CVPR 2018 论文解读 | 基于GAN和CNN的图像盲去噪

作者丨左育莘
学校丨西安电子科技大学
研究方向丨计算机视觉
图像去噪是low-level视觉问题中的一个经典的话题。其退化模型为 y=x+v,图像去噪的目标就是通过减去噪声 v,从含噪声的图像 y 中得到干净图像 x 。在很多情况下,因为各种因素的影响,噪声的信息是无法得到的,在这样的情况下进行去噪,就变成了盲去噪。
Image Blind Denoising With Generative Adversarial Network Based Noise Modeling 是中山大学和 CVTE 发表于 CVPR 2018 的工作,该文章通过利用 GAN 对噪声分布进行建模,并通过建立的模型生成噪声样本,与干净图像集合构成训练数据集,训练去噪网络来进行盲去噪。


很多去噪问题的解法,例如基于多种图像先验信息的方法,如 BM3D,可以通过结合 noise-level 估计算法来达到盲去噪的效果。但是,这些方法还是有很大的缺陷。
首先,在这些方法中的图像先验信息大多基于人类知识,因此图像的全部特征就很难被捕捉到。第二,这些方法中绝大多数都是只用了输入图像的内部信息,没有使用到任何的外部信息,所以,还有很大的提升空间。
而基于已知噪声信息(noise-level)的图像去噪方法,特别是基于 CNN 的方法,对于已知高斯噪声的信息,这些方法可以达到 SOTA 水平。而且,这些方法不需要依靠人类对于图像的先验信息。但是这些方法在实际中很难派上用场。因为实际中我们得到一张图像,其中的噪声信息是未知的。
基于上面的分析,作者的思路:通过给定的含噪声图像构建一个配对的训练数据集,然后通过使用基于 CNN 的方法来进行盲去噪。
构建这样一个数据集需要通过含噪声的图像来对噪声分布进行建模,然后生成噪声数据。实际上,前面的工作已经使用 GMM(高斯混合模型)来进行对噪声的模拟。但是得到的噪声数据并不是和观测得到的噪声十分相似,因此就需要一个更好的噪声建模方法。
作者在本文中提出了一个新颖的两步框架。首先,训练 GAN 以估计输入噪声图像上的噪声分布并生成噪声样本。其次,利用从第一步采样的噪声块来构建成对的训练数据集,该数据集又用于训练 CNN 以对给定的噪声图像进行去噪。
网络结构
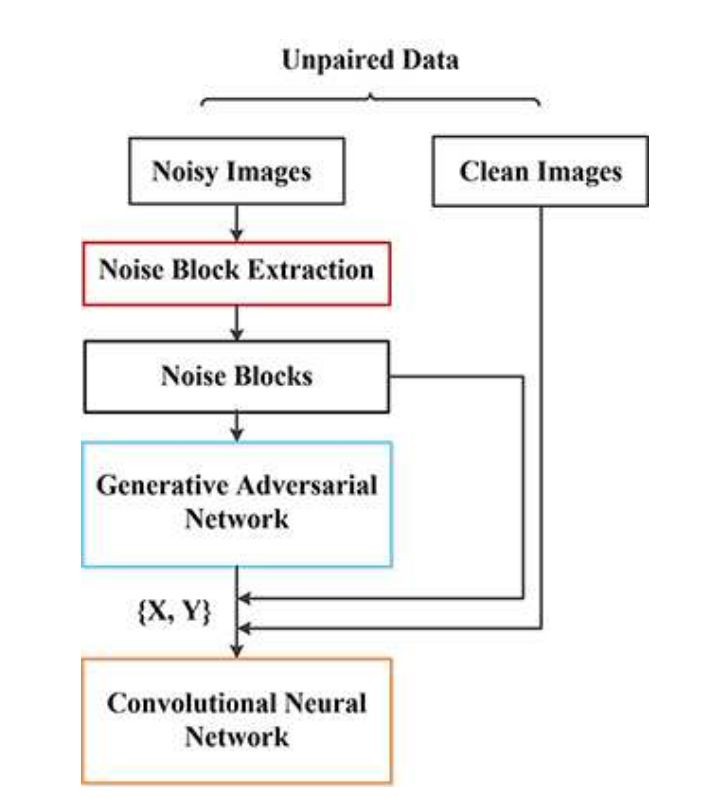
▲ GCBD方法
噪声建模估计
文章假设需要处理的图像都含有同一类型的未知的均值为 0 的噪声。然后,进行噪声建模。
1. 提取噪声图像块
这是正确训练 GAN 以模拟未知噪声的重要步骤,因为噪声分布将从噪声主导数据中更好地被估计。
为了减小原始背景的影响,需要从给定噪声图像中具有弱背景的部分中首先提取一组近似噪声块(或块),例如 V。
这样,噪声分布成为 GAN 学习的主要目标,这可能使 GAN 模型更加准确。在噪声分布的期望为零的假设下,可以通过减去噪声图像中相对平滑的 patch (smoothed patch) 的平均值来获得近似的噪声 patch。
这里讨论的 smoothed patch 指的是内部内容非常相似的区域。文中的数学定义即为 patch 中各部分的均值,方差在一个很小的范围内波动。
以步长为 Sg 对整张含噪声图像提取图像块 Pi,其大小为 d × d;
以步长为 Sl 对图像块 Pi 提取局部图像块
,其大小为 h × h;
若对于 Pi 中所有的
,都满足以下条件,就说明 Pi 为 smoothed patch,μ, γ∈(0,1)。
将每一个 smoothed patch 保存到集合 S 中,然后各自减去各自的均值,就得到 noise patch 集合 V。
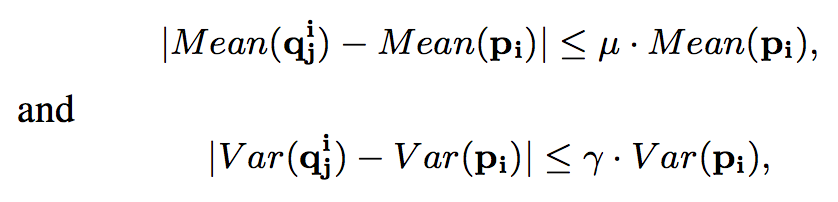
2. 利用GAN进行噪声建模
利用刚才得到的 noise patch 集合,然后用 GAN 来对噪声进行建模,通过建立的模型生成更多的噪声数据。
在文章的方法中,GAN 是通过第一部得到的近似噪声 patch 集合 V 来估计噪声的分布的。
由于 WGAN 可以改进 GAN 的训练并生成高质量的样本。因此,在文章的实验中,WGAN-GP 是 WGAN 的改进版本,用于学习噪声分布。
这里的 loss 函数为:
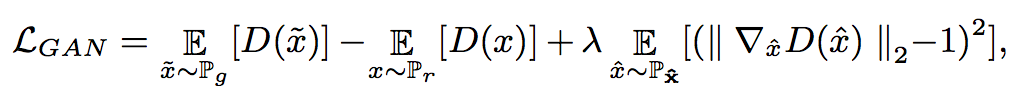
这里的 Pr 表示 V 的数据分布,Pg 是生成器生成数据的分布。被定义为沿着 Pr 和 Pg 样的点对之间的直线均匀分布的采样。
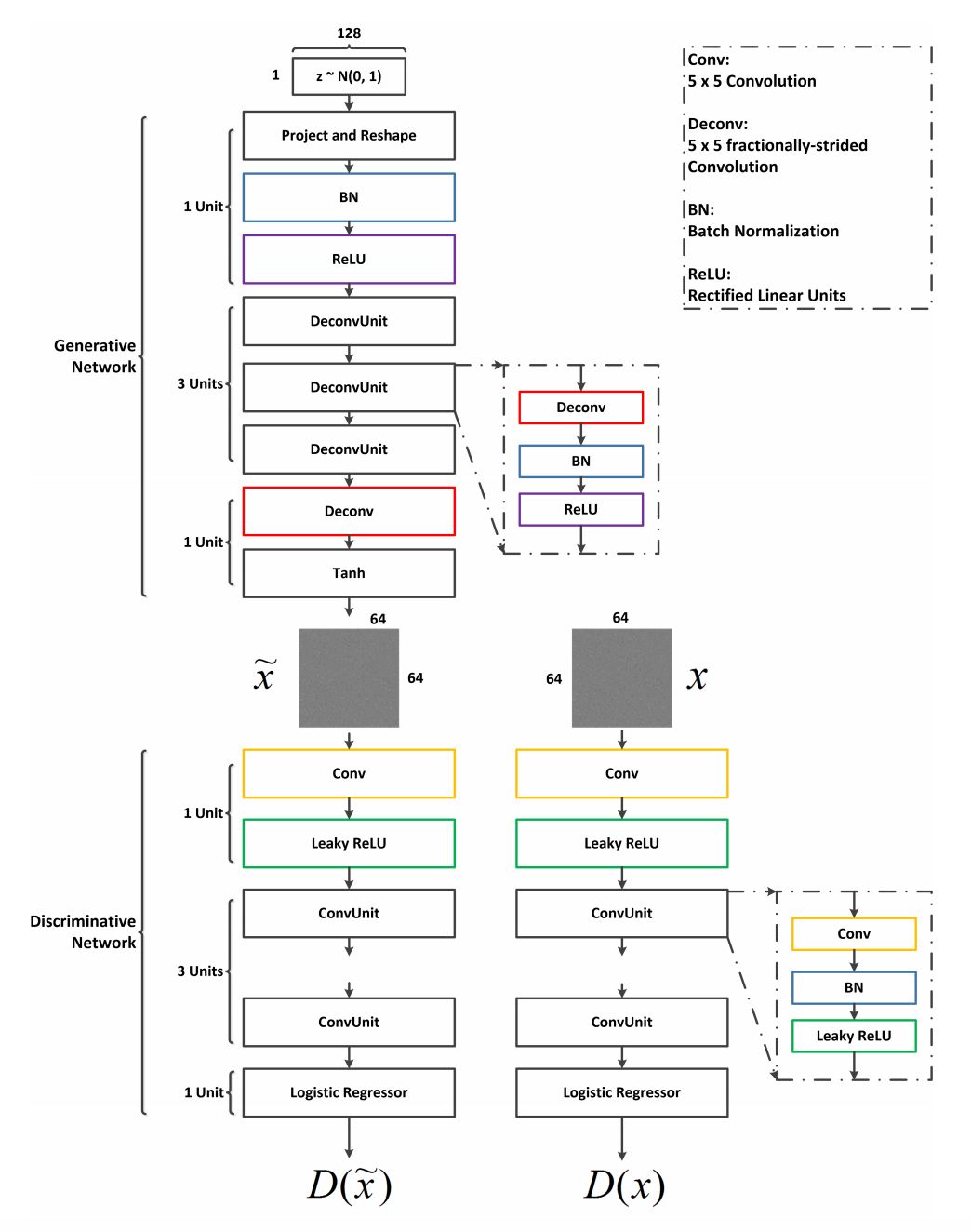
▲ GAN网络结构
作者采用类似于 DCGAN 的网络,训练好的网络被用来生成噪声样本(增强集合 V)并最终得到集合 V'。
通过深度CNN进行去噪
许多以前的工作提出通过训练具有大型数据集的 CNN 来解决去噪问题,并取得了令人瞩目的成果。如前所述,CNN 可以隐含地从配对的训练数据集中学习潜在噪声模型,从而放松了对图像先验的人类知识的依赖。因此,在文章的方法中使用 CNN 进行去噪。
为了训练 CNN,首先需要构建一个配对的训练数据集,从刚才得到的经过 GAN 扩展的 V' 数据集,然后再从干净图像的数据集中通过图像分块(patch 大小 d×d)的方法得到干净图像数据集 X。在 V' 中的 noise block 随机地加入到 X 中,得到集合 Y。其中有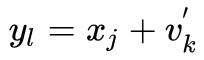
实际上,数据集是在训练去噪网络的时候构建的。在每个 epoch,xj 和的组合都会改变,然后构成一个新的配对数据集 {X,Y'} 。
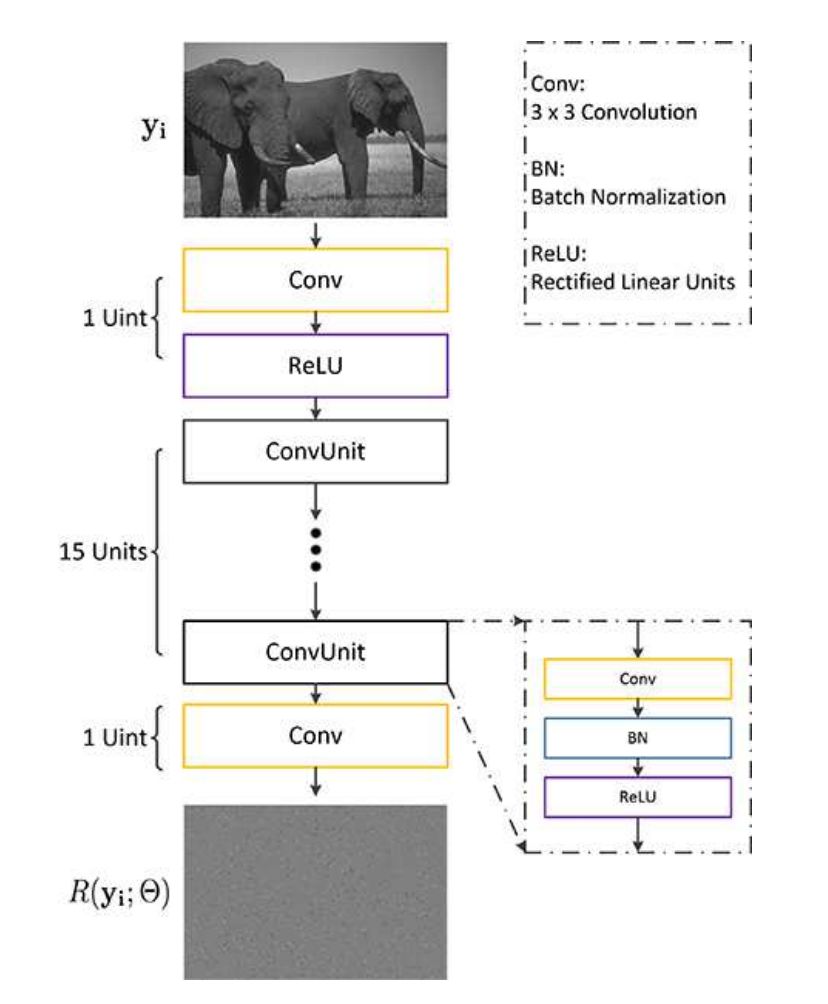
▲ 去噪网络
作者使用的网络结构类似于 DnCNN,CNN 被视为预测残留图像的残差单元,即输入噪声图像和潜在干净图像之间的差异。
损失函数为:
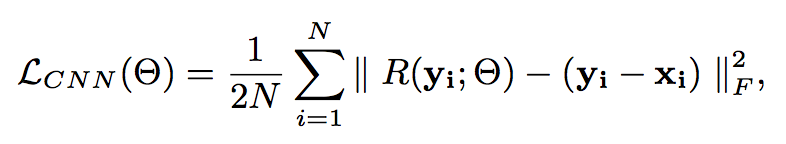
参数设定
d=64,h=32,Sg=32,Sl=16,μ=0.1,γ=0.25
GAN 的参数设定则参考的是 DCGAN 中的设定,DnCNN 则是以 lr=0.001,用 SGD 优化器训练 50 个 epoch。
相关实验
作者用合成噪声图像和真实噪声图像评估了 GCBD 方法,并对几种代表性方法进行了比较,主要分为 4 部分:
1. 验证 GAN 的噪声建模效果,GCBD 和一些 SOTA 的方法进行比较,特别是一些基于判别学习的方法(像 DnCNN),从高斯盲去噪方面进行比较;
2. GCBD 可以处理比高斯噪声更复杂的噪声,利用混合噪声进行实验;
3. 真实图像去噪实验;
4. 对噪声建模的一些讨论,说明选择 GAN 而不是传统方法(GMM)的原因。
实验数据
Test set:BSD68
真实图像:DND 数据集,NIGHT 数据集(25 张夜间高分辨率含噪声图像)
用于构建配对数据集的干净图像集:CLEAN1
为了模拟实际处理大量图像数据的情况,将噪声添加到另一组高分辨率干净图像集(CLEAN2)以在合成数据的评估中形成用于 GCBD 的输入噪声图像(测试泛化能力) 。
实验结果
1. 高斯盲去噪与合成噪声去噪
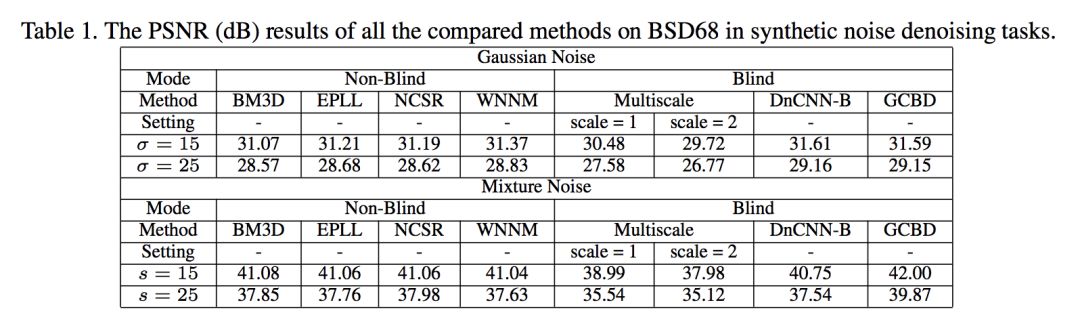
▲ 高斯盲去噪以及混合噪声去噪结果
可以看到在高斯盲去噪方面,文章提出的方法 GCBD 和 DnCNN 不相上下,而在合成噪声去噪方面,GCBD 则达到了最高水平。文中所用到的混合噪声为 10% 的均匀分布噪声(分布区间为[-s,s]),20% 的高斯噪声(N(0,1)),70%的高斯噪声(N(0,0.01)。
2. 真实图像去噪
DND数据集实验结果
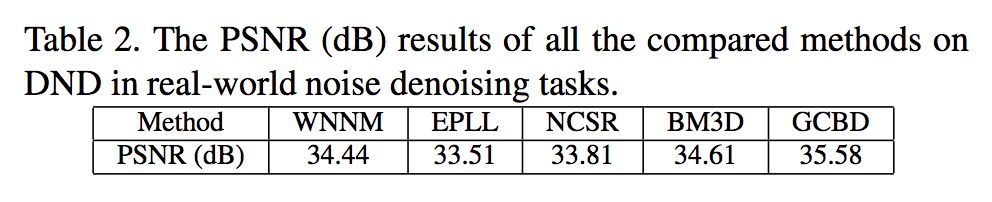
▲ 真实图像去噪结果
NIGHT数据集实验结果
因为 NIGHT 数据集没有 GT,所以之后能通过视觉效果进行衡量。

▲ NIGHT数据集实验结果
视觉效果上看,GCBD 达到了最佳的效果,在保留图像信息的情况下,去除了噪声。
3. 选择GAN而不是GMM的原因
对于真实含噪声图像而言,GMM 对噪声估计的效果并没有 GAN 好,如图所示:

▲ 噪声估计结果
可以看到利用 GAN 估计的噪声比 GMM 估计的噪声更接近与真实图像噪声。作者认为原因是 GMM 中高斯模型的数量以及显式地对噪声进行建模会限制 GMM 的估计能力,而 GAN 则是隐式地对噪声进行估计,所以效果会更好一些。
4. 利用GAN生成噪声样本的效果
作者通过实验发现利用 GAN 生成更多噪声数据的方法能提升性能(高斯盲去噪提升 0.34dB,混合噪声去噪提升 0.91dB)。作者认为原因是只对提取的噪声块直接进行训练的话,数据缺少多样性,而利用 GAN 生成更多噪声数据则弥补了这一缺陷。
总结
这篇文章针对图像盲去噪任务,通过利用 GAN 学习噪声的分布,并生成更多的噪声数据来生成训练数据集对 CNN 进行训练,得到的图像盲去噪效果达到了 SOTA 水平。

点击以下标题查看更多往期内容:

让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢? 答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 获取最新论文推荐



