2017年领域自适应发展回顾

本文为 AI 研习社编译的技术博客,原标题 :
A Little Review of Domain Adaptation in 2017
翻译 | 小猪咪 校对 | Lamaric 整理 | 志豪
原文链接:
https://artix41.github.io/static/domain-adaptation-in-2017/index.html
注:本文的相关链接请点击文末【阅读原文】进行访问

2017年领域自适应的一点回顾
这篇文章原为 quora 中2017年机器学习领域最杰出的成就是什么?问题下的答案。
2017是领域自适应形式大好的一年:产生了一些优秀的图对图、文对文转换的成果,对抗方法的应用水平显著提高,一些卓越的创新算法被提出以解决两领域间适应时的巨大问题。
通过领域适应,我是指任何想要对两个领域(通常叫做源和目标,如绘画作品和真实图片)间进行转换的算法,都想把它们映射到一个公共的领域。为了达到这一效果,你可以选择把一个领域转换成另一个(如把绘画转换成照片),也可以找到两个领域间一个公共的映射。当只有源域有标签而我们想要给目标域预测标签时,这就被称为无监督的领域适应,也是这些成果最杰出的地方。有很多评估 DA 算法的基准,一个最常用的就是通过 MNIST 集(一个最常见的手写数据集)和它的标签来预测 SVHN(一个门牌号码数据集)的标签。在一年的时间里,准确度从90%(这是 DTN 的结果,相比于之前算法如 DRCN 等的82%已经有了很大提高),进一步提升到了99.2%(self-ensembling DA 的结果)。除了准确度上的量化分析,今年的一些算法结果在质量上也十分惊人,尤其是在视觉领域自适应和自然语言处理方面。

图1 利用2017年5月发表的 SBADA-GAN[4] 完成从 SVHN 到 MNIST 的转化。为了测试 DA 算法,你可以只利用 MNIST 的标签,采用二者间无监督转化的方法预测 SVHN 的标签。
让我们来总结一下这一年领域自适应方向的卓越成果吧。
对抗领域自适应
如果说2015年是对抗域适应出现的一年( 由 DANN[5]为代表),而2016年是基于 GAN 的域适应出现的一年(由 CoGAN[6] 和 DTN[2:1]),那么2017年就是这些方法大幅长进并产生惊人成果的一年。
对抗域适应背后的思想是训练两个神经网络:一个辨别网络试图分辨变换后的源域与目标域,而生成网络则试图使源域变得尽可能逼近目标域以迷惑辨别网络。它的思想主体还是 GAN ,只不过输入的是源域的分布而不是均匀分布(通常被称为条件 GAN )。我做了一个小动画来更直观地解释这个概念(代码在这里):
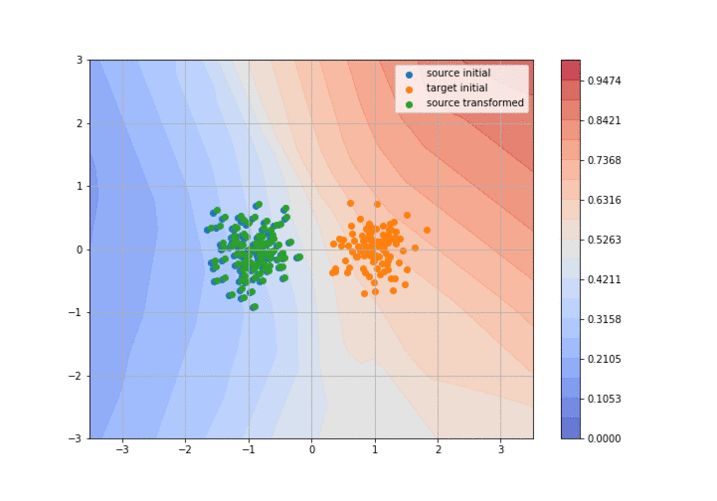
图2 基于 GAN 的两个高斯分布域的对抗域适应。判别器(背景)尝试将绿色和橘色的分布分离开,生成器则修正绿色的分布来迷惑判别器。代码在这儿。
所以,2017年的“重大进展”是什么呢?
ADDA
首先在2月份,ADDA[7]发布了一个泛化对抗域适应理论模型框架并在一个简单的 SVHN → MNIST 的 GAN 损失上达到了76.0%的分数(他们认为这是对抗网络在这个任务上最好的分数,但他们可能在提交论文时还没有听说过 DTN 这个模型)。
CycleGAN 模型
一个月之后,对抗域适应领域的一个最重要的成果出现了: CycleGAN[8] 提出的的循环一致损失。这篇文章真的称得上是一场革命式创新。他们的思想是训练两个条件 GAN ,一个完成从源到目标的转化,一个正相反,之后他们考虑了一种称作循环一致损失的新的损失函数,它保证了如果你将两个网络连接到一起,将会得到一个恒等映射(源 → 目标 → 源)。他们的从马到斑马以及从画到照片的转换结果十分出名,我觉得这真是这一年最酷炫的东西之一了!和其它如 pix2pix[9], 等方法不同的是,他们没有用成对的图片训练网络(比如 pix2pix 用到的猫的照片和同样一只猫的素描),而仅仅用到了两个独立的分布,这也使得他们的工作更加引人注目。
图3 CycleGAN 的图-图转换示例
DiscoGAN 模型
有意思的是很多其它文章在三到五月几乎同时发现了循环一致损失,有些时候还叫不同的名字(如重建损失)。以 DiscoGAN[10] 为例,它提出的损失就略有不同(比如对 GAN loss 使用了交叉熵代替了均方误差),但他们也达到了很棒的效果,实现了同时对质地属性(比如将金发变成棕色头发的人,将女人变成男人,或将戴眼镜的人变成不戴眼镜的人)和几何属性(椅子变成汽车,脸变成汽车)进行转换。


图4 DiscoGAN 的图-图转换示例
DualGAN 模型
DualGAN[11] 也是一样,它用到了 WGAN 以及其它一些近期出现的用于更好地训练GAN 模型的技巧 。它将模型用于做白天←→黑夜或素描←→照片的转换,下面是他们的结果:

图5 DualGAN 的图-图转换示例
SBADA-GAN 结构
但上面提到的三篇文章都没有考虑到任何带有任务的数据集(如分类任务),所以不能给出他们方法的量化评价。 SBADA-GAN[4:1] 做到了这一点,他们在网络的最后加入了一个分类器来预测源域和转换之后的目标域图片的标签。在训练过程中,将伪标签分配给给目标样本以生成分类损失。在 SVHN → MNIST 上得到的分数不是很高(~76%,和 ADDA 相仿),但他们在反变换上(MNIST→SVHN) 以及在 MNIST ←→ USPS 上(另一个和 MNIST很像的手写数字数据集)都达到了新的 SOTA 成果。
GenToAdapt 模型
还有一种对抗结构今年在数字基准模型上可谓是大获成功,四月份发表的 GenToAdapt[12] 在 SVHN → MNIST 上达到了92.4%的高分,可以说是这一年第一个可以称得上 state-of-the-art 的工作。他们的技术简单说来是使用了 GAN 模型从源域和目标域提取样本生成源域图像,并用判别器鉴别真伪以及确认源域样本不同的分类标签(就像 AC-GAN )。这种机器学习得来的 embedding 方法训练好之后将被用来训练第三个网络,C,来直接预测输入样本的标签。下面的这张图(来自原论文)肯定比我的解释清楚多啦。
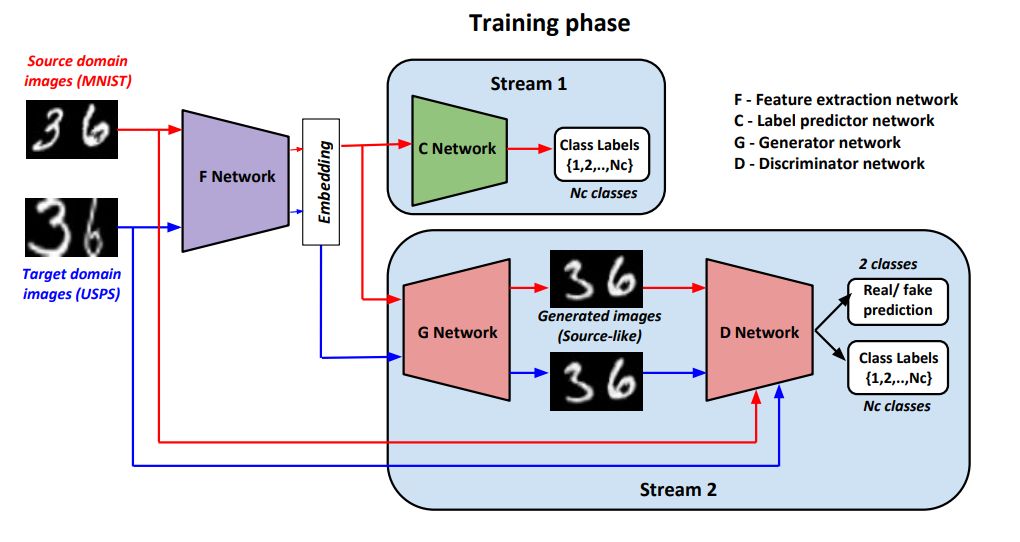
图6 GenToAdapt 的结构
UNIT 模型
一种Nvidia提出的对抗结构, UNIT[13] ,也表现不凡。就像 Nvidia 的其他文章一样,他们展示出了很多惊艳的实验结构(比如基于不同外部条件的图-图转换, GTA 和现实的切换,不同品种的狗变换等)。他们也在 SVHN → MNIST 上测试了他们的算法并达到了90.53%的分数,和 DTN 的得分十分接近,但他们的图像分辨率要高得多。他们的技术基于一种含有两个 GAN 模型的 CoGAN[6:1] ,一个生成源域图像,一个生成目标域图像,一些层之间权值共享。Nvidia 的主要贡献是把生成器用VAE 实现了,他们的确成功展示出了 VAE 损失和前述文章中的循环一致损失的等价性。

图7 UNIT 的图-图变换部分结果
StarGAN
然而这些结构只适用于在一次变换中从一个源域变换到一个目标域。如果你有多个域,就应该有一种网络训练的方法在所有的域间做变换。9月份 StarGAN[14] 把 CycleGAN应用到了所谓的多域适应问题中。他们对于同一个体的发色和情绪变换的结果的确很惊人,正如你们所看到的这样:

图8 StarGAN 的多域图像变换示例
没有并行数据的文字翻译
从上述例子中可以看到域适应领域的研究基本聚焦在计算机视觉领域(CV),但去年最重要的且共享的文章之一出自自然语言处理领域(NLP):Word Translation Without Parallel Data[15]。他们主要采用了对抗域适应的方法,找到了一个两种语言(源和目标)样本间的 embedding,而且在不依赖任何翻译样例的情况下达到了很高的准确率!如果你读过这篇文章,你会注意到“域适应”的字样一次也没有出现……因为大多数 DA 的研究猿都在计算机视觉领域,看起来那些 NLP 领域写出这篇文章的家伙自己都没有意识到他们的工作实际上进入了域适应的范畴。所以我觉得,如果 NLP 的研究员们尝试着在今年 CV 社群中涌现出的大量而优秀的 DA 新方法上测试他们的数据的话,可能会收获满满呢。
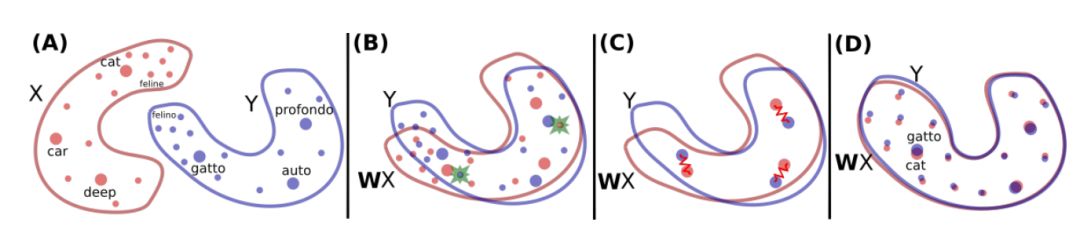
图9 源域(英语)和目标域(意大利语)的嵌入词空间的校准
Pix2Pix HD
最后,我刚刚只提到了未配对的域适应(就是说你在训练的时候不使用任何配对的源/目标样例),但配对的 DA 也由 pix2pixHD[16] 带来了一场小革新。它可以说是 pix2pix (一个基于配对样本训练的条件对抗生成网络)的升级版本,用了许多小技巧来使它可以适用于更大的图像。他们把网络训练得可以将区域分割后的图片转换为真实的街景照片,正如你在下面的动画演示中看到的那样:

图10 利用pix2pix HD生成的从区域分割图向真实街景的转化效果
嵌入方法
除了对抗域适应,今年也有人尝试了许多其它方法,它们中的一些还是很成功的。近期有两个方法试图找到源和目标域间的通用嵌入法,最后达到了利用一个神经网络就能对两个域的样本进行分类的效果。
Associative DA
第一个是 Associative DA (\( DA_{assoc} \))[17] ,它在 SVHN→MNIST 任务中达到了97.6%的分数。为了找到最佳 embedding 方式,他们使用了2017年的新趋势…循环一致损失!是的,这个方法再一次的出现了,只不过这次没有任何 GAN 和对抗网络的痕迹:它们只是尝试学习出一种 embedding 方法(前年这是用神经网络实现的),以使得当来自两个域的样本属于同一类别时,从源域样本向目标域转换(基于 embedding 空间里两点间的距离),再转换回另一个源域样本的可能性会更高。
Self-Ensembling DA
第二个是Self-Ensembling DA[3:1] ,它的99.2%的极高的准确率可真是把我们的 SVHN→MNIST 测试基准模型按在地上摩擦!看来明年我们要寻找新的测试基准了!这样的效果是通过引入 Mean Teacher 达到的,这是一个来自半监督学习领域并达到了最近 SOTA 成果的工作。它的思想是,有两个网络分别叫做 student 和 teacher,而 teacher 的权重是整个训练过程中 student 网络权重的动态平均值。之后,有标签的源域样本被用作训练 student 网络以使之成为一个更好的分类器,而无标签的目标域样本被用作训练 student 网络来使之接近 teacher 网络(利用一致性损失)。你可以在这里看到一个更直观的可视化解释。
最优传输
还有一种方法也是今年的产物:基于最优传输的领域自适应。最优传输是应用数学中一个巨大的领域,其中就包含如何找到从一个分布到另一个的最优传输方案:通过最小化从源集到目标集的传输的消耗总和。比如说,如果你考虑两个点集(含有相同数目的点),分别是源集和目标集,简单的将欧拉距离作为消耗函数,那么最优传输就要求你把每个源点和目标点相关联从而使总距离最小化。下面是对于两个高斯分布域的解:
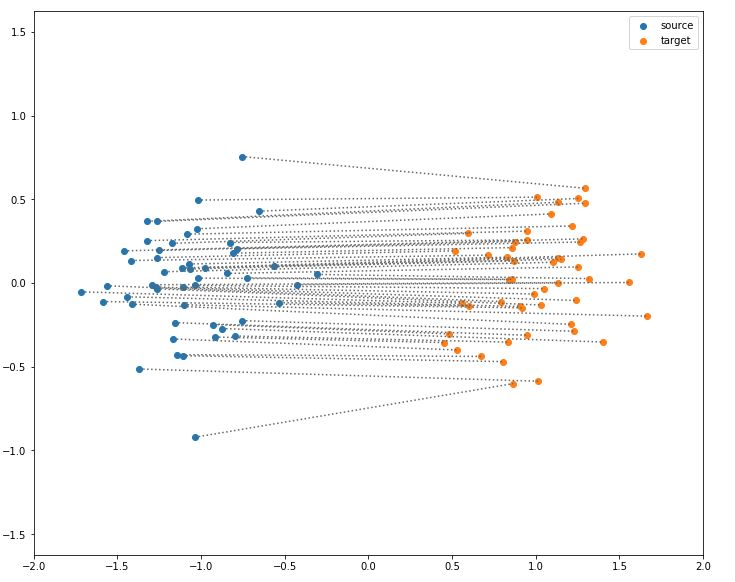
图11 两个高斯分布域间的最优传输方案,每个源点被传输到一个目标点,总距离被最小化了。这个图是通过 POT 库生成的。
如果你想了解更多有关 OT 的内容,这篇博文是一个绝佳的综述。
如果你已经开始对域适应有所涉猎,我觉得现在你可以清楚地看到 OT 和DA 间的联系。这两个领域间的关系在 2016[18]年被理论化出来,但一个非常有趣的算法在2017年才出现:联合分布最优传输(JDOT)[19]。他们的方案是一个迭代的过程:在一次迭代过程中,伪标签被赋给每一个目标点(最开始是使用一个在源样本上训练出来的分类器)。之后的目标是从每一个源点传输到目标点,但最小化的不止是总距离,还有传输过程中变化了的标签的总数(源点标签和目标点的伪标签)。我在这里做了一个可视化的说明:一个 JDOT 算法的可视化说明,在下面的 GIF 里可以了解一个大概(我不能确定如果不在每一步停顿的话是否还方便大家理解):
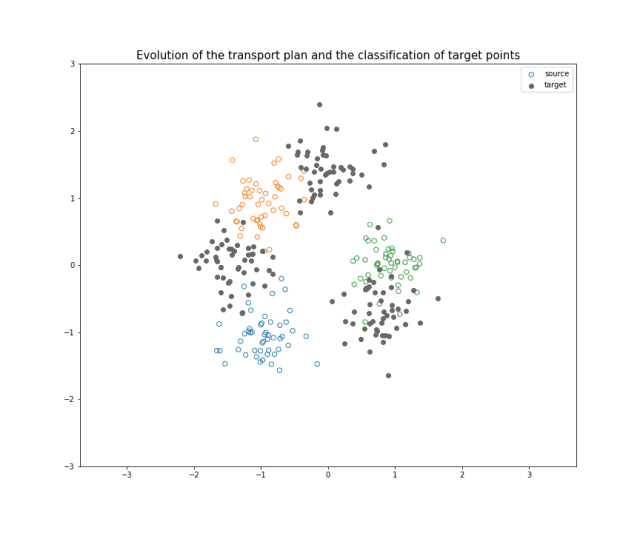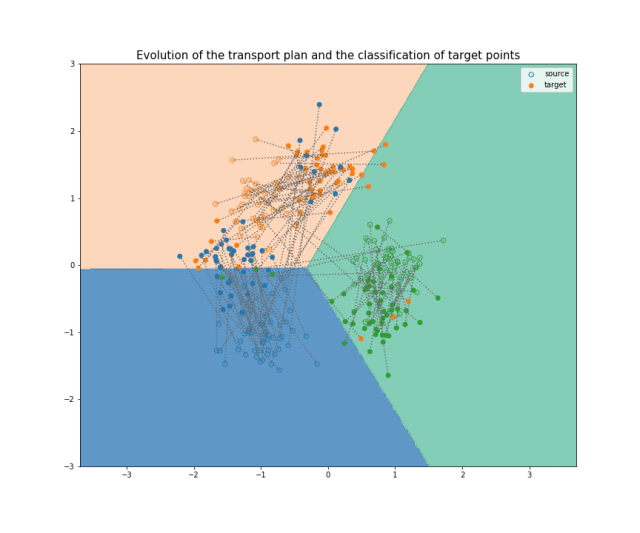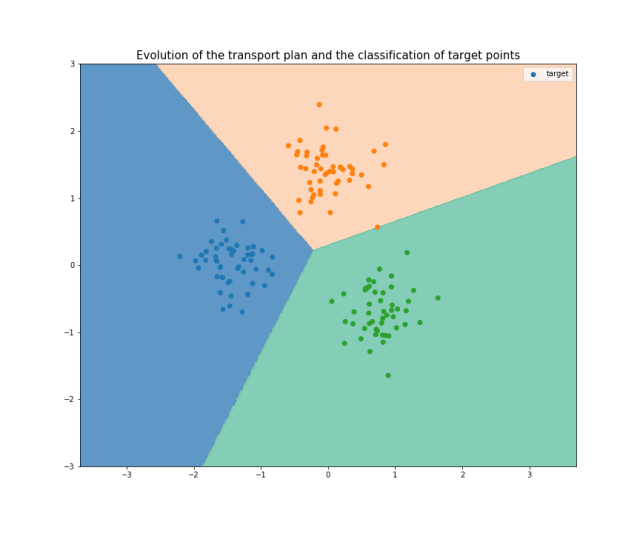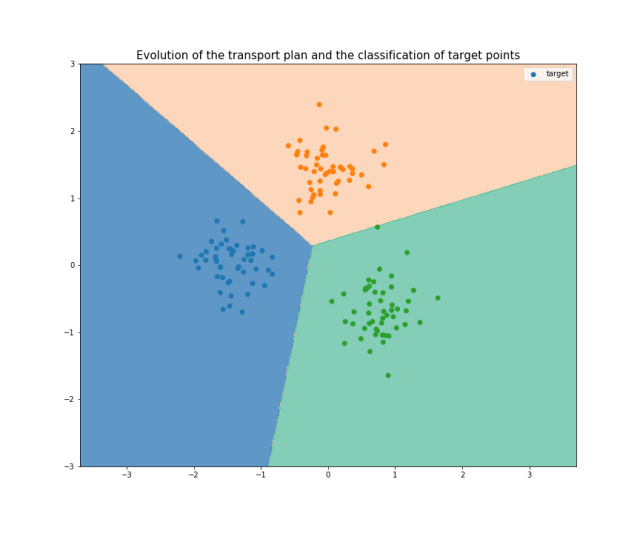
图12 展示 JDOT 算法中不同步骤的动画。你可以在这里找到单独的每一张图片和附加说明。
总结
总结来说呢,2017年不仅用绝佳的分数碾压了一些域适应的标准评测方法,而且还创造出了第一个从一个域到另一个的高质量图片转化(就像你在上面看到的这些图片)。但我们还可以在许多更加复杂的评测机制上做到更好,并且把 DA 方法运用到机器学习的其他领域中去(比如强化学习和 NLP)。所以2018很有机会变得和2017年同样优秀,我很期待这一年能看到哪些新的成果!
如果你想学习更多和领域自适应相关的内容,我在维护一个关于 DA 和迁移学习的资源列表(包含文章,数据集和成果等),在这里可以找到它们。
免责声明:这些文章的描述仅限于我个人目前对它们的理解,所以抱着怀疑的态度来审视它们吧,如果你发现我有表述上的错误或不精确之处请毫不犹豫地告诉我。再来看我给出的这些结果,它们只是原文中说明的,因此事实上,为了给出一个更加真实可靠的比对结果可能还需要运用一些更加严谨的方法。
参考文献
Unsupervised Cross-domain Image Generation(无监督跨域图像生成)(2016) ↩︎
Deep Reconstruction-Classification Networks for Unsupervised Domain Adaptation(无监督域自适应的深度重建分类网络 ) (2016) ↩︎
Self-ensembling for domain adaptation (领域自适应的自嵌入)(2017) ↩︎
From source to target and back: symmetric bi-directional adaptive GAN (源与目标的来回转换:对称双向自适应 GAN)(2017) ↩︎
Domain-Adversarial Training of Neural Networks (神经网络的领域对抗训练)(2015) ↩︎
Coupled Generative Adversarial Networks (耦合生成对抗网络)(2016) ↩︎
Adaptative Discriminative Domain Adaptation (基于适应性判别的域适应)(2017) ↩︎
Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks(基于循环一致损失对抗网络的无配对图对图转换) (2017) ↩︎
Image-to-Image Translation with Conditional Adversarial Networks(基于条件生成对抗网络的图对图转换)(2016) ↩︎
Learning to Discover Cross-Domain Relations with Generative Adversarial Networks(基于生成对抗网络的交叉域关联学习) (2017) ↩︎
DualGAN: Unsupervised Dual Learning for Image-to-Image Translation (DualGAN:图对图转换的无监督对耦学习)(2017) ↩︎
Generate To Adapt: Aligning Domains using Generative Adversarial Networks (生成适应网络:基于生成对抗网络的领域校准)(2017) ↩︎
Unsupervised Image-to-Image Translation Networks(无监督图对图转换网络) (2017) ↩︎
StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation(StarGAN:联合生成对抗网络用于多领域图对图转换) (2017) ↩︎
Word Translation without Parallel Data (脱离平行数据的文字翻译)(2017) ↩︎
High-Resolution Image Synthesis and Semantic Manipulation with Conditional GANs (高分辨率图像合成和语义操作)↩︎
Associative Domain Adaptation (关联域适应)(2017) ↩︎
Theoretical Analysis of Domain Adaptation with Optimal Transport(在域适应中使用最优传输的理论分析)(2016) ↩︎
Joint distribution optimal transportation for domain adaptation(联合分布最优运输和域适应)2017) ↩︎
想要继续查看该篇文章相关链接和参考文献?
戳链接或点击底部【阅读原文】:
http://www.gair.link/page/TextTranslation/1093
AI研习社每日更新精彩内容,观看更多精彩内容:
悼念保罗·艾伦,除了他科技圈还有哪些大佬值得信仰?
AI课程/书籍/视频讲座/论文精选大列表
自定义损失函数Gradient Boosting
为什么现在人工智能掀起热潮?
等你来译:
深度网络揭秘之深度网络背后的数学
如何开发多步空气污染时间序列预测的自回归预测模型
(Python)可解释的机器学习模型
很有启发性的25个开源机器学习项目
号外号外~
想要获取更多AI领域相关学习资源,可以访问AI研习社资源板块下载,
所有资源目前一律限时免费,欢迎大家前往社区资源中心
(http://www.gair.link/page/resources)下载喔~
全球AI+智适应教育峰会
免费门票开放申请!
雷锋网联合乂学教育松鼠AI以及IEEE教育工程和自适应教育标准工作组,于11月15日在北京嘉里中心举办全球AI+智适应教育峰会。美国三院院士、机器学习泰斗Michael Jordan、机器学习之父Tom Mitchell已确认出席,带你揭秘AI智适应教育的现在和未来。
扫码免费注册