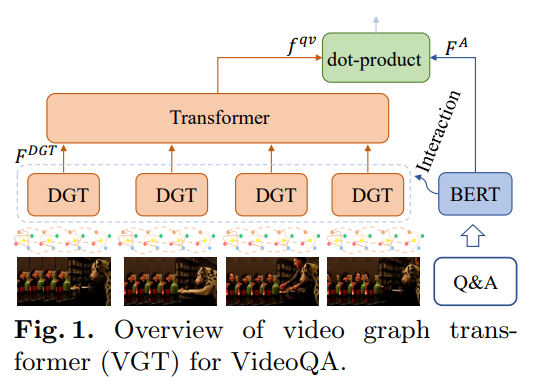
【ECCV2022】用于视频问题回答的视频图Transformer

专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“VQAT” 就可以获取《【ECCV2022】用于视频问题回答的视频图Transformer》专知下载链接



登录查看更多
相关内容

UniViLM: A Unified Video and Language Pre-Training Model for Multimodal Understanding and Generation
Arxiv
19+阅读 · 2020年2月15日


相关VIP内容
相关资讯
相关论文
UniViLM: A Unified Video and Language Pre-Training Model for Multimodal Understanding and Generation
Arxiv
19+阅读 · 2020年2月15日