的[6]、[7]。由于存储限制[8],[9]或隐私问题[10],[11],这些流数据不能长时间保存,要求模型仅用新的类实例进行增量更新。这种需求催生了类增量学习(Class-Incremental Learning, CIL)领域的兴起,旨在在所有可见类之间持续构建一个整体分类器。CIL中的致命问题被称为灾难性遗忘,即直接用新类优化网络将抹去以前类的知识,并导致不可逆的性能下降。因此,如何有效抵御灾难性遗忘成为构建CIL模型的核心问题。
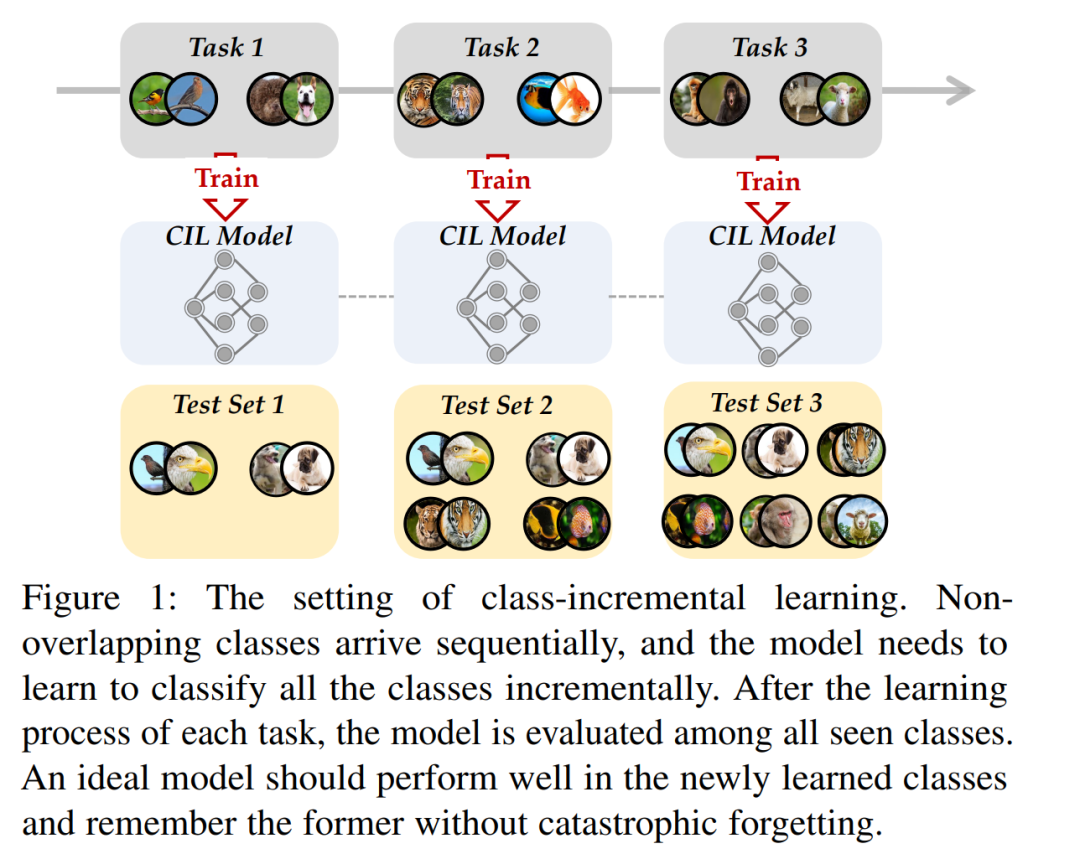
图1描述了CIL的典型设置。训练数据以流格式顺序出现。在每个时间戳中,我们可以得到一个新的训练数据集(在图中表示为“任务”),并需要使用新的类更新模型。例如,该模型在第一个任务中学习"鸟"和"狗",在第二个任务中学习"老虎"和"鱼",在第三个任务中学习"猴子"和"羊"等。然后,在所有见过的类中测试该模型,以评估其是否对它们具有区分性。一个好的模型应该在描述新类别的特征和保留之前学习的旧类别的模式之间取得平衡。这种权衡也被称为神经系统[12]中的"稳定性-可塑性困境",稳定性表示保持以前知识的能力,可塑性表示适应新模式的能力。
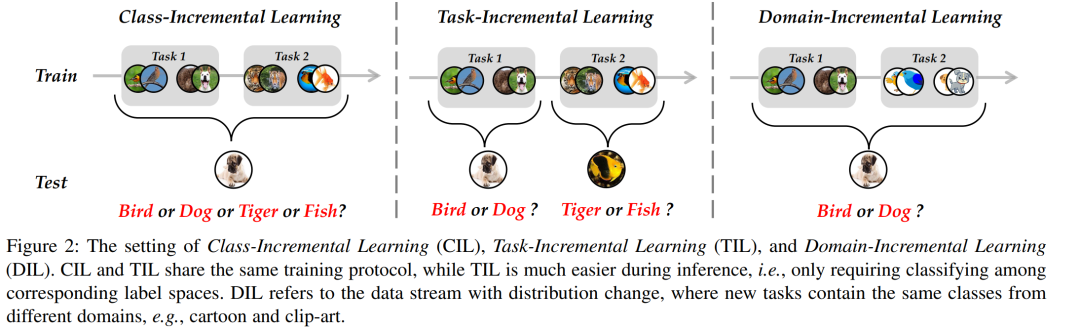
除了类增量学习之外,还有其他解决增量学习问题的细粒度设置,例如任务增量学习(TIL)和领域增量学习(DIL)。我们在图2中展示了这三个协议。TIL的设置与CIL类似,它们都观察新任务中传入的新类。然而,区别在于推断阶段,此时CIL要求模型在所有类之间进行区分。相比之下,TIL只需要在相应的任务空间中对实例进行分类。换句话说,它不需要跨任务辨别能力。因此,TIL比CIL更容易,这可以看作是CIL的一个特殊情况。另一方面,DIL集中于概念漂移或分布变化[13],[14]的场景,其中新任务包含来自不同领域但具有相同标签空间的实例。在这种情况下,新的域对应于剪贴艺术格式的图像。在本文中,我们将重点讨论CIL设置,这是开放世界中更具挑战性的场景。在深度学习[15]兴起之前,也有关于CIL的研究。典型方法试图用传统的机器学习模型来解决灾难性遗忘问题。然而,它们大多处理两个任务内的增量学习,即模型只更新了一个新阶段[16],[17],[18]。此外,数据收集和处理的快速发展要求模型能够掌握传统机器学习模型无法处理的长期、大规模数据流。相应地,具有强大表示能力的深度神经网络很好地满足了这些要求。因此,基于深度学习的CIL正在成为机器学习和计算机视觉领域的热门话题。已有一些研究讨论了增量学习问题。例如,[11]专注于任务增量学习问题,并提供了全面的综述。[19]是一份关于类增量学习领域的相关综述,但直到2020年才对方法进行讨论和评估。然而,随着CIL领域的快速发展,大量优秀的研究成果不断涌现,极大地提升了基准测试集[20]、[21]、[22]、[23]的性能。另一方面,随着视觉Transformer (ViT)[24]和预训练模型的蓬勃发展,在CIL中关于ViT的热讨论引起了社区的关注。其他的综述要么集中在[25]、[26]、[27]这一特定领域,要么缺乏最先进的[28]、[29]、[30]的性能演变。因此,迫切需要提供一份包含流行方法的最新综述,以加快CIL领域的发展。文中从以数据为中心、以模型为中心、以算法为中心三个方面对深度类增量学习方法进行了全面综述。在CIFAR100[31]和ImageNet100/1000[4]基准数据集上对不同类型的方法进行了整体比较。强调了CIL模型评估中的一个重要因素,即内存预算,并主张在预算一致的情况下对不同方法进行公平比较。相应地,用预算指标全面评估了CIL模型的可扩展性。总的来说,这项调查的贡献可以概括如下:
-
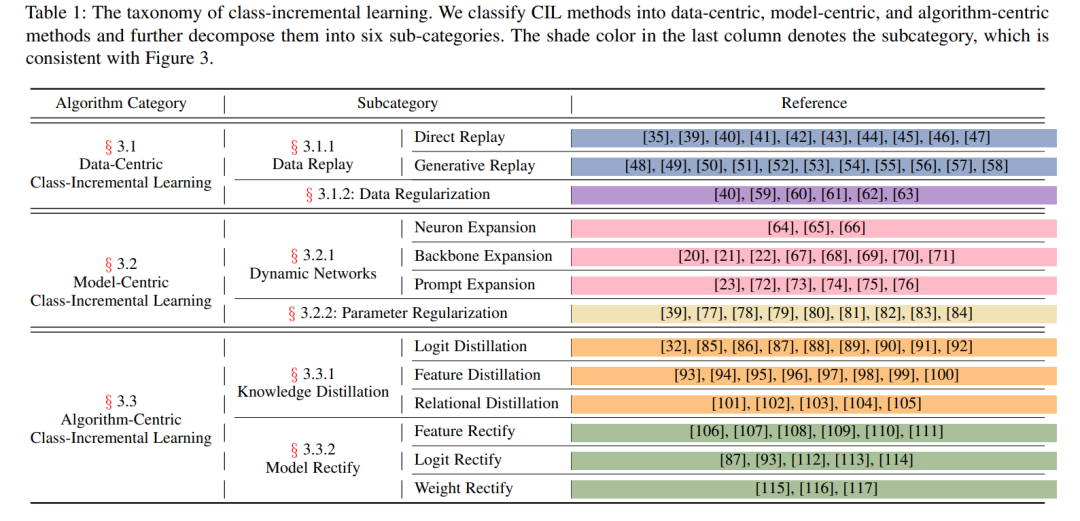
**本文对深度CIL进行了全面的综述,包括问题定义、基准数据集和不同的CIL方法族。**将这些算法按分类(表1)和时间顺序(图3)组织起来,以对最先进的技术进行整体概述。
-
**在几个公开的数据集上对不同方法进行了严格和统一的比较,包括传统的CNN支持的方法和现代ViT支持的方法。**讨论了这些见解并总结了常见的规律,以启发未来的研究。
-
为了促进实际应用,CIL模型不仅应该部署在高性能计算机上,还应该部署在边缘设备上。因此,我们主张通过强调内存预算的影响来整体评估不同方法。相应地,对给定特定预算的不同方法以及几种新的性能指标进行了全面的评估。
本文的其余部分组织如下。第2节给出了类增量学习的问题定义。之后,我们在第3节中对当前的CIL方法进行了分类组织,并在第4节中提供了全面的评估。最后,第五节总结了类增量学习的未来研究方向。类增量方法体系
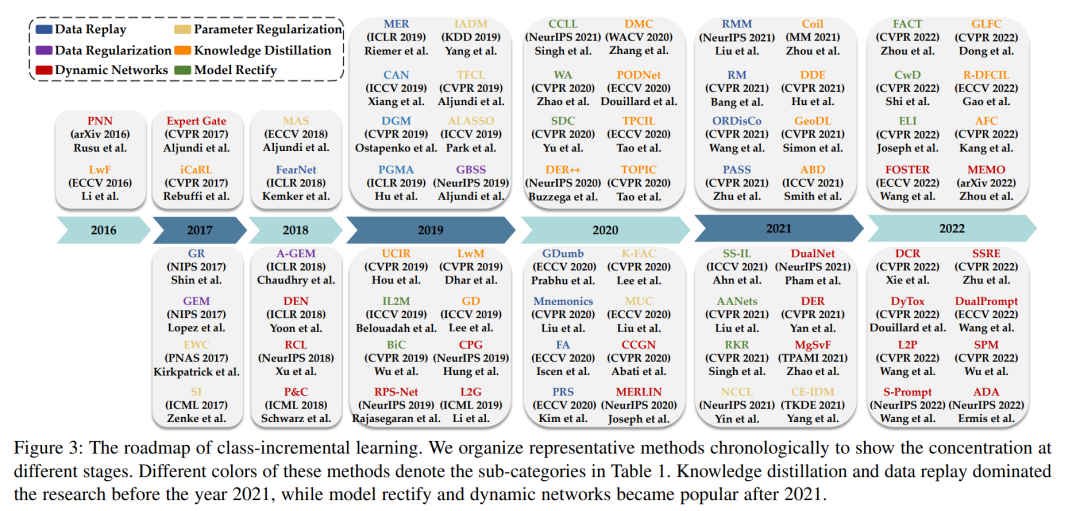
近年来,关于类增量学习的著作层出不穷,在机器学习和计算机视觉界引起了热烈的讨论。我们从以数据为中心、以模型为中心和以算法为中心三个方面对这些方法进行分类组织,如表1所示。以数据为中心的方法侧重于用样本求解CIL问题,可进一步分为数据重放和数据正则化。以模型为中心的方法,要么对模型参数进行正则化,避免漂移,要么对网络结构进行扩展,以增强表示能力。最后,以算法为中心的方法利用知识蒸馏来抵抗遗忘或纠正CIL模型中的偏差。我们在图3中按时间顺序列出了具有代表性的方法,以显示不同时期的研究重点。在接下来的章节中,我们将从这三个方面讨论CIL方法。