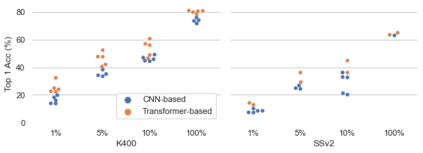
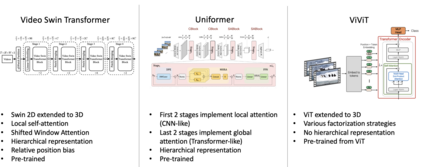
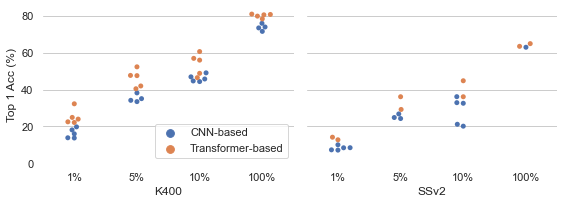
Recently vision transformers have been shown to be competitive with convolution-based methods (CNNs) broadly across multiple vision tasks. The less restrictive inductive bias of transformers endows greater representational capacity in comparison with CNNs. However, in the image classification setting this flexibility comes with a trade-off with respect to sample efficiency, where transformers require ImageNet-scale training. This notion has carried over to video where transformers have not yet been explored for video classification in the low-labeled or semi-supervised settings. Our work empirically explores the low data regime for video classification and discovers that, surprisingly, transformers perform extremely well in the low-labeled video setting compared to CNNs. We specifically evaluate video vision transformers across two contrasting video datasets (Kinetics-400 and SomethingSomething-V2) and perform thorough analysis and ablation studies to explain this observation using the predominant features of video transformer architectures. We even show that using just the labeled data, transformers significantly outperform complex semi-supervised CNN methods that leverage large-scale unlabeled data as well. Our experiments inform our recommendation that semi-supervised learning video work should consider the use of video transformers in the future.
翻译:最近,视觉变压器在多个视觉任务中与革命性方法(CNNs)相比被证明具有竞争力。变压器与CNN相比,较不具有限制性的感应偏向感应偏向比CNN具有更大的代表能力。然而,在图像分类设置中,这种灵活性的取舍是在抽样效率方面,变压器需要图像网络规模培训的权衡。这个概念已传到尚未在低标签或半监督的设置中探索变压器进行视频分类的视频。我们的工作经验性地探索了视频分类的低数据制度,并发现,与CNN相比,低标签变压器在低标签视频设置中表现极好。我们专门评估两个对比性视频数据集(Kinetics-400和Something-V2)之间的视频变压器变压器,并进行透彻的分析和对比研究,以利用视频变压器结构的主要特征解释这一观察。我们甚至显示,仅使用标签数据变压器就大大超越了CNN的半监督的复杂方法,从而利用了无标签的大规模数据作为变压器的变压器。我们未来的试验建议。