

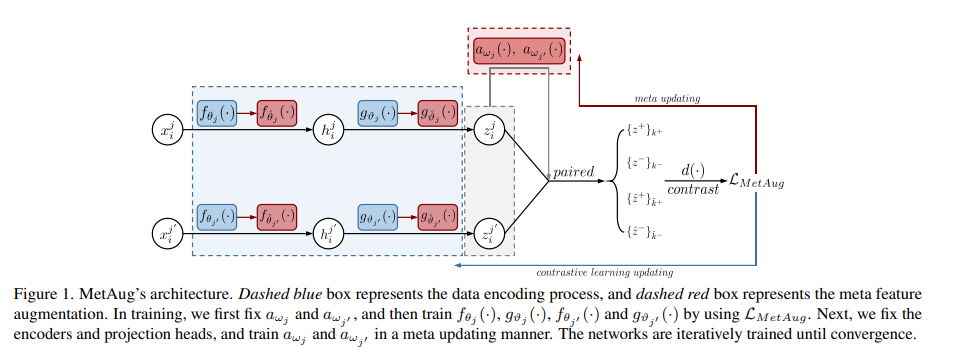
什么对对比学习很重要?我们认为对比学习在很大程度上依赖于有信息量的特征,或“困难的”(正例或负例)特征。早期的方法通过应用复杂的数据增强和大批量或内存库来包含更多有信息量的特征,最近的工作设计了精细的采样方法来探索有信息量的特征。探索这些特征的关键挑战是源多视图数据是通过应用随机数据增强生成的,这使得始终在增强数据中添加有用信息是不可行的。因此,从这种增强数据中学习到的特征的信息量是有限的。**在本文中,我们提出直接增强潜在空间中的特征,从而在没有大量输入数据的情况下学习判别表示。**我们执行元学习技术来构建增强生成器,通过考虑编码器的性能来更新其网络参数。然而,输入数据不足可能会导致编码器学习坍塌的特征,从而导致增强生成器出现退化的情况。我们在目标函数中进一步添加了一个新的边缘注入正则化,以避免编码器学习退化映射。为了在一个梯度反向传播步骤中对比所有特征,我们采用了优化驱动的统一对比损失,而不是传统的对比损失。根据实验验证,我们的方法在几个基准数据集上获得了最先进的结果。
https://www.zhuanzhi.ai/paper/31925f8729fad66bf497d7f85ba17dd6
成为VIP会员查看完整内容
相关内容

Arxiv
11+阅读 · 2021年12月16日
Arxiv
15+阅读 · 2020年12月3日


相关VIP内容
相关资讯
相关论文
Arxiv
11+阅读 · 2021年12月16日
Arxiv
15+阅读 · 2020年12月3日