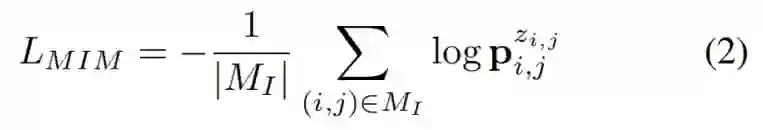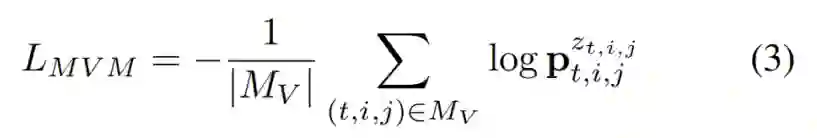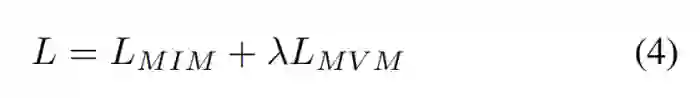点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
转载自:机器之心
复旦大学、微软 Cloud+AI 的研究者将视频表征学习解耦为空间信息表征学习和时间动态信息表征学习,提出了首个视频 Transformer 的 BERT 预训练方法 BEVT。该研究已被 CVPR 2022 接收。
在自然语言处理领域,采用掩码预测方式的 BERT 预训练助力 Transformer 在各项任务上取得了巨大成功。近期,因为 Transformer 在图像识别、物体检测、语义分割等多个计算机视觉任务上取得的显著进展,研究人员尝试将掩码预测预训练引入到图像领域,通过预测被掩码图像块的离散视觉 token 或像素值实现图像表征学习。然而,目前还鲜有研究探索视频 Transformer 的 BERT 预训练方法。
不同于静态图像,除了空间先验信息,视频中包含着运动、物体间交互等丰富的动态信息,因此相比于图像表示学习,视频表征学习更为复杂、困难。现有的视频 Transformer 往往依赖大规模静态图像数据(如 ImageNet)上预训练的权重,并没有考虑在视频数据集上通过自监督方法学习时间动态信息。为了在下游视频理解任务上取得良好的性能,视频 Transformer 需要同时学习空间先验信息和时间动态信息。
基于上述观点,来自复旦大学、微软 Cloud+AI 的研究者将视频表征学习解耦为空间信息表征学习和时间动态信息表征学习,提出了首个视频 Transformer 的 BERT 预训练方法 BEVT。
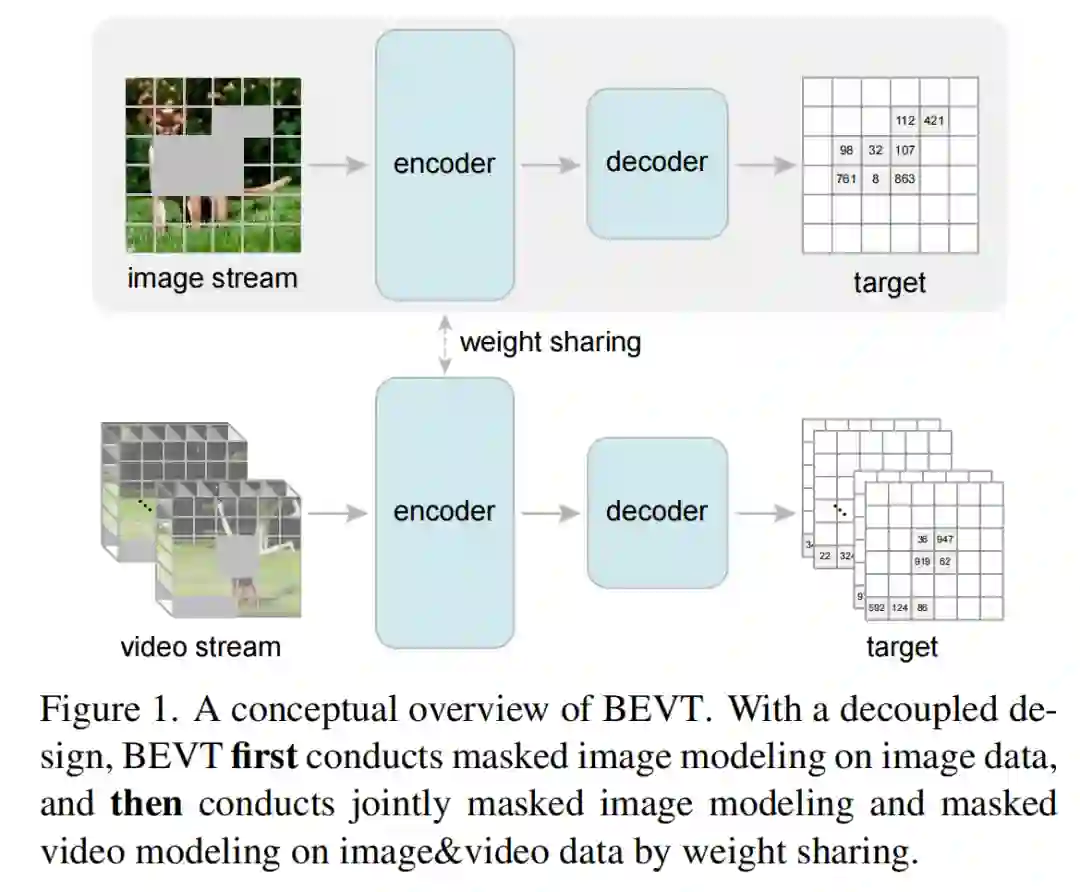
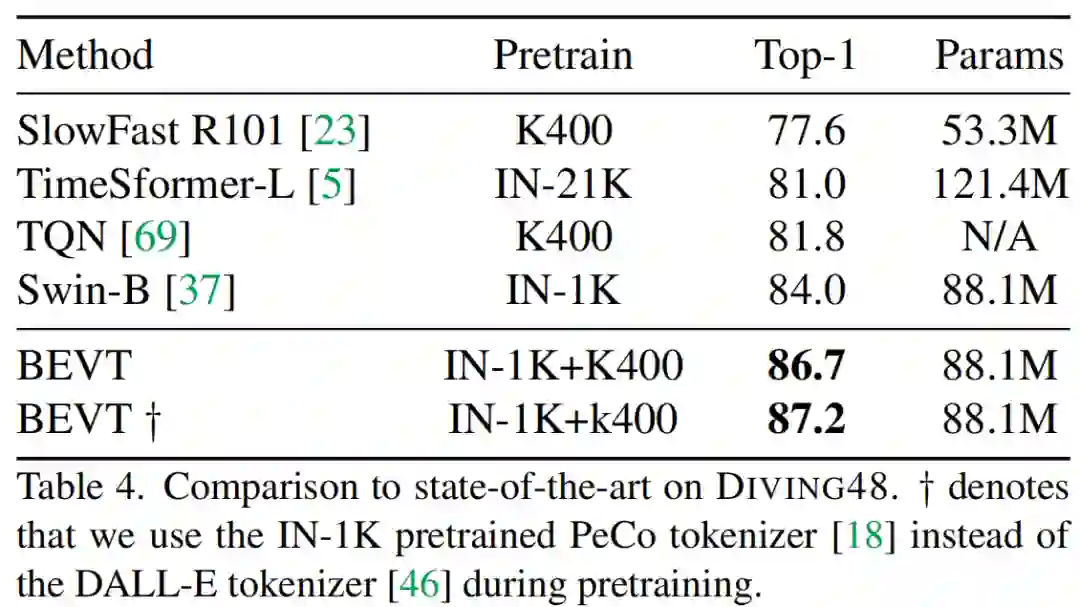
BEVT 是由图像通路和视频通路组成的双路联合自监督预训练框架。图像通路通过预测被掩码图像块的离散视觉 token 来学习空间建模,视频通路通过预测被掩码三维视频通道的离散视觉 token 来学习时间建模,而通过模型参数共享实现的双路联合预训练则使得视频 Transformer 模型能够高效地同时学习到上述两种能力。经过 ImageNet-1K 和 Kinetics-400 上的图像 - 视频联合自监督预训练后,使用 VideoSwin-Base 主干的 BEVT 在迁移到多种视频理解下游任务上时都取得了优于全监督预训练、对比学习预训练和单流预训练的结果;其中在 Something-Something-v2 和 Diving48 上分别取得了 71.4% 和 87.2% 的 Top-1 准确率,优于许多先进的视频 Transformer 模型。
![]()
BEVT: BERT Pretraining of Video Transformers
对于视频理解任务,不同的视频之间存在着很大差异,对不同视频进行类别预测所依赖的关键信息(即空间或时间线索)有着显著区别。例如,Kinetics 等数据集中的动作大多属于类似 “涂口红” 这种仅需空间知识即可完成预测的类别,因此使用二维特征就可以在相对静态的 Kinetics 数据集上取得较好的性能;而对于 Something-Something 和 Diving48 等数据集,时间动态信息则更为关键(例如区分多种细粒度跳水动作)。
BEVT 的目标是通过自监督方法学习对相对静态视频和动态视频都有效的视频表征,从而在迁移到不同视频数据集上时都能取得良好的性能。这意味着视频 Transformer 需要同时学习到良好的空间信息表示和时间动态信息表示。
![]()
此外,相比于图像预训练,在大规模视频数据集上从头进行预训练需要消耗大量计算资源和时间。因此,为了高效地学习在不同视频上均有效的视频表征,BEVT 将自监督视频表征学习解耦为在图像数据上进行的空间表征学习和在视频数据上进行的时间动态信息表征学习。这两种表征学习具体实现为一个同时在图像数据和视频数据上进行联合训练的双路架构,并分别通过一种 BERT 的掩码预测自监督任务进行训练。
双路框架中的自监督表征学习 —— 掩码图像建模和掩码视频建模
BEVT 采用 BERT objective,在图像数据和视频数据上分别执行掩码图像建模任务(Masked Image Modeling)和掩码视频建模任务(Masked Video Modeling),其中掩码图像建模训练视频 Transformer 学习空间先验知识,掩码视频建模则帮助视频 Transformer 学习视频中的时间动态信息表示。对于图像通路,图像会被切分为若干 patch 作为输入 token,而掩码图像建模的训练目标是从掩码输入中恢复对应的离散视觉 token。对于视频通路,类似地,视频会被切分为若干 3D patches,掩码视频建模的目标也是从掩码三维输入中恢复对应的离散视觉 token。根据图像 Transformer 预训练方法 BEiT,BEVT 也使用预训练的 VQ-VAE 将连续图像内容转换为离散视觉 token,作为自监督预训练任务的预测目标。
图像通路和视频通路采取不同的掩码策略。对于掩码图像建模任务,使用 blockwise masking 方式。对于掩码视频建模任务,则将 blockwise masking 方式扩展为了适用于时空三维输入的 tube masking 方式。
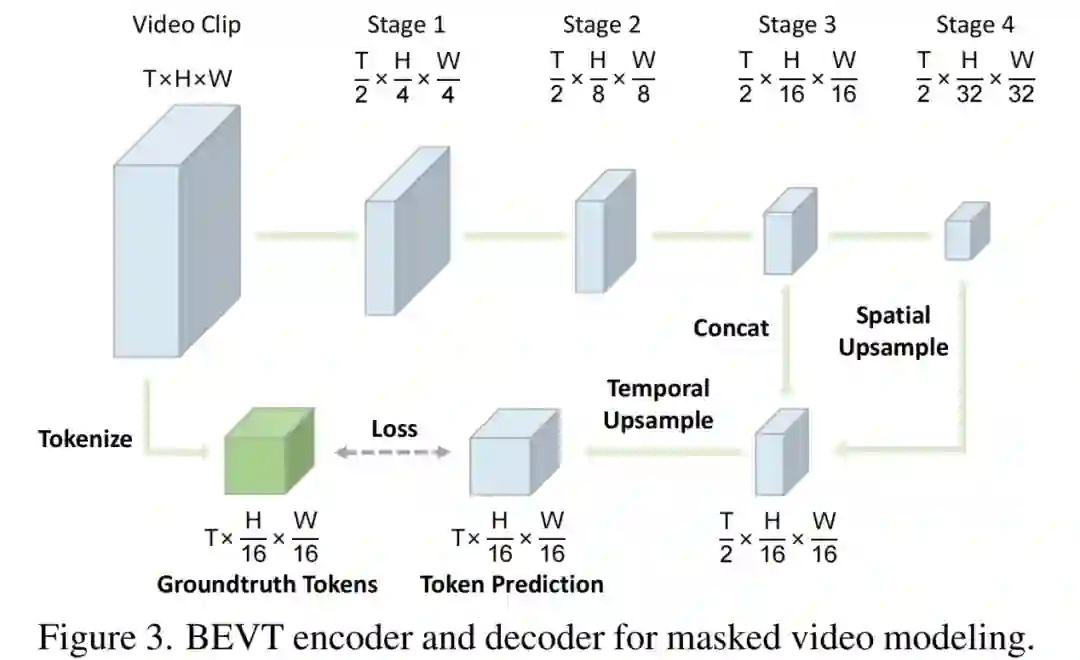
BEVT 包含了图像通路和视频通路,而它们各自包含一个编码器 - 解码器模型架构。BEVT 使用 Video Swin Transformer 作为图像通路和视频通路的编码器,进行自监督表征学习。由于 Video Swin Transformer 是从 Swin Transformer 扩展而来的层次化架构,token 序列组成的特征图会在时空维度上被降采样。
为了将 Transformer 所提取的特征图转换为和 Groundtruth 视觉 token 数量相匹配的尺寸,研究者还为图像通路和视频通路分别设计了一个轻量化解码器。以视频通路为例,解码器先使用反卷积层对 Video Swin stage 4 输出的特征图进行空间上采样,然后和 stage 3 输出的特征图进行特征维度上的拼接;之后使用另一个反卷积层进行时间上采样,将特征图恢复到合适的尺寸;最后使用一个线性分类器输出各个位置离散视觉 token 的预测。图像通路解码器的设计与之相似,只是移除了时间上采样模块。
![]()
在 BEVT 的双路训练中,掩码图像建模和掩码视频建模的目标都是最大化掩码位置对应的 Groundtruth 视觉 token 的对数似然:
![]()
![]()
![]()
由于在大规模视频数据上从头开始预训练视频 Transformer 十分低效,BEVT 首先在 ImageNet-1K 上自监督预训练图像通路,使模型学习到良好的空间表征;之后再用图像通路模型初始化视频通路模型,进行双路联合自监督训练,其中掩码图像建模任务使 Transformer 模型保留了空间信息表征能力,掩码视频建模任务使模型学习如何提取视频中的时间动态信息。这种策略不仅使得 BEVT 更加高效,而且使得预训练得到的模型能够对不同类型的视频提取不同的判别性特征。
图像 - 视频双路框架的 Transformer 权重共享机制
为了使得同一套视频 Transformer 模型权重能够同时受益于图像通路和视频通路预训练,在双路联合训练时,图像通路编码器和视频通路编码器将共享绝大部分模型权重。这种权重共享机制的实现主要得益于 Transformer 模型的良好性质 —— 自注意力模块和 FFN 的权重都与输入 token 序列的长度无关。
BEVT 所使用的 Video Swin Transformer 本是用于提取视频特征的,研究者设计了以下策略来使其权重能够用于图像通路的计算:
图像通路使用 2D patch 划分方式,而视频通路使用 3D patch 划分方式;图像通路和视频通路采用独立的 patch embedding 层分别将 2D patch 和 3D patch 投影到相同维度。
对于图像通路,将 Video Swin Transformer 自注意力机制中的 3D shifted local window 转变为 2D 版本(即 Swin Transformer 中的方式),此时图像通路使用三维相对位置编码中相对时间距离等于 0 的子矩阵作为二维相对位置编码,而其他自注意力模块权重可以完全共享。权重共享机制使得图像通路和视频通路的联合预训练能够真正优化一个近乎统一的 Transformer 编码器。
在预训练阶段,BEVT 的图像通路在 ImageNet-1K 数据集上进行训练,视频通路在 Kinetics-400 数据集上进行训练,编码器采用 Video Swin-Base 作为主干。预训练得到的 Video Swin Transformer 编码器将被迁移到多种视频识别任务(Kinetics-400, Something-Something v2 和 Diving48)上进行微调和测试。
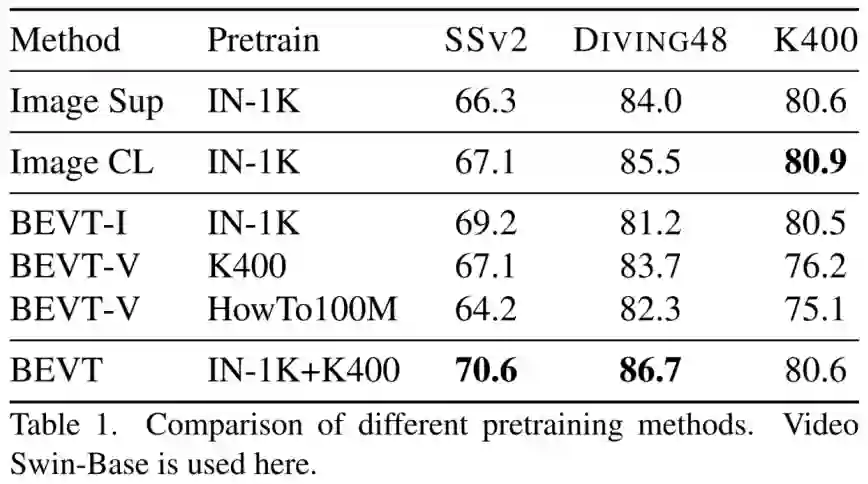
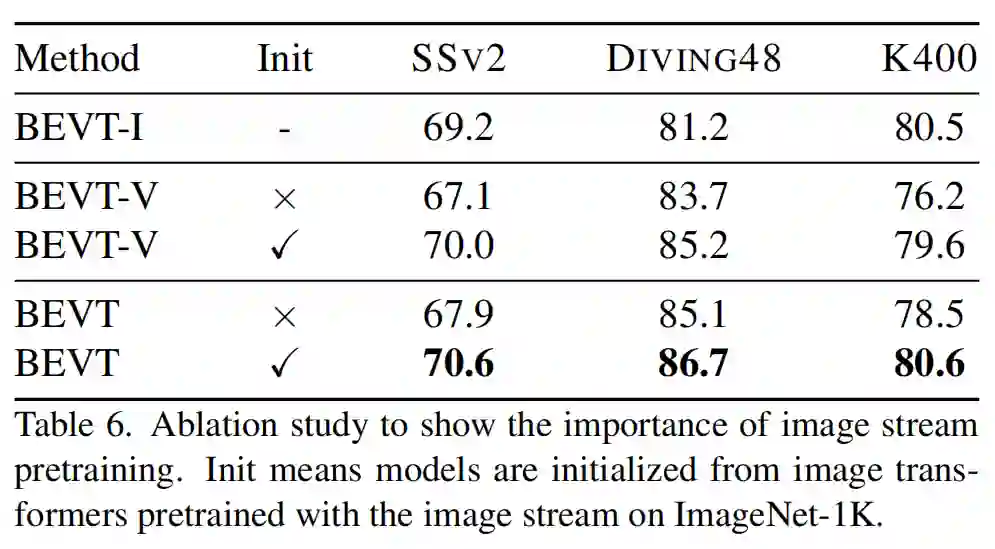
为了说明 BEVT 作为视频 Transformer 预训练方式的有效性,研究者在多种视频下游任务上全面对比了 ImageNet 全监督预训练(Image Sup),对比学习预训练(Image CL),图像通路预训练(BEVT-I),视频通路预训练(BEVT-V)这 4 种 baseline。
实验结果表明,BEVT 在 Something-Something v2 和 Diving48 上都要显著优于全监督预训练(Top-1 准确率分别高 4.3% 和 2.7%)和对比学习预训练,而在 Kinetics-400 上则取得了与 2 种 baseline 相当的结果。
相比于单流预训练,BEVT 的双路联合预训练在 3 个下游任务上都取得了更好的性能;其中在大规模视频数据集上从头进行视频通路预训练的结果明显弱于双路联合预训练,这进一步说明了 BEVT 中解耦设计和联合训练的有效性与高效性。
![]()
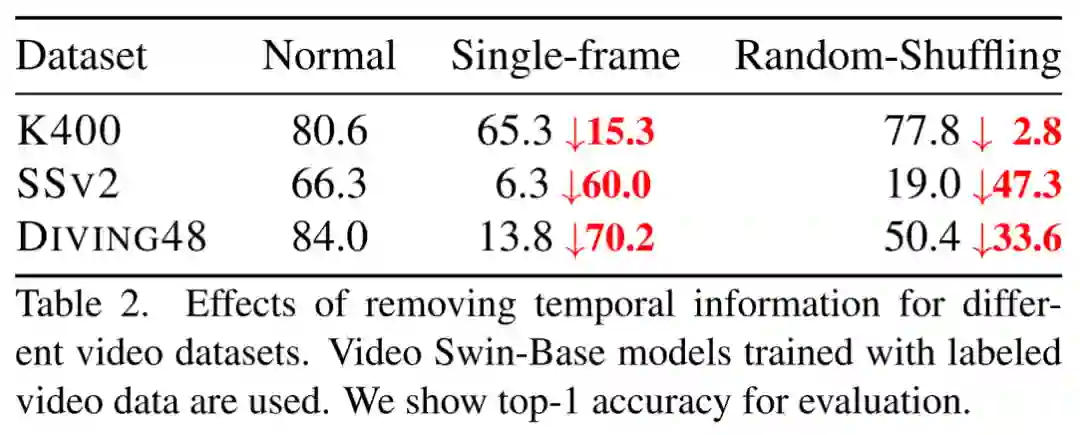
为了进一步理解 BEVT 和其他预训练 Baseline 在不同数据集上的迁移性能差异,研究者设计实验探究了 3 种视频识别下游任务对时间信息的依赖程度。将 Video Swin Transformer 在三种视频数据集上进行测试时,研究者尝试通过 2 种方式将视频输入中的时间信息移除:(1)Single-frame:使用其中 1 个视频帧代替视频片段中其他帧;(2)Random-Shuffling:在时间维度上随机打乱视频帧输入顺序。
研究者发现,移除时间信息对 Kinetics-400 的预测结果影响较小,而对 Something-Something v2 和 Diving48 的预测结果影响相当大。这说明大部分 Kinetics-400 视频仅需通过空间信息线索即可被正确识别,而时间动态信息则对于 Something-Something v2 和 Diving48 视频的识别非常重要。因此,对于空间信息线索占主导地位的数据集(如 Kinetics-400),大规模图像数据集上的预训练便可带来可观的性能,额外的视频通路预训练对性能提升影响不大;而对于十分依赖时间动态信息的数据集(如 SSv2 和 Diving48),BEVT 中视频通路预训练的作用十分关键。
这项实验说明不同视频的识别确实依赖不同种类的信息线索。为了能够在不同视频数据集上都取得良好的性能,图像通路和视频通路的联合预训练设计是必要的。
![]()
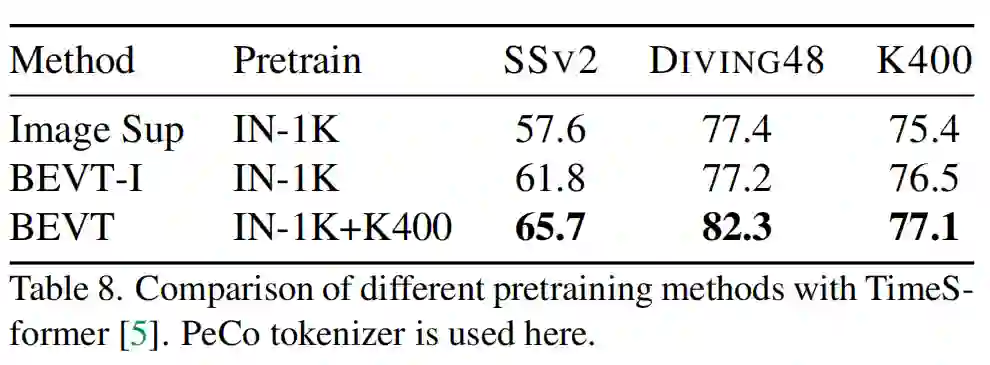
在 BEVT 预训练实验中,研究者使用了 2 种编码离散视觉 token 的 tokenizer,分别来自于 DALL-E 和 PeCo,其中 PeCo 是在 ImageNet-1K 上预训练的 tokenizer,在掩码图像建模任务上比 DALL-E tokenizer 更强。可以发现,使用更强的 tokenizer 能够帮助 BEVT 在下游视频任务上取得更好的性能。
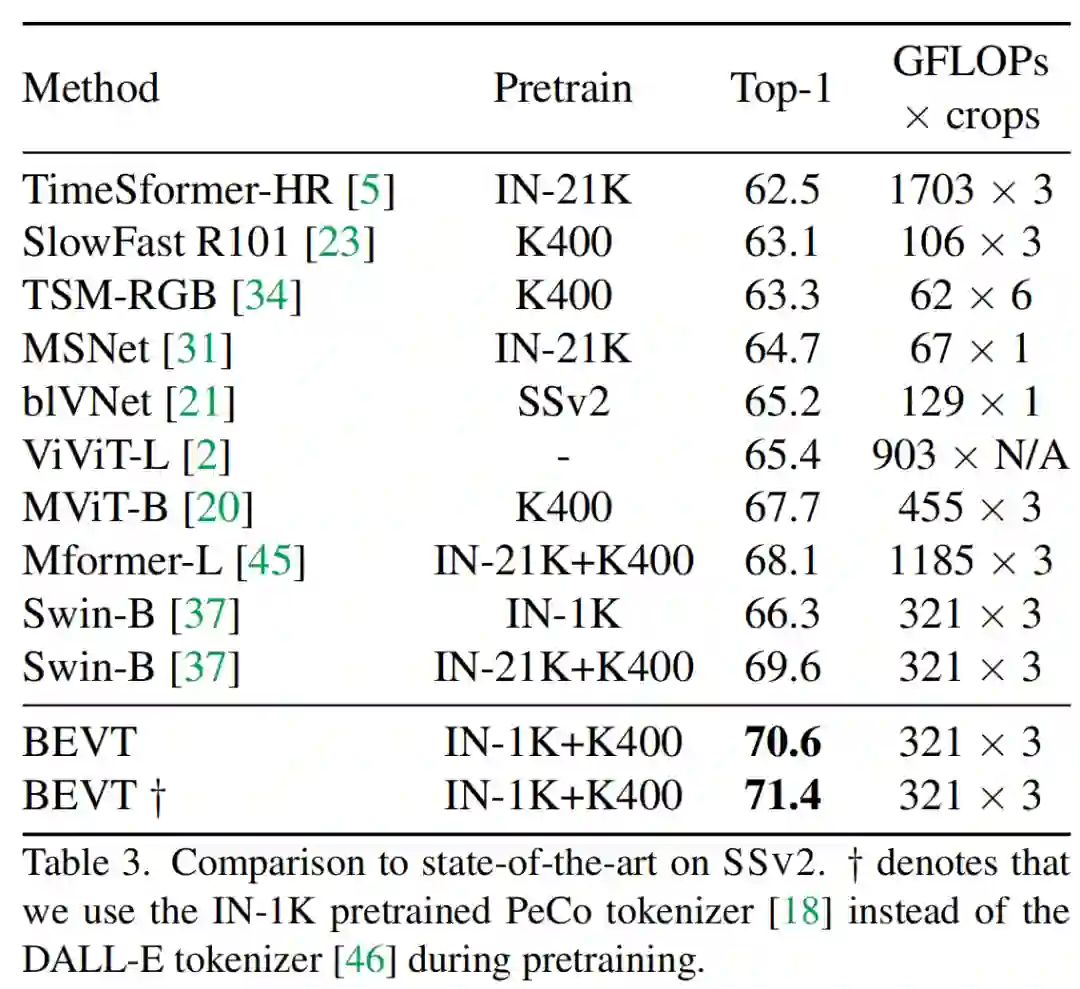
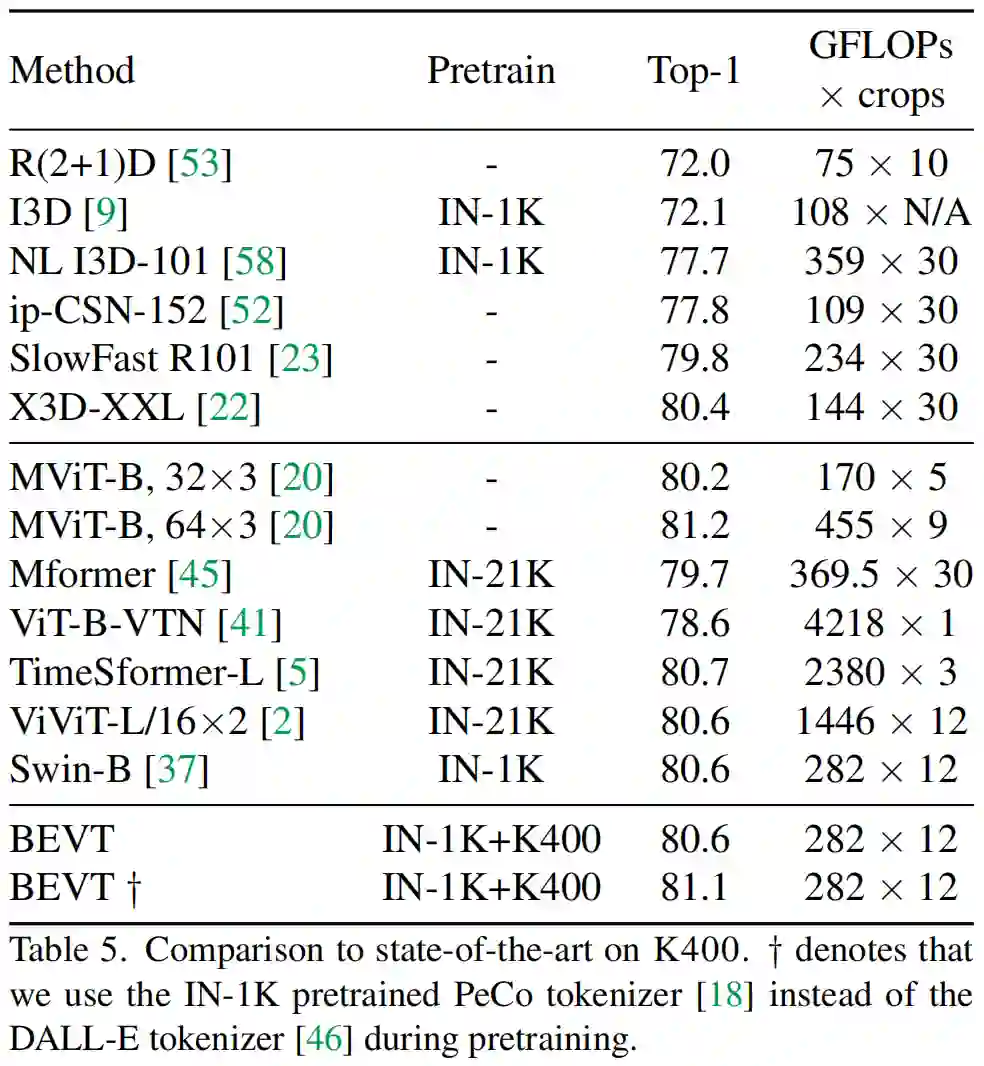
在与 SOTA 模型的比较中,可以看到,在 Something-Something v2 和 Diving48 上,BEVT 取得了明显比现有 SOTA 视频模型更好的性能;而在 Kinetics-400 上,BEVT 也取得了比计算量相近的 SOTA 模型更好或相当的性能。
![]()
![]()
![]()
BEVT 在预训练时首先通过图像数据集上的图像通路 BERT 预训练来高效地学习空间表示,然后将其作为双路联合 BERT 预训练的初始化。
研究者通过实验说明了这种策略的重要性:(1)将图像通路预训练得到的模型权重作为初始化,可以使得视频通路预训练和双路联合预训练的效果均得到提升。(2)即使使用了图像通路预训练作为初始化,将图像通路和视频通路进行联合训练仍是必要的,相比于纯视频通路预训练性能提升明显。
![]()
研究者认为 BEVT 中的双路联合预训练是一种通用的视频 Transformer 预训练方法,可以推广到其他视频 Transformer 模型架构。为了说明这点,研究者把 BEVT 框架扩展到了 TimeSformer 架构上。实验结果表明 BEVT 也能帮助 TimeSformer 在多种视频下游任务上取得显著优于 ImageNet 全监督预训练和图像通路预训练的性能。
![]()
作为首个视频 Transformer BERT 预训练方法,BEVT 不仅将图像 Transformer BERT 预训练中的掩码图像建模任务扩展为了掩码视频建模任务,还通过设计图像 - 视频双路联合预训练框架,避免了直接在大规模视频数据上从头训练这种相对低效的做法,并使得模型在不同类型的视频数据集上均能取得良好的迁移性能。
这种图像 - 视频联合自监督预训练方法为视频 Transformer 上的表征学习提供了一种新的高效训练方式,且可以推广到多种视频 Transformer 架构上。研究者希望后面的工作能在这种多源数据统一架构预训练框架的基础上,进一步考虑在有限资源下的高效预训练、多种自监督任务联合训练、多模态数据联合训练等具有挑战性的问题,实现图像 - 视频 / 多模态大一统模型研究的更大突破。
ICCV和CVPR 2021论文和代码下载
后台回复:CVPR2021,即可下载CVPR 2021论文和代码开源的论文合集
后台回复:ICCV2021,即可下载ICCV 2021论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
目标检测和Transformer交流群成立
扫描下方二维码,或者添加微信:CVer6666,即可添加CVer小助手微信,便可申请加入CVer-目标检测或者Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer等。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测或者Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
![]()
▲扫码或加微信: CVer6666,进交流群
CVer学术交流群(知识星球)来了!想要了解最新最快最好的CV/DL/ML论文速递、优质开源项目、学习教程和实战训练等资料,欢迎扫描下方二维码,加入CVer学术交流群,已汇集数千人!
![]()
▲扫码进群
整理不易,请点赞和在看![]()