镜头间的风格转换行人重识别
Camera Style Adaptation for Person Re-identification
CVPR 2018
论文链接:https://arxiv.org/abs/1711.10295
1. 摘要
作为一个交叉相机检索任务,个人身份验证遭受不同相机造成的图像风格变化。通过学习摄像机不变描述子空间来隐含地解决这个问题。在本文中,我们通过引入相机风格(CamStyle)适应明确地考虑了这一挑战。 CamStyle可以作为一种数据增强方法,平滑相机风格差异。具体来说,通过CycleGAN,标记的训练图像可以转移到每个摄像机,并与原始训练样本一起形成增强训练集,增加训练集中的样本数量。这种方法在增加数据多样性的同时也会产生相当大的噪音。为了减轻噪声的影响,采用标签平滑正则化(LSR)。我们的方法的vanilla版本(没有LSR)在经常发生溢出的少数相机系统上表现相当好。对于LSR,我们在所有系统中都表现出持续的改进,无论改写的程度如何。我们还报告与现有技术相比的竞争精度。
2. 论文核心
motivation: 如果可以在训练集中增加更多样本来了解摄像机之间的风格差异,就能够解决个人身份识别中的数据稀缺问题,并学习不同摄像机之间的不变特征。
解决方法:使用cycleGAN完成镜头间图片转换,损失函数使用cycleGAN loss 和 identify mapping loss。
motivation : 增加数据多样性以防止过度拟合,但是也会产生相当程度的噪音。
解决方法:为了缓解这个问题,在改进后的版本中,进一步在样式转移样本上应用标签平滑正则化(LSR),以便他们的标签在训练期间柔和地分布。
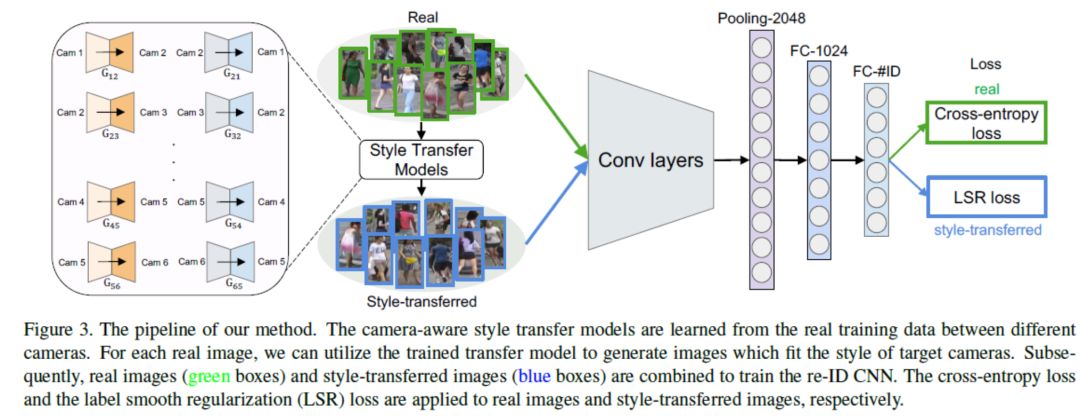
3. 论文网络框架
4.数据扩充示例图

5.本文提出的方法
5.1CycleGAN回顾
给定两个数据集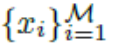
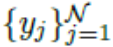
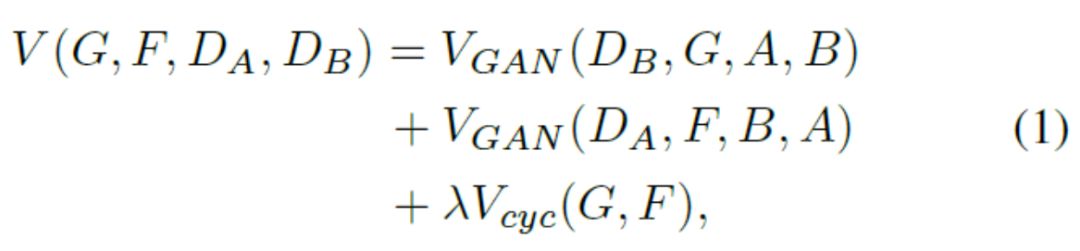
其中,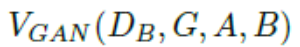
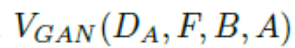
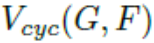
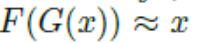
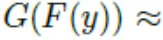
5.2 Camera-awareImage-ImageTranslation
在这项工作中,我们使用CycleGAN生成新的训练样本:不同相机之间的样式被认为是不同的域。 Givenare-ID数据集包含从L个不同相机视图收集的图像,我们的方法是使用CycleGAN为每个相机对学习图像 - 图像平移模型。 为了鼓励样式转换来保持输入和输出之间的颜色一致性,我们在CycleGAN损失函数(方程1)中添加了标识映射损失,以强制生成器在使用目标域的重复图像作为输入近似生成身份。 身份映射损失可以表示为:
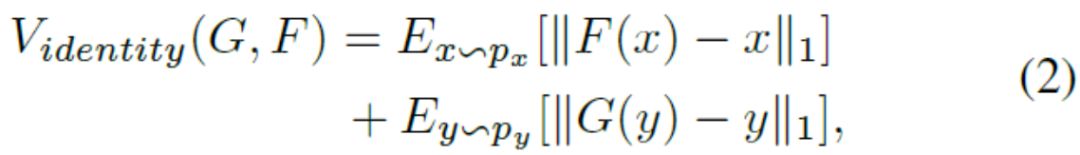
具体而言,对于训练图像,我们使用CycleGAN为每对摄像机训练相机感知式传输模型。在训练之后,所有图像被分割为256×256。我们使用与CycleGAN相同的体系结构来支持我们的相机感知式传输网络。生成器包含9个残余块和四个卷积,而鉴别器是70×70 PatchGANs 。
使用学习的CycleGAN模型,对于从某个相机收集的训练图像,我们生成L - 1个新样本,其样式与相应的相机相似(示例如图2所示)实验中,用所生成的图像样式转换图像或假图像。以这种方式,训练集被增强为原始图像和风格转移图像的组合。由于每个样式转移的图像保留其原始图像的内容,所以新样本被认为与原始图像具有相同的标识。这使我们能够利用样式传输的图像以及相关的标签样本 - IDCNNin以及原始训练样本。

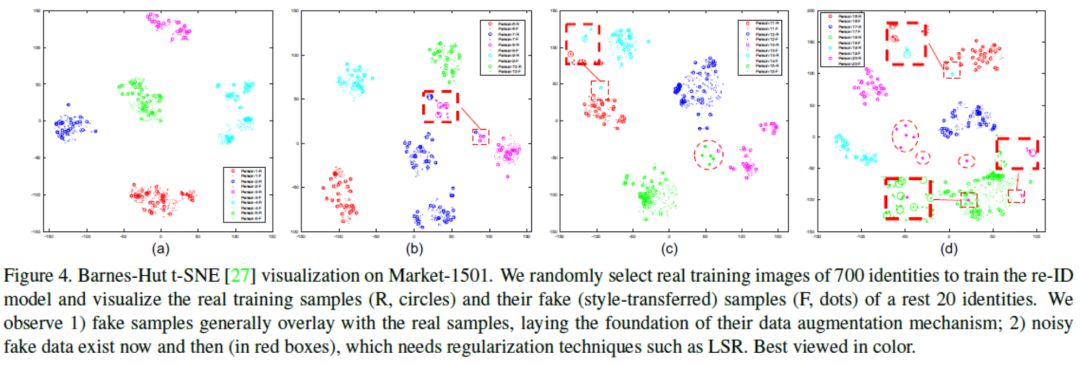
讨论: 如图4所示,所提出的数据增强方法的工作机制主要在于:
1)真实和伪造(风格转移)图像之间的相似数据分布,以及
2)保留伪造图像的ID标签。 在第一个方面,假图像弥补了真实数据点之间的差距,并在特征空间中稍微扩大了类边界。 这保证了增强数据集通常支持在嵌入学习期间更好地表征类分布。另一方面,第二个方面支持监督学习的使用,它利用未标记的GAN图像进行正则化。
5.3.BaselineDeepRe-IDModel
鉴于真实的和伪造的(风格转移的)图像都有ID标签,我们使用ID识别嵌入(IDE)来训练re-ID CNN模型。 使用Softmax损失,IDE将重新识别培训视为图像分类任务。 我们使用ResNet-50 作为主干,并对ImageNet预训练模型进行微调。我们丢弃最后的1000维分类层并添加两个全连接(FC)层。 第一个FC层的输出有1024个维度,命名为“FC-1024”,然后是批量归一化,使用ReLU激活函数和Dropout。第二个FClayer的输出是C维的,其中C是训练集中类的数量。 在我们的实验中,所有输入图像都调整为256×128。该网络如图3所示。
(dropout是指在深度学习网络的训练过程中,对于神经网络单元,按照一定的概率将其暂时从网络中丢弃。注意是暂时,对于随机梯度下降来说,由于是随机丢弃,故而每一个mini-batch都在训练不同的网络。dropout是CNN中防止过拟合提高效果的一个大杀器。)
5.4.TrainingwithCamStyle
假设由真实和伪造(风格转移)图像(带有它们的ID标签)组成的新训练集,本节讨论使用CamStyle的训练策略。 当我们平等地看待真实和虚假的图像时,即给他们分配一个“单热”标签分布时,我们获得了我们方法的一个vanilla version。 另一方面,当考虑伪造样本引入的噪声时,我们引入包含标签平滑正则化(LSR)的full version。
vanilla version:在vanilla版本中,新训练集中的每个样本属于单个身份。 在训练期间,我们随机选择M个真实图像和N个假图像。 损失函数可以写成,
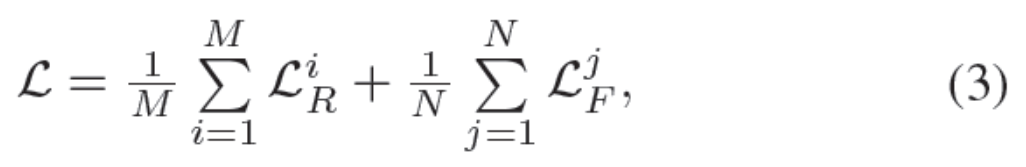
其中LR和LF分别是真实图像和假图像的交叉熵损失。交叉熵损失函数可以表示为,
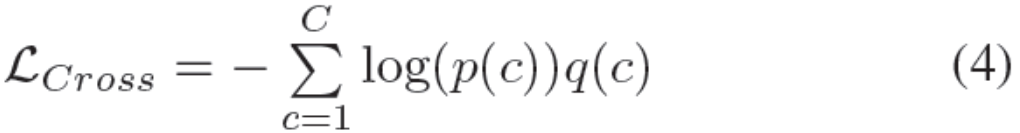
其中C是类的数量,而p(c)是标准中输入的预测概率。 p(c)由softmax层归一化,所以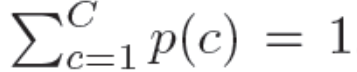
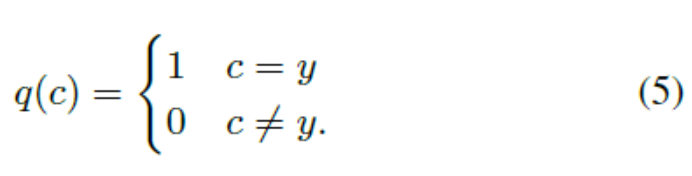
因此,最小化交叉熵相当于最大化地面实况标签的概率。 对于一个给定的身份为y的人,方程 4可以改写为
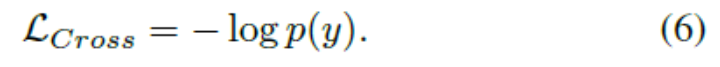
full version:样式转换后的图像具有正面的数据增强效果,但也会给系统带来噪音。因此,尽管在少数摄像机系统下,由于缺乏数据,结果过拟合,但在更多摄像机下,它的有效性受到影响,而香草型摄影机在降低数码相机系统性能方面表现出色。原因是,当有更多摄像机的数据可用时,过度拟合问题不那么重要,并且传输噪声的问题开始出现。
传递噪音源于两个原因。 1)CycleGAN不能完美地模拟传输过程,因此在图像生成期间发生错误。 2)由于遮挡和检测错误,实际数据中存在噪声样本,将这些噪声样本转换为假数据可能产生更多噪声样本。
在图4中,我们将二维空间中真实和虚假数据的深层特征的一些例子可视化。大部分生成的样本都分布在原始图像周围。当传输错误发生时(见图4(c)和图4(d)),假样本将是一个噪声样本,并且与真实分布相距很远。当真实图像是噪声样本图像(参见图4(b)和图4(d))时,它与标签相同的图像相距很远,因此其生成的样本也会很嘈杂。这个问题减少了全摄像系统下生成的样本的好处,其中相对丰富的数据具有较低的覆盖风险。为了缓解这个问题,我们将标签平滑正则化(LSR)应用于样式传输的图像,以轻柔地分发他们的标签。也就是说,我们对ground-truth标签的信任度较低,并为其他类别分配较小的权重。每个风格转移图像的标签分布的重新分配被写为,
E∈[0,1]当 E= 0,等式7可以简化为公式5。然后,然后,将式(4)中的交叉熵损失重新定义为
对于真实图像,我们不使用LSR,因为它们的标签与图像内容正确匹配。此外,我们通过实验证明,在真实图像中添加LSR并不能提高全摄像系统下的重新识别性能。所以对于真实的图像,我们使用单热标签分发。对于风格转移的图像,我们设置
LSR--就是为了缓解由label不够soft而容易导致过拟合的问题,使模型对预测less confident。
4. Experiment
我们使用了Market-1501和DukeMTMC-reID两个数据集进行验证。因为他们数据量足够大,而且每一张图像都提供了相机标签。
Market-1501:该数据集在清华大学校园中采集,图像来自6个不同的摄像头,其中有一个摄像头为低像素。同时该数据集提供训练集和测试集。 训练集包含12,936张图像,测试集包含19,732 张图像。图像由检测器自动检测并切割,包含一些检测误差(接近实际使用情况)。训练数据中一共有751人,测试集中有750人。所以在训练集中,平均每类(每个人)有17.2张训练数据。
DukeMTMC-reID:该数据集在杜克大学内采集,图像来自8个不同摄像头。该数据集提供训练集和测试集。 训练集包含16,522张图像,测试集包含 17,661 张图像。训练数据中一共有702人,平均每类(每个人)有23.5 张训练数据。是目前最大的行人重识别数据集,并且提供了行人属性(性别/长短袖/是否背包等)的标注。
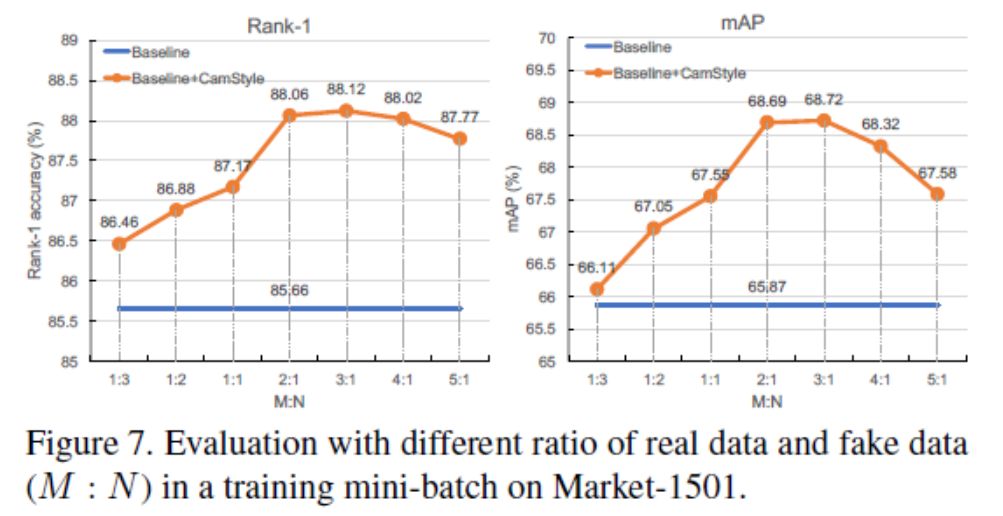
实验参数分析:一个重要的参数涉及到CamStyle的真假样本的比例M/N, 这个比例设置多少为好??通过改变这一比例,我们在图7中显示了实验结果。通过实验可以看出,我们无论比例设置为多少,加入CamStyle的结果都要高于Baseline。当在每个mini-batch中使用比真实数据更多的假数据时(M:N<1),我们的方法在rank-1精度上稍微提高了1%。当(M:N>1)我们的方法在rank-1精度方面提高了2%以上。通过实验我们设置最好的结果就是M:N=3:1
mAP的全称是mean average precision,用于衡量算法的搜索能力
Rank-1搜索结果中最靠前的一张图是正确结果的概率,一般通过实验多次来取平均值。
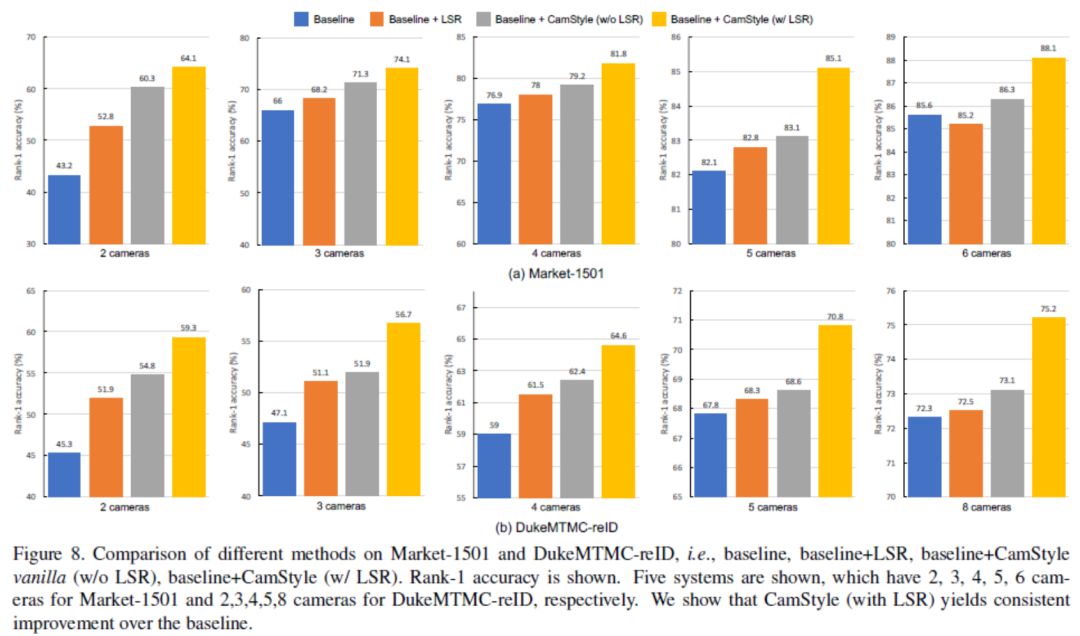
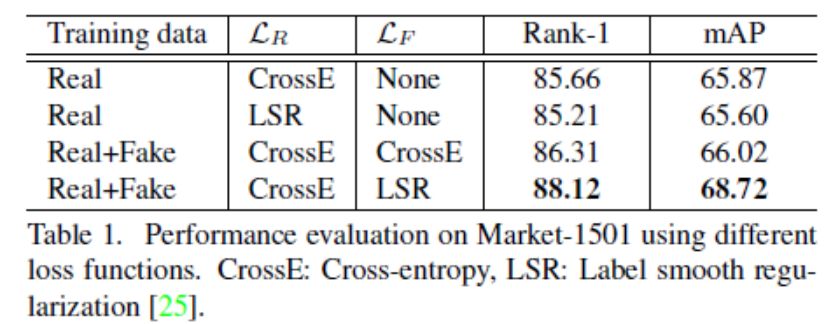
特别地,图8和表1显示,仅在真实数据上使用LSR,对全相机系统的性能没有多大帮助,甚至降低了性能。因此,与LSR相比,CamStyle与LSR的改进并不仅仅归功于LSR,而是LSR和假图像之间的交互。通过这个实验,我们证明了在假图像上使用LSR的必要性。
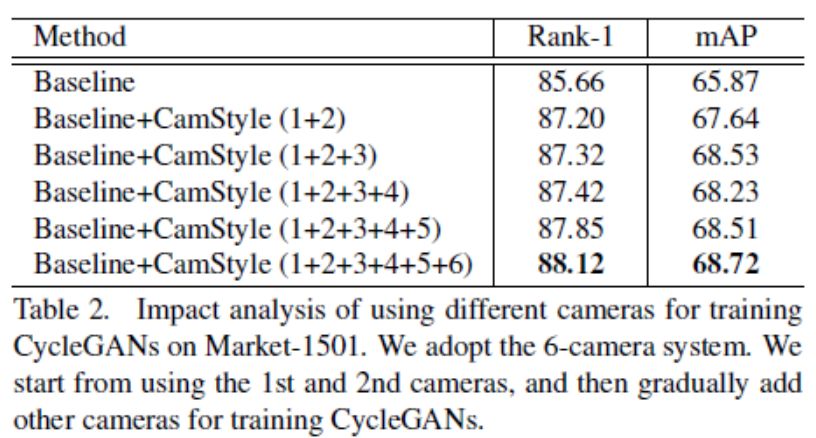
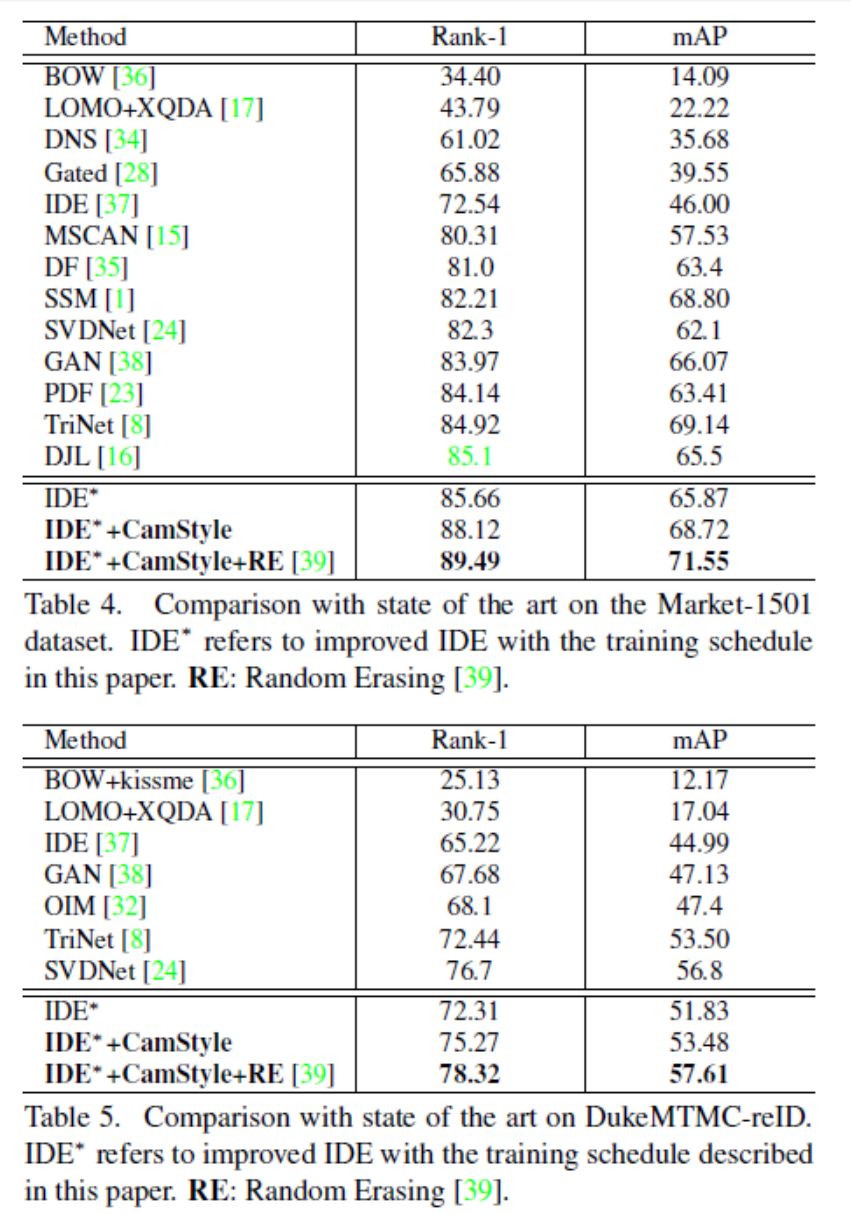
在表2中,我们展示了使用更多的摄像头来训练相机感知的样式传输模型,rank-1的精度得到了提高。from 85.66% to 88.12%.特别地,我们的方法在rank-1精度上得到了+1.54%的改进,即使只使用第1和第2个摄像头来训练相机感知的样式传输模型。此外,当使用5个摄像头训练相机风格的传输模型时,它的rank-1精度为87.85%,比使用6个相机的准确率低0.27%。这表明,即使使用摄像机的一部分来学习相机感知的样式传输模型,我们的方法也可以产生大约相同的结果来使用所有的摄像头。
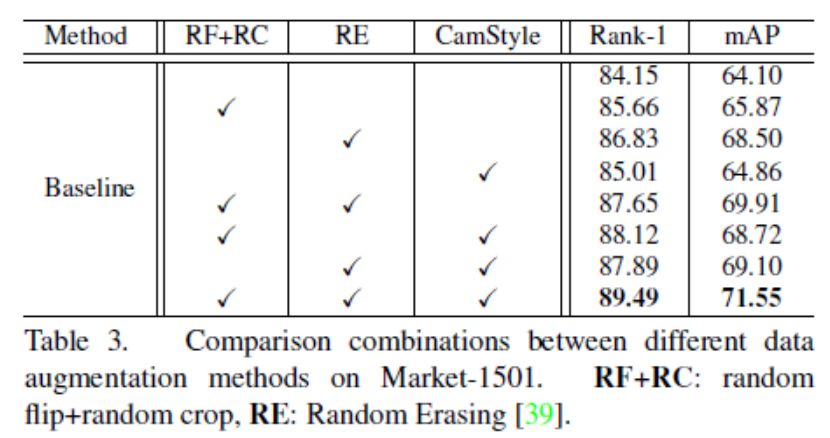
为了进一步验证CamStyle,我们将它与两个数据增强方法进行比较, random flip + random crop(rf+rc)和Random Erasing(RE)。rf+rc是CNN训练中常用的一种技术,以提高图像翻转和物体翻译的鲁棒性。RE的设计是为了使不变性成为不变性。如表3所示,当不使用数据增强时,rank-1的精度是84.15%。当只应用rf+rc、RE或CamStyle时,rank-1的精度分别提高到85.66%、86.83%和85.01%。此外,如果我们将CamStyle与rf+rc或RE组合在一起,我们会观察到它们各自的使用情况的持续改进。最好的性能是在三个数据增强方法一起使用的时候实现的。因此,虽然这三种不同的数据增强技术关注的是CNN不变性的不同方面,但我们的研究结果表明,CamStyle与其他两个方面是互补的。特别地,结合这三种方法,我们达到了89.49%的rank-1精度。
总结:文章是一种数据增广的方法并且把它应用到ReID,增加camera的数量而提高模型的性能,本质上是数据增广,数据量增大了,模型的性能必然会有一些提升。

