

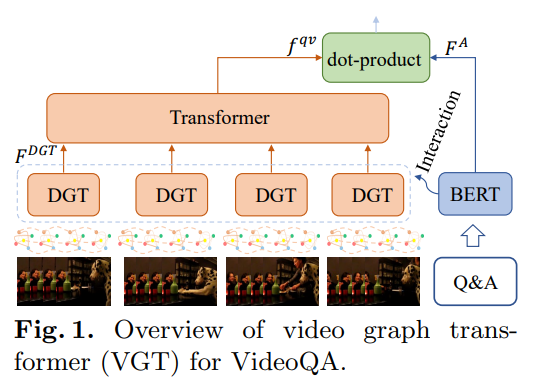
本文提出了一种用于视频问答(VideoQA)的视频图形转换(VGT)模型。VGT的独特性有两个方面: 1) 它设计了一个动态图transformer模块,通过显式捕获视觉对象、它们的关系和动态来编码视频,用于复杂的时空推理; 2) 利用解纠缠的视频和文本Transformer进行视频和文本之间的相关性比较来进行QA,而不是使用纠缠的交叉模态Transformer进行答案分类。视觉-文本通信是通过附加的跨模态交互模块完成的。通过更合理的视频编码和QA解决方案,我们表明VGT在无预训练场景下可以在挑战动态关系推理的VideoQA任务上实现比现有技术更好的性能。它的性能甚至超过了那些用数百万外部数据预训练的模型。我们进一步表明,VGT也可以从自监督跨模态预训练中获益很多,但数据的数量级更小。这些结果清楚地证明了VGT的有效性和优越性,并揭示了它在数据效率更高的预训练方面的潜力。通过全面的分析和一些启发式的观察,我们希望VGT能够推动VQA研究从粗的识别/描述转向现实视频中细粒度的关系推理。我们的代码可在https://github.com/sail-sg/VGT获得
成为VIP会员查看完整内容

相关内容
相关主题

相关VIP内容
相关资讯