
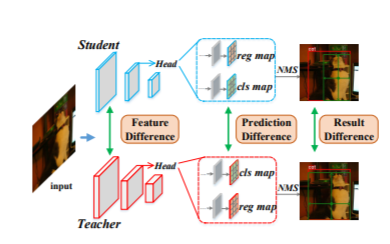
KD (Knowledge蒸馏)是一种广泛应用的技术,它将信息从繁琐的教师模型迁移到紧凑的学生模型,从而实现模型的压缩和加速。与图像分类相比,目标检测是一项更为复杂的任务,设计具体的目标检测KD方法是非简单的。在这项工作中,我们精心研究了教师和学生检测模型之间的行为差异,并得到了两个有趣的观察结果: 第一,教师和学生对他们检测到的候选框的排名差异很大,这导致了他们的精度差异。其次,教师和学生的特征响应差异和预测差异之间存在较大的差距,说明对教师的所有特征地图进行同等的模仿是提高学生准确性的次优选择。在此基础上,我们分别提出了Rank mimics (RM)和predictive -guided Feature Imitation (PFI)两种方法来提取一级检测器。RM将教师的候选箱排序作为一种新的知识提炼形式,其表现始终优于传统的软标签蒸馏。PFI试图将特征差异与预测差异联系起来,使特征模仿直接有助于提高学生的准确性。在MS COCO和PASCAL VOC基准上,在不同的探测器上进行了大量的实验,以验证我们的方法的有效性。具体来说,ResNet50的RetinaNet在MS COCO中实现了40.4%的mAP,比其基线高3.5%,也优于以往的KD方法。
https://www.zhuanzhi.ai/paper/b867f1778005b17a1547c8f74353158b
成为VIP会员查看完整内容
相关内容
Arxiv
13+阅读 · 2020年7月3日
Arxiv
6+阅读 · 2018年3月8日


相关VIP内容
相关资讯
相关论文
Arxiv
13+阅读 · 2020年7月3日
Arxiv
6+阅读 · 2018年3月8日