Transformer如何用于视频?最新「视频Transformer」2022综述
视频Transformer最新综述论文

Transformer模型在建模长范围交互方面取得了巨大的成功。然而,他们的规模与输入长度的平方和缺乏归纳偏差。在处理高维视频时,这些限制可能会进一步加剧。正确的视频建模,可以跨度从几秒到几小时,需要处理长范围交互。这使得Transformer成为解决视频相关任务的一个很有前途的工具,但还需要一些调整。虽然之前也有研究《Transformer》在视觉任务方面的进展的工作,但没有一篇是针对特定视频设计的深入分析。在本综述中,我们分析和总结了用于视频数据建模的Transformer的主要贡献和趋势。具体地说,我们深入研究了视频是如何嵌入和标记化的,发现了一个非常广泛的使用大型CNN主干来降低维数的方法,以及主要使用补丁和帧作为标记。此外,我们研究了如何调整Transformer层以处理更长的序列,通常是通过减少单个注意力操作中的令牌数量。此外,我们还分析了用于训练视频Transformer的自监督损耗,迄今为止,这些损耗大多局限于对比方法。最后,我们探讨了其他模态是如何与视频整合在一起的,并对视频Transformer最常用的基准(即动作分类)进行了性能比较,发现它们在等效FLOPs的情况下优于3D CNN,且没有显著的参数增加。
https://arxiv.org/abs/2201.05991
引言
Transformers是[1]中首次提出的最新系列模型。这些架构最初是为了替换机器翻译设置中的循环层而设计的,现在已经很快被用于建模许多其他数据类型[2]、[3]、[4],包括图像[5]、[6]、[7]、[8]和视频[9]、[10]、[11]、[12]、[13]、[14]。Transformer背后的关键成功在于其通过自注意力(SA)操作实现的非局部令牌混合策略。非局部操作在[15]中提出,是对非局部均值操作[16]的泛化。它基于所有元素之间的交互来演化输入表示。这些相互作用是通过一对相似函数来调节的,该函数衡量每个元素对其他元素的贡献。与全连接(FC)层不同,非局部操作不需要权重:输入之间的关系不需要学习,而是完全依赖于输入表示。尽管它们取得了成功,但SA的本质导致transformer对序列长度T的缩放效果很差。特别是,由于对亲和计算,SA的复杂度为O(t2)。此外,transformer没有任何归纳偏差,这可能是一个理想的特性,但它也会阻碍学习,除非[7]使用大量数据。
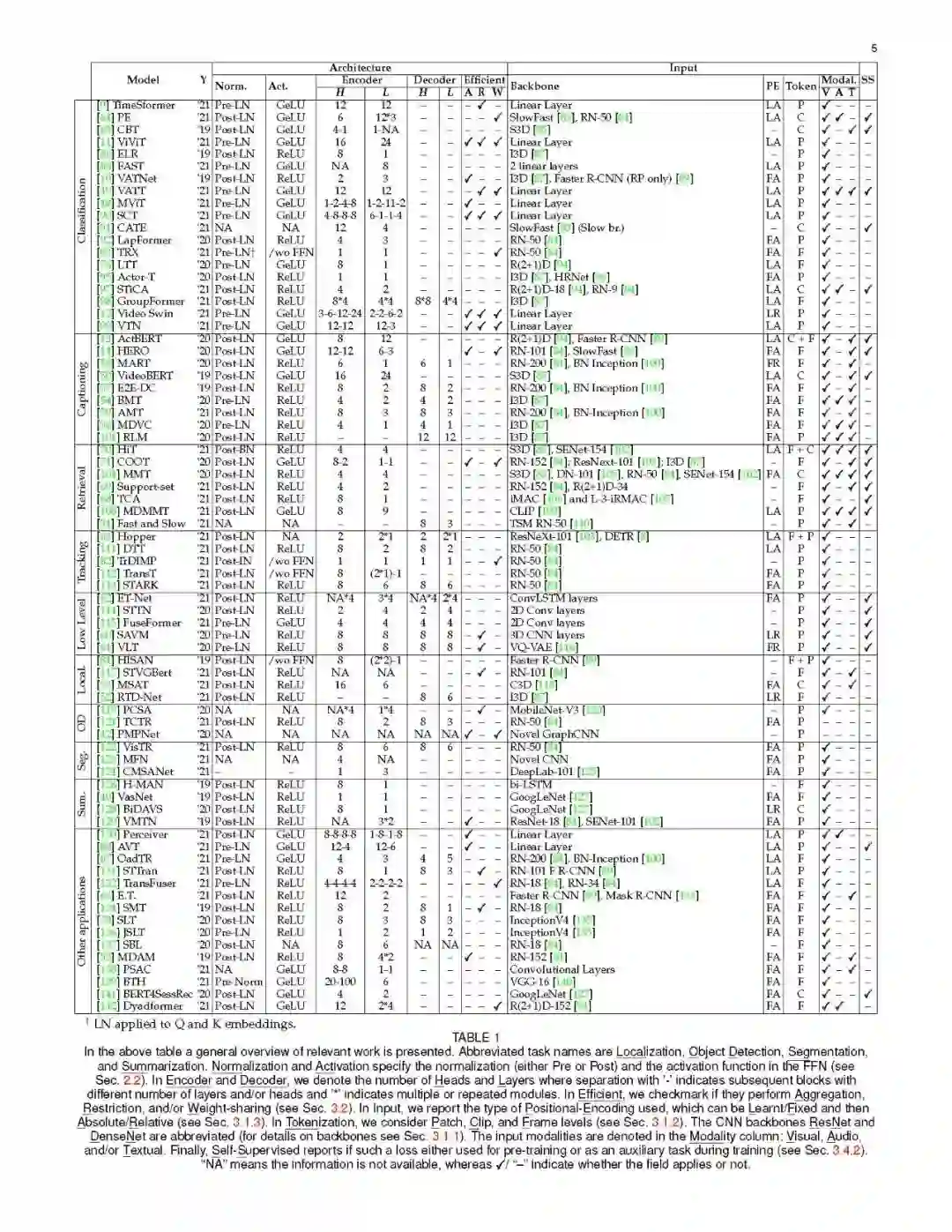
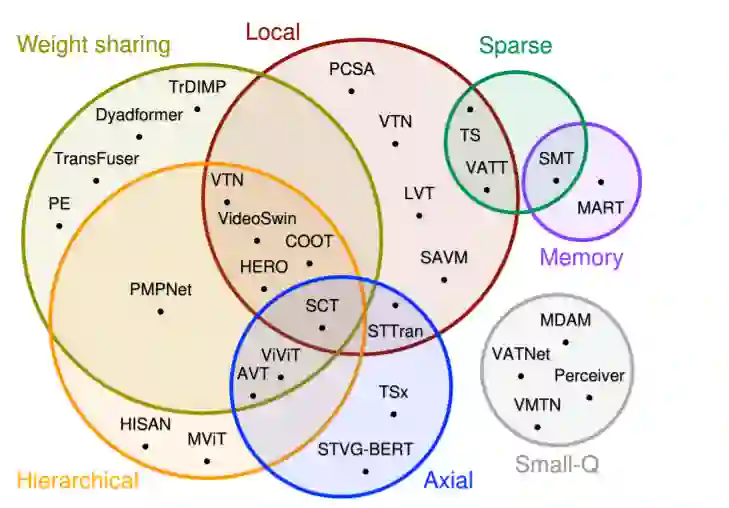
最近Transformer工作的激增,让跟踪最新的进展和趋势变得复杂起来。最近的调研试图通过分析和总结《Transformer》的总体架构设计选择来填补这一空白,主要集中在NLP[18],或高效的设计,如[19]或[20]。虽然一些人已经广泛地调研了视觉的进展,例如[21],[22],[23],[24]和Vision-Language transformer[25],但他们没有对视频模型进行深入的分析。[26]的调研集中于视频和语言Transformer的预训练,但是他们讨论了一些架构选择,并没有涵盖一般的视频趋势。视频Transformer (vt)可以找到与其他Transformer设计的共同点(特别是在图像领域),但视频固有的大维度将加剧Transformer的局限性,需要特殊处理。额外的时间维度还需要不同的嵌入、标记化策略和架构。最后,视频媒体通常与其他模态配对(例如,它很自然地伴随着音频),这使得它特别容易用于多模态设置。
视频。本工作的重点是全面分析用于视频数据建模的Transformer架构的最新进展。请注意,在Transformer层建模之前,使用传统(非Transformer)架构将视频映射到其他结构化形式(例如,接头[27]或语音[28])的工作不在我们的范围之内。我们对使用(时间)视觉特征作为SA层输入的模型特别感兴趣。我们分析了文献采用这些模型的方式,使之能够处理视频的内在复杂性以及其他可选模态。然而,我们确实考虑在使用Transformer层之前利用某些CNN架构将视频数据嵌入到低维空间的工作(参见第3.1.1节)。
Transformers。与基于位置的体系架构(如CNN)不同,Transformer在每一层对数据的全局交互进行建模。然而,有一个广泛的基于全局的架构。我们关注的是将SA以非局部运算[15]的内嵌高斯变量形式,加上额外的归一化因子的工作(见式(1))。已有文献将其他形式的注意力视为SA[29],[30],[31],[32],但这些文献通常使用FC层而不是点积来计算注意力权重。我们认为这些超出了本次调研的范围。此外,与Transformers并行的研究方向还采用SA或等效的内嵌高斯版本的非局部算子来处理计算机视觉任务。例如,图注意力网络,如[33]和[34],或关系网络,如[35]和[36]。类似地,我们也发现它们被用于增强CNN主干,通过添加中间层[15]、[37]、[38]、[39],或者通过增强输出表示[40]、[41]、[42]。我们很高兴地看到,在这么多不同的研究方向都采用了非局部操作。不过,在本工作中,我们只关注Transformer体系结构,并将非本地操作集成到不同体系结构中的各种方式留给未来的工作进行比较。
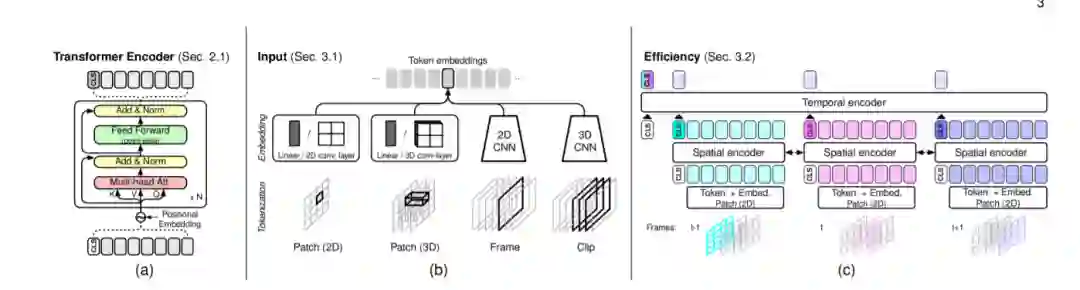
视频Transformers(vt)的通用框架。在(a)中,我们展示了一个普通的Transformer Encoder[1](在第2.1节中概述);在(b)中,我们展示了不同的标记化和嵌入策略,具体见3.1节;在(c)中,我们展示了一种常见的分层Transformer设计,它分解了视频片段的空间和时间交互。这些和其他视频设计在第3.2节中有描述。
视频Transformer
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“TR24” 就可以获取《Transformer如何用于视频?最新「视频Transformer」2022综述》专知下载链接






