【NeurIPS2021】自我挖掘:视频问答中对样本进行孪生采样和推理

自我挖掘:视频问答中对样本进行孪生采样和推理
Learning from Inside: Self-driven Siamese Sampling and Reasoning for Video Question Answering
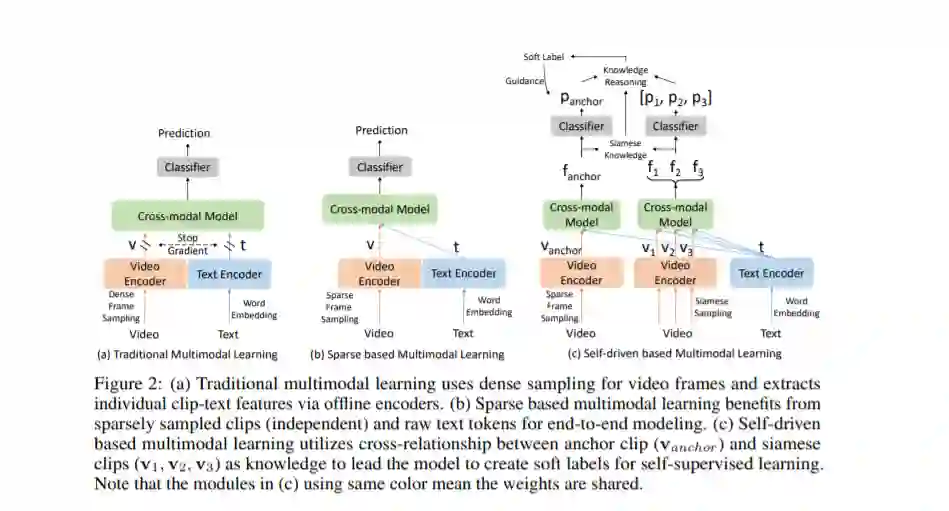
论文摘要:视频问答任务需要根据语言线索的组合语义,获取并使用视频中的视觉信号的时域和空域特征,从而生成回答。现有的一些工作从视频中提取一般的视觉信息以及运动特征来表示视频内容,并设计了不同的注意力机制来整合这些特征。这些方法注重于如何更好地理解视频的整体内容,但这样容易忽略了视频段中的细节。也有一些研究人员探究了如何通过对视频的视觉和语言信息进行语义层面上的特征对齐。但是这些工作都忽略了同一个视频中的上下文之间的关联。为了解决上诉问题,我们提出了此基于自驱动孪生采样和推理的框架,并将其用于提取相同视频的不同视频段中的上下文语义信息,用于增强网络的学习效果。本方法在 5 个公开的数据集上面实现了最优的效果。
https://papers.nips.cc/paper/2021/file/dea184826614d3f4c608731389ed0c74-Paper.pdf
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“S3R” 就可以获取《【NeurIPS2021】自我挖掘:视频问答中对样本进行孪生采样和推理》专知下载链接



登录查看更多
相关内容
专知会员服务
16+阅读 · 2022年4月11日
Arxiv
0+阅读 · 2022年4月17日
Arxiv
15+阅读 · 2021年5月19日
Arxiv
10+阅读 · 2019年9月15日



相关VIP内容
专知会员服务
16+阅读 · 2022年4月11日
相关资讯
相关论文
Arxiv
0+阅读 · 2022年4月17日
Arxiv
15+阅读 · 2021年5月19日
Arxiv
10+阅读 · 2019年9月15日