跨模态关联
·

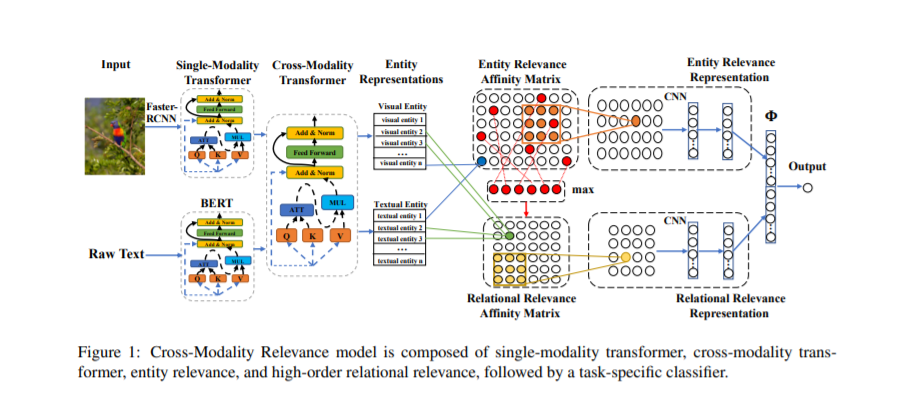
本文处理学习和推理语言和视觉数据的相关下游任务的挑战,如视觉问题回答(VQA)和自然语言的视觉推理(NLVR)。我们设计了一个新颖的跨模态关联模块,用端到端框架在目标任务的监督下学习各种输入模态组件之间的关联表示,这比仅仅重塑原始表示空间更易于推广到未观测的数据。除了对文本实体和视觉实体之间的相关性进行建模外,我们还对文本中的实体关系和图像中的对象关系之间的高阶相关性进行建模。我们提出的方法使用公共基准,在两个不同的语言和视觉任务上显示出具有竞争力的性能,并改进了最新发布的结果。NLVR任务学习的输入空间对齐及其相关表示提高了VQA任务的训练效率。
成为VIP会员查看完整内容
相关内容
Arxiv
4+阅读 · 2018年8月29日
Arxiv
9+阅读 · 2018年1月27日
Arxiv
21+阅读 · 2018年1月16日
相关主题
相关VIP内容
相关资讯
相关论文
Arxiv
4+阅读 · 2018年8月29日
Arxiv
9+阅读 · 2018年1月27日
Arxiv
21+阅读 · 2018年1月16日