
情感自动识别是一个活跃的研究课题,具有广泛的应用前景。由于人工标注成本高和标签不可避免的模糊性,情感识别数据集的发展在规模和质量上都受到了限制。因此,如何在有限的数据资源下建立有效的模型是关键挑战之一。之前的研究已经探索了不同的方法来应对这一挑战,包括数据增强、迁移学习和半监督学习等。然而,这些现有方法的缺点包括:训练不稳定、迁移过程中的性能损失大、或改进幅度小。
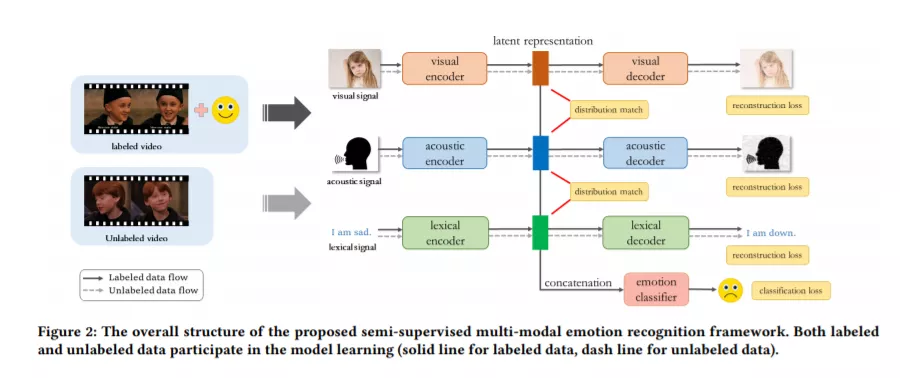
在本研究中,我们提出了一种基于跨模态分布匹配的半监督多模态情感识别模型,该模型在假设跨模态内部情绪状态在话语层面一致的前提下,利用大量的未标记数据来增强模型训练。
我们在两个基准数据集IEMOCAP和MELD上进行了广泛的实验来评估所提出的模型。实验结果表明,该半监督学习模型能够有效地利用未标记数据,并结合多种模态来提高情绪识别性能,在相同条件下优于其他先进的方法。与现有方法相比,该模型还利用了说话者和交互上下文等附加的辅助信息,从而达到了竞争能力。
成为VIP会员查看完整内容
相关内容

相关VIP内容
相关资讯
相关论文