【AAAI2022】(2.5+1)D时空场景图用于视频问答

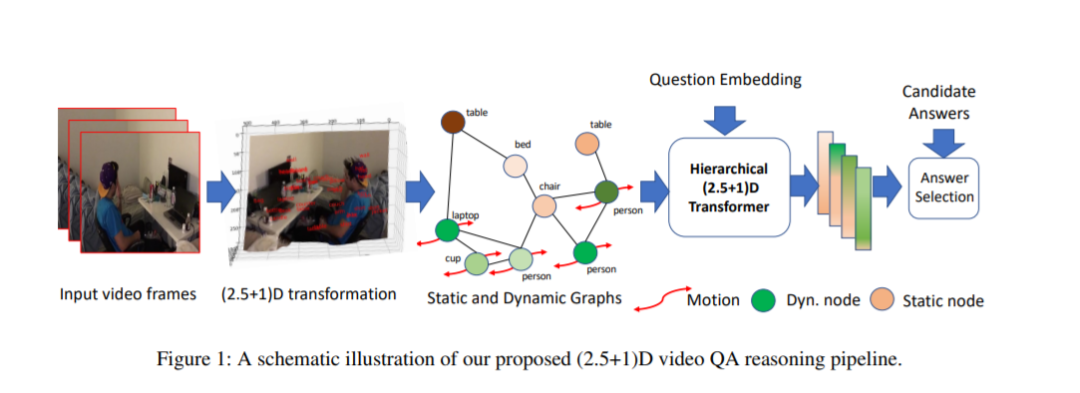
用于基于视频的推理任务(如视频问答)的时空场景图方法通常为每一帧视频构建这样的图。这种方法通常忽略了一个事实,即视频本质上是发生在3D空间中的事件的2D“视图”序列,并且3D场景的语义也因此能够在帧间传递。利用这一观点,我们提出了一个(2.5+1)D场景图表示,以更好地捕捉视频中的时空信息流。具体来说,我们首先创建2.5D(伪3D)场景图,通过使用现成的2D到3D转换模块将每一帧2D画面转换成推断出的3D结构,然后我们将视频帧注册到共享的(2.5+1)D时空空间中,并将其中的每个2D场景图置于地面。这样一个(2.5+1)D图被分离成一个静态子图和一个动态子图,对应于其中的对象是否通常在世界中移动。动态图中的节点被运动特征所丰富,捕捉到它们与其他图节点的交互。接下来,在视频QA任务中,我们提出了一种新的基于Transformer的推理管道,将(2.5+1)D图嵌入到一个时空层次潜在空间中,在该空间中,子图及其交互以不同的粒度捕获。为了证明该方法的有效性,我们在NExT-QA和AVSD-QA数据集上进行了实验。我们的结果表明,我们提出的(2.5+1)D表示法导致了更快的训练和推理,而我们的分层模型在视频QA任务上的表现优于目前的技术水平。
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“25D” 就可以获取《【AAAI2022】(2.5+1)D时空场景图用于视频问答》专知下载链接



登录查看更多
相关内容
Arxiv
0+阅读 · 2022年4月19日
Arxiv
0+阅读 · 2022年4月19日
Arxiv
1+阅读 · 2022年4月15日



相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2022年4月19日
Arxiv
0+阅读 · 2022年4月19日
Arxiv
1+阅读 · 2022年4月15日